天工AI发布 UniPic-2.0:轻量高效、统一多模态图像生成与编辑新范式天工AI正式推出 UniPic-2.0 系列模型,基于 SD3.5-Medium 架构与创新训练策略,在文本到图像生成、细粒度图像编辑和多模态理解任务中实现全面性能突破。 GitHub:https...图像模型# UniPic-2.0# 天工AI8个月前04130
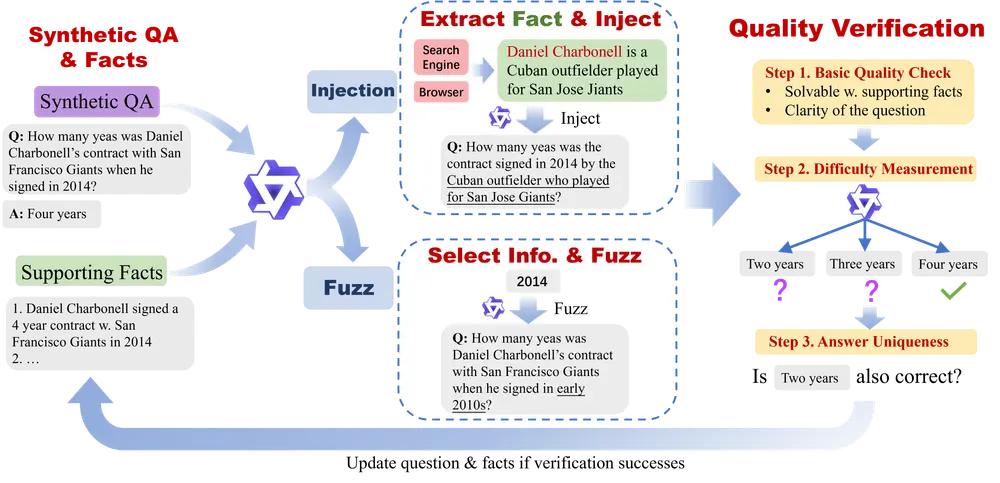
清华、蚂蚁等联合发布ASearcher:开源大规模强化学习搜索代理由清华大学交叉信息研究院、蚂蚁研究院、强化学习实验室与华盛顿大学的研究团队联合推出 ASearcher —— 一个面向大规模在线强化学习(Reinforcement Learning, RL)的开源搜...大语言模型# ASearcher# inclusionAI8个月前03940
视频处理引擎ViPE:用于从普通视频中估计相机运动、相机内参以及密集的度量深度图英伟达、多伦多大学、矢量研究所和德克萨斯大学奥斯汀分校的研究人员推出视频处理引擎ViPE(Video Pose Engine) ,用于从普通视频中估计相机运动、相机内参以及密集的度量深度图,能够从普通...视频模型# ViPE# 视频处理引擎8个月前03050
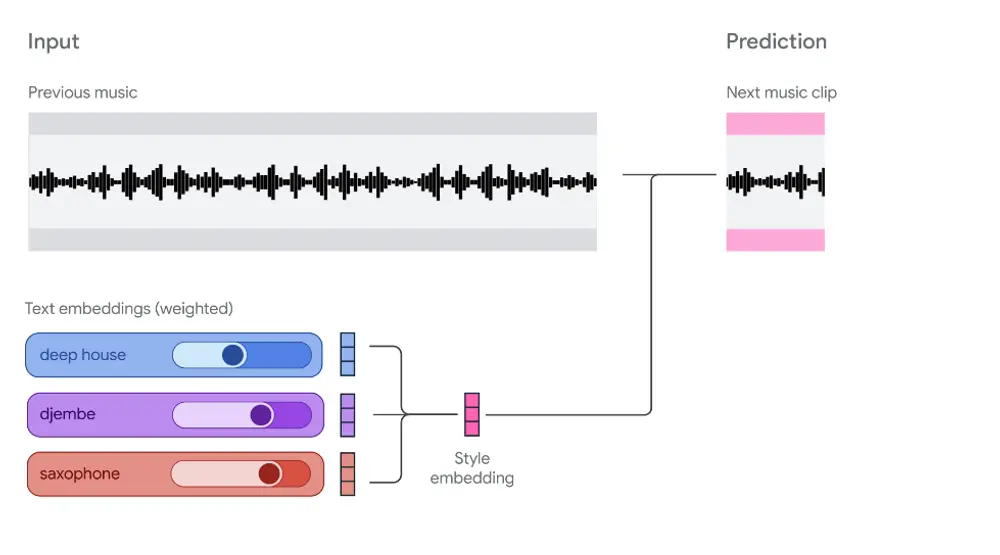
Magenta RealTime:一个可交互、可定制的开源实时音乐生成模型当 AI 生成音乐从“预设播放”走向“实时演奏”,我们正在见证创作方式的一次深刻转变。 传统的音乐生成模型通常以“批处理”模式运行:输入一段提示,等待几秒后输出完整音频。这种模式虽能产出完整作品,却缺...语音模型# Magenta RealTime# 实时音乐生成模型8个月前02050
Matrix-3D:天工AI提出全景式3D世界生成新框架从一张照片或一段文字出发,生成一个可以自由探索的3D世界——这是空间智能的核心愿景之一。近年来,基于视频扩散模型的方法在3D内容生成上取得进展,但普遍存在两大瓶颈: 视野受限:生成视角有限,难以实现全...3D模型# Matrix-3D# 天工AI8个月前03000
阿里通义实验室推出多模态深度研究智能体WebWatcher:通过结合视觉和语言推理能力,解决复杂的多模态信息检索问题阿里通义实验室推出多模态深度研究智能体WebWatcher,通过结合视觉和语言推理能力,解决复杂的多模态信息检索问题。 GitHub:https://github.com/Alibaba-NLP/We...多模态模型# WebWatcher# 多模态深度研究智能体8个月前03640
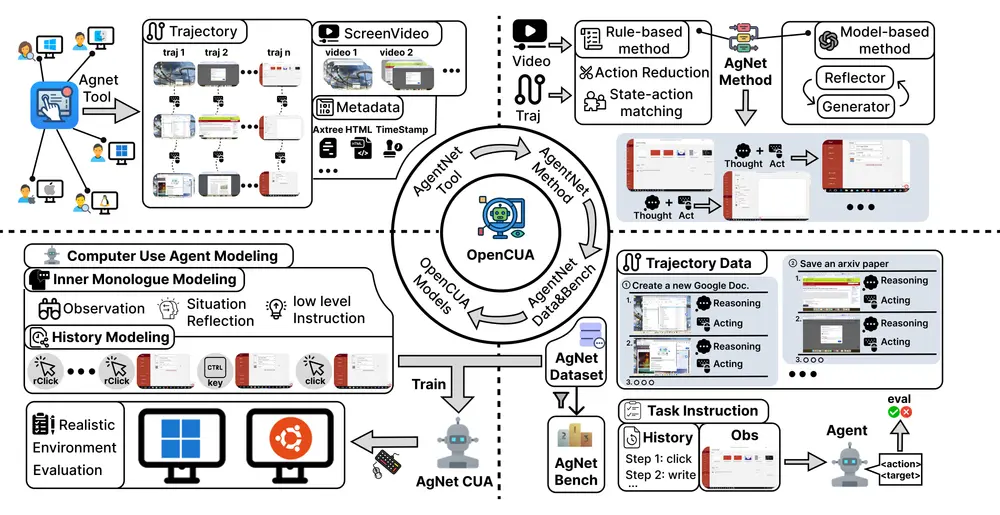
OpenCUA:首个开源的计算机使用智能体框架发布你是否曾希望有一个 AI 助手,能像你一样操作电脑——打开浏览器查资料、在 Excel 中整理数据、切换应用完成多步骤任务?如今,这类被称为“计算机使用智能体”(Computer Use Agents...多模态模型# OpenCUA# 智能体框架8个月前09620
LEGION:一个能“看懂”伪造痕迹并指导图像优化的多模态分析框架随着生成模型的飞速发展,AI 合成图像已变得越来越逼真。然而,这种进步也带来了严峻挑战:虚假内容泛滥、误导信息传播、数字信任危机加剧。 作为应对,合成图像检测技术应运而生。但当前方法普遍存在三大局限...图像模型# LEGION# 多模态分析框架8个月前01570
X-Omni:腾讯混元提出统一图像与语言生成的离散自回归新模型“能否用同一个模型,既写诗又作画?”这是多模态模型长期以来追求的目标。 近年来,研究者尝试将语言模型中成功的“下一 token 预测”范式扩展到图像领域,构建统一的离散自回归模型,期望实现图像生成与语...图像模型# X-Omni# 自回归模型8个月前02470
LFM2-VL:轻量高效、面向设备端的视觉-语言模型在多模态大模型不断追求更高参数量和更强性能的当下,效率与部署可行性正成为实际应用的关键瓶颈。许多视觉-语言模型(VLM)虽在基准测试中表现优异,但其高计算成本和长推理延迟,使其难以在手机、可穿戴设备或...多模态模型# LFM2-VL# 视觉-语言模型8个月前03880
StableAvatar:首个端到端生成无限长度虚拟人视频的扩散模型你是否曾想过,仅凭一张静态照片和一段语音,就能让照片中的人物“开口说话”,并持续数分钟自然表达?这正是音频驱动虚拟人视频生成(Audio-Driven Talking Head Generation...视频模型# StableAvatar# 虚拟人8个月前05460
上海大学联合vivo推出新型交互式图像抠图方法SDMatte:用扩散模型重新定义交互式抠图上海大学与 vivo 联合研究团队近期提出一种名为 SDMatte 的新型交互式图像抠图方法。该方法基于稳定扩散模型(Stable Diffusion),支持点、框和掩码三种视觉提示,能够从自然图像中...图像模型# SDMatte# 图像抠图8个月前05120