
“能否用同一个模型,既写诗又作画?”这是多模态模型长期以来追求的目标。
近年来,研究者尝试将语言模型中成功的“下一 token 预测”范式扩展到图像领域,构建统一的离散自回归模型,期望实现图像生成与语言生成的无缝整合。然而,这类方法在实践中面临显著挑战:
- 图像保真度低,细节模糊或失真;
- 难以准确遵循复杂指令;
- 在渲染长文本(如广告语、标语)时表现不佳;
- 自回归过程中的误差累积导致整体质量下降。
这些问题使得不少研究转向“扩散+自回归”的混合架构,牺牲了统一建模的简洁性。

腾讯混元项目组在新工作 X-Omni 中提出了一种新思路:不放弃离散自回归范式,而是通过强化学习来修复其缺陷。结果表明,这一路径不仅能大幅提升生成质量,还能在图像与语言任务之间实现真正的统一建模。
- 项目主页:https://x-omni-team.github.io
- GitHub:https://github.com/X-Omni-Team/X-Omni
- 模型:https://huggingface.co/collections/X-Omni/x-omni-models-6888aadcc54baad7997d7982
- Demo:https://huggingface.co/collections/X-Omni/x-omni-spaces-6888c64f38446f1efc402de7
核心思想:用强化学习“校正”自回归生成
X-Omni 的核心突破在于,它认识到:离散自回归模型的性能瓶颈,不在于结构本身,而在于训练目标的局限性。
传统的最大似然估计(MLE)仅要求模型“预测正确下一个 token”,但无法全局优化生成结果的视觉质量、语义一致性或指令对齐程度。
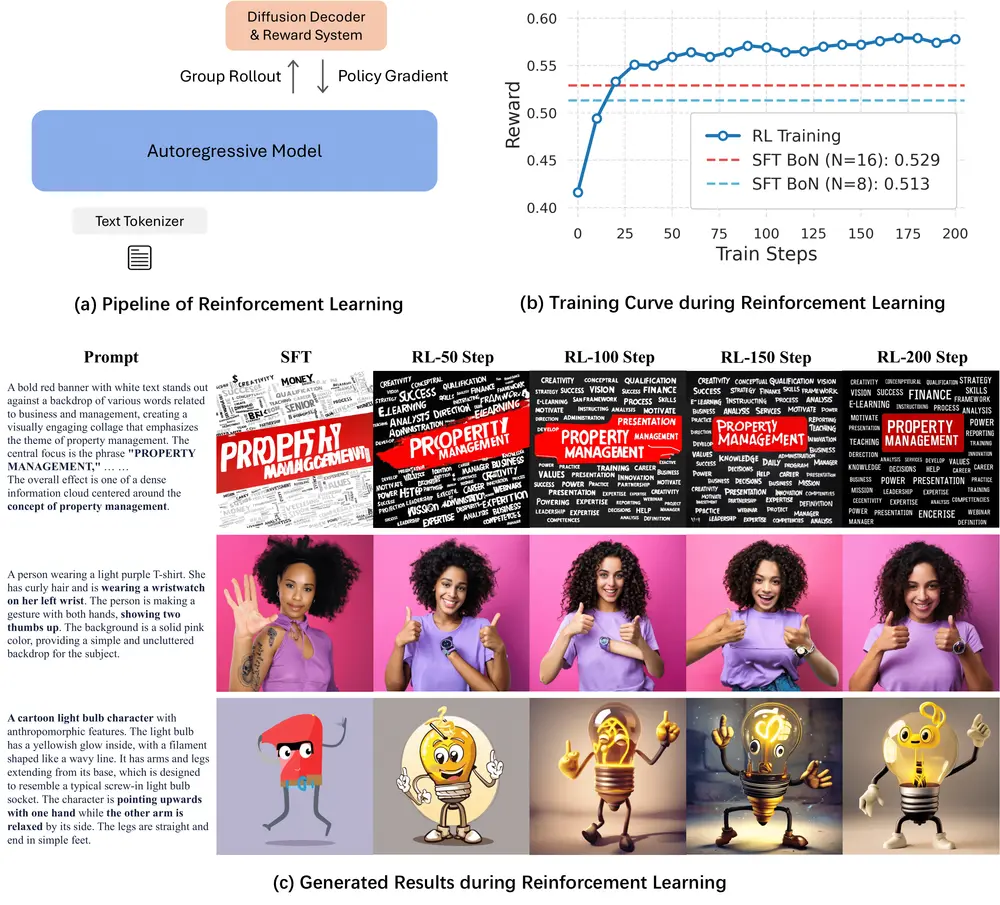
为此,X-Omni 引入基于强化学习的优化阶段,使用 GRPO(Group Relative Policy Optimization)算法,结合设计好的奖励模型,对生成过程进行端到端校正:
- 奖励信号来自图像质量(如 CLIP Score)、文本准确性(OCR 匹配度)、指令遵循程度等;
- 模型在推理过程中逐步调整 token 生成策略,减少累积误差;
- 整个过程无需额外标注数据,可在预训练基础上直接优化。
这相当于让模型从“机械地拼接 token”转变为“有目的地创作图像”。
系统架构:三部分协同工作
X-Omni 由三个关键组件构成,形成“编码—生成—解码”的完整链条:
1. 语义图像 Tokenizer:SigLIP-VQ
传统 VQ-VAE 类 tokenizer 往往丢失高层语义。X-Omni 采用 SigLIP-VQ,基于 SigLIP 视觉编码器构建:
- 将图像映射为离散 token 序列;
- 每个 token 不仅编码局部像素,还携带语义信息(如物体类别、风格);
- 支持高保真重建,减少离散化带来的信息损失。
2. 统一自回归模型:语言与图像共用一个骨干
X-Omni 使用一个 7B 参数的统一 Transformer 模型,同时处理语言 token 和图像 token:
- 所有 token 混合排列,模型学习跨模态上下文依赖;
- 支持双向任务:给文本生成图像,或给图像生成描述;
- 在预训练阶段融合图像描述、图文匹配、视觉问答等任务,提升理解能力。
这种设计实现了真正意义上的“模态无感”建模。
3. 离线扩散解码器:提升最终输出质量
虽然生成的是离散 token,但最终图像仍需高质量还原。X-Omni 采用一个预训练的扩散模型作为解码器:
- 输入为 tokenizer 生成的 latent code;
- 扩散过程负责细节补全与纹理增强;
- 解码器固定不动,不参与训练,仅用于推理阶段提升视觉保真度。
这一设计既保留了自回归的统一性,又借力扩散模型的生成优势。
关键特性
| 特性 | 说明 |
|---|---|
| 强化学习优化 | 使用 GRPO 算法优化生成策略,显著提升指令遵循与视觉质量 |
| 长文本渲染能力 | 可在图像中准确生成多行中英文文本(如广告标语),优于现有方法 |
| 复杂指令理解 | 能解析“穿红色外套的女性在雨中撑伞”等复合语义提示 |
| 无需 CFG 引导 | 不依赖分类器自由引导(Classifier-Free Guidance),降低推理成本,提升一致性 |
| 多任务兼容 | 支持图像生成、图像描述、视觉问答、OCR 等多种任务 |
工作流程简述
- 输入处理:文本提示被分词,图像被 SigLIP-VQ 编码为离散 token 序列;
- 自回归生成:统一模型按顺序预测后续 token,可生成图像 token 或语言响应;
- 强化学习优化:在推理阶段引入奖励模型,动态调整生成路径;
- 扩散解码:图像 token 被送入离线扩散解码器,生成高分辨率像素图像;
- 输出呈现:返回高质量图像或图文混合输出。
整个流程支持端到端推理,且生成过程完全自回归。
实验表现:全面领先
X-Omni 在多个权威基准上进行了评估:
1. 文本渲染能力
- OneIG-Bench:在长文本图像生成任务中显著优于 Unified-IO、PaLI-X 等模型;
- LongText-Bench:中文长文本渲染准确率提升 15% 以上,能完整保留“欢迎来到家居美学盛典”等复杂文案。
2. 图像生成质量
- DPG-Bench 和 GenEval:在复杂指令遵循、构图合理性、细节保真度等维度达到 SOTA;
- 示例:生成“穿汉服的女孩在樱花树下弹古筝”时,服饰纹理、乐器结构、背景层次均清晰可辨。
3. 图像理解能力
- 在 OCRBench 上,X-Omni 的文本识别准确率超过多数专用模型;
- 在 VQA 任务中表现与主流多模态模型相当,证明其具备双向能力。
值得一提的是,X-Omni 在不使用 CFG 的情况下实现高质量生成,相比依赖强引导的方法,推理更稳定、资源消耗更低。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











