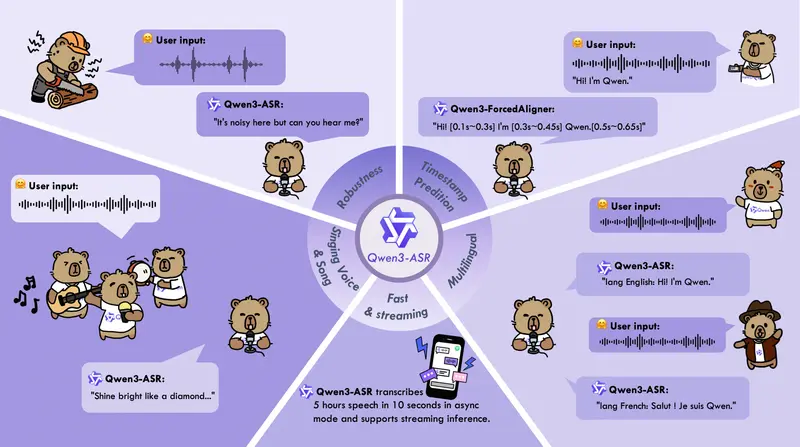
通义千问开源 Qwen3-ASR 与 Qwen3-ForcedAligner:支持流式、多语言、高并发的语音识别与对齐工具Qwen(通义千问)团队正式开源全新一代语音技术方案——Qwen3-ASR系列语音识别模型与Qwen3-ForcedAligner强制对齐模型。该系列包含Qwen3-ASR-1.7B、Qwen3-AS...语音模型# Qwen# Qwen3-ASR# Qwen3-ForcedAligner2个月前0870
Gemini 3 Flash 引入智能体视觉:视觉推理+代码执行,答案基于视觉证据谷歌正式为 Gemini 3 Flash 推出全新能力——智能体视觉,通过将视觉推理与代码执行深度结合,让AI从“静态一瞥”升级为“主动调查”,彻底改变图像理解方式。这项功能可使多数视觉基准测试质量提...多模态模型# Gemini 3 Flash# 智能体视觉2个月前0450
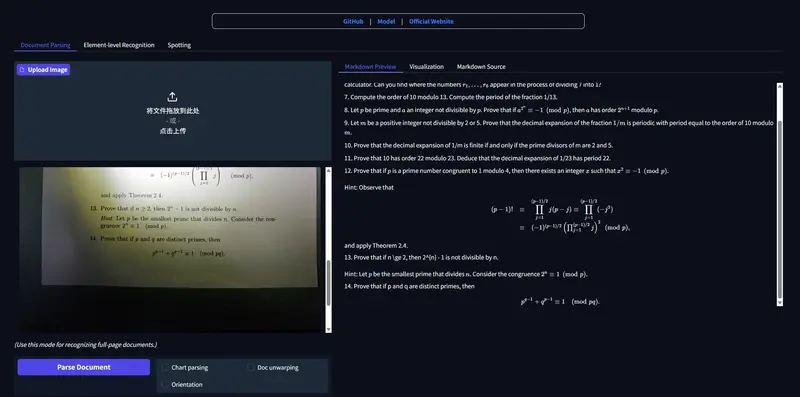
百度飞桨发布PaddleOCR-VL-1.5:0.9B轻量多模态模型,真实场景文档解析全面SOTA百度飞桨近期完成 PaddleOCR 3.4.0 版本更新,正式推出新一代视觉语言模型 PaddleOCR-VL-1.5。这款面向真实场景的文档解析专用模型,仅0.9B参数量却实现资源高效与性能领先...多模态模型# PaddleOCR-VL-1.5# 百度飞桨2个月前01040
腾讯混元推出 HunyuanImage 3.0-Instruct:原生多模态图像编辑模型,支持精准编辑与多图融合腾讯混元项目组正式开源 HunyuanImage 3.0-Instruct —— 一款专注于图像编辑的原生多模态大模型。该模型不仅能理解输入图像的语义内容,还能基于复杂指令进行推理,并生成高保真、高一...图像模型# HunyuanImage 3.0-Instruct# 多模态图像编辑模型2个月前0360
LingBot-World:蚂蚁灵波开源交互式世界模拟器,支持高保真、长时序、可交互的虚拟环境生成蚂蚁灵波科技正式开源 LingBot-World —— 一个基于视频生成技术构建的交互式世界模拟器。它不是简单的视频合成工具,而是一个能响应用户动作、维持物理逻辑、保持长期一致性的动态虚拟世界框架。项...世界模型# LingBot-World# 蚂蚁灵波2个月前02950
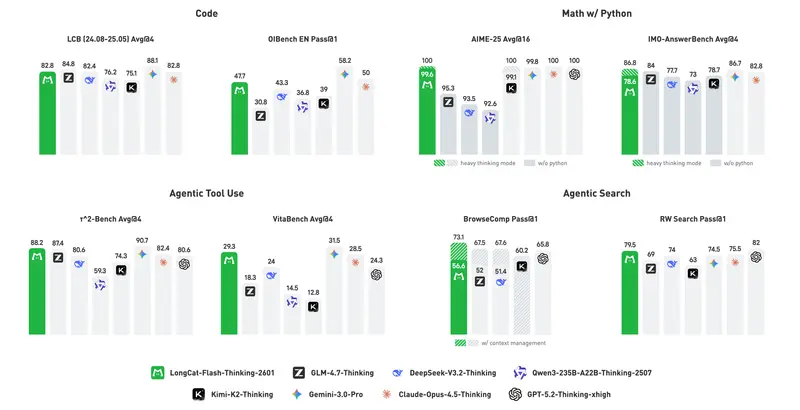
美团 LongCat 团队发布 LongCat-Flash-Thinking-2601:5600 亿参数智能体推理模型,支持深度思考与抗噪泛化美团 LongCat 团队正式推出 LongCat-Flash-Thinking-2601 —— 一款总参数量达 5600 亿、激活参数仅 270 亿 的高效混合专家(MoE)大模型。该模型专为现实世...大语言模型# LongCat# LongCat-Flash-Thinking-2601# 美团2个月前01240
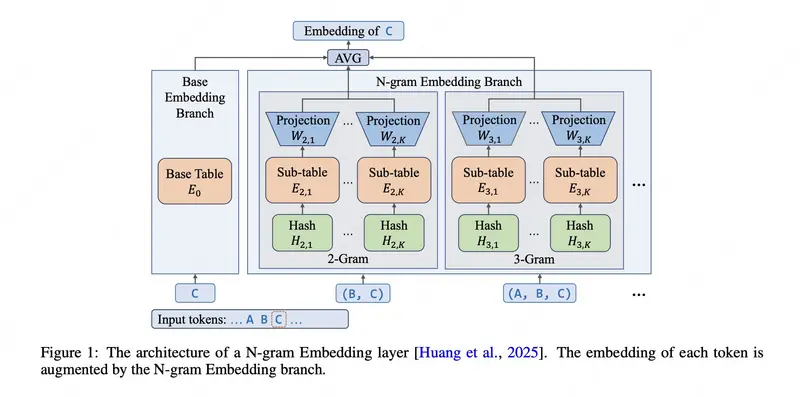
美团 LongCat 团队发布 LongCat-Flash-Lite:685 亿参数 MoE 模型,用 N-gram 嵌入表突破推理效率瓶颈美团 LongCat 团队近日开源了 LongCat-Flash-Lite —— 一款拥有 685 亿总参数、激活参数约 30 亿 的混合专家(MoE)语言模型。它基于 LongCat-Flash 架...大语言模型# LongCat# LongCat-Flash-Lite# 美团2个月前01080
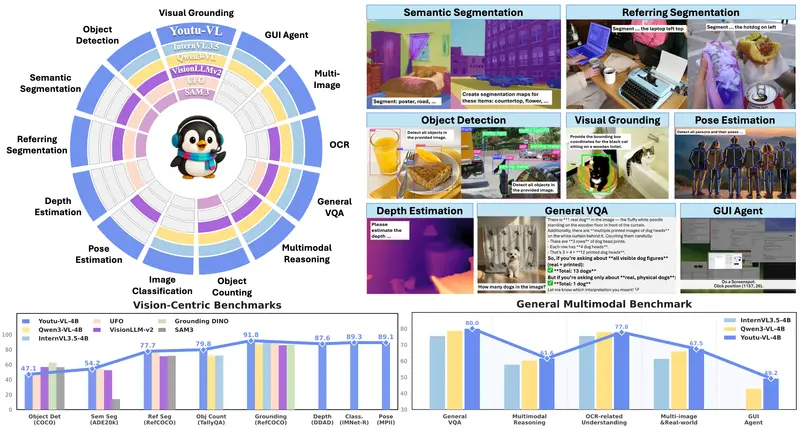
腾讯优图发布 Youtu-VL:40 亿参数轻量模型,统一处理视觉与语言任务腾讯优图实验室近日开源了 Youtu-VL——一款仅有 40 亿参数 的轻量级视觉语言模型(VLM),却能在无需任务专用模块的前提下,同时胜任通用多模态任务与高难度的以视觉为中心的任务(如图像分割、深...多模态模型# Youtu-VL2个月前01500
阿里DiffSynth-Studio 项目组推出Z-Image-i2L:从单张图像一键生成风格 LoRA阿里 DiffSynth-Studio 项目组 推出 Z-Image-i2L(Image to LoRA)模型——一种“以图生 LoRA”的创新方案。只需输入一张或多张风格统一的图像,模型即可自动生成...图像模型# DiffSynth-Studio# Z-Image-i2L2个月前01730
AI2发布Open Coding Agents:低成本、可复现的开源编程智能体,支持任意私有代码库过去一年,编程智能体(Coding Agents)显著改变了软件开发流程——从自动调试、重构到提交 PR,它们正逐步成为开发者的新“协作者”。然而,主流系统多为闭源、训练成本高昂,且难以适配私有代码库...大语言模型# Ai2# Open Coding Agents# 编程智能体2个月前0910
阿里通义 MAX 项目组发布 Z-Image :支持 CFG 与微调,面向专业创作的非蒸馏基础模型在用户热切期盼下,阿里通义 MAX 项目组正式开源 Z-Image 完整版——这是 Z-Image 系列的基础大模型,专为追求最高生成质量、最大创作自由度与最强提示控制力的专业用户设计。 Huggin...图像模型# Z-Image# 通义 MAX2个月前0380
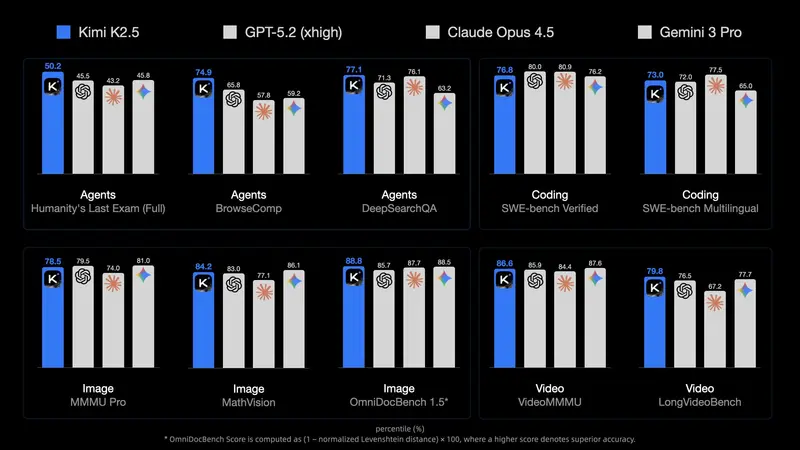
月之暗面开源最强多模态模型 Kimi K2.5,支持百智能体协同与视觉编程月之暗面(Moonshot AI)正式发布 Kimi K2.5——目前最强的开源多模态大模型。它在 Kimi K2 基础上,基于约 15 万亿混合视觉-文本 Token 进行预训练,不仅在编码与视觉理...多模态模型# Kimi K2.5# 月之暗面2个月前0270