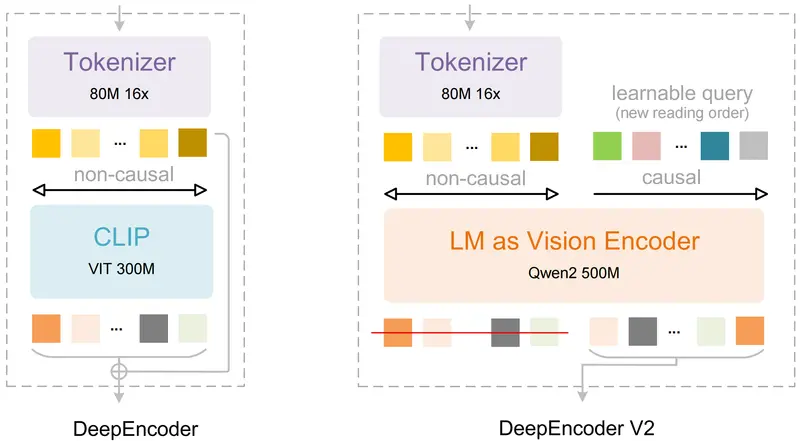
DeepSeek-OCR-V2:用 LLM 替代 CLIP,让 OCR 学会“像人一样阅读”DeepSeek 发布 OCR-V2,这不是一次常规升级,而是一次架构级革新:彻底弃用 CLIP 视觉编码器,改用小型 LLM(Qwen2-0.5B)作为视觉编码器,并引入 “视觉因果流”(Visua...多模态模型# DeepSeek-OCR-V2# OCR模型2个月前0630
阿里通义实验室推出新一代旗舰推理模型Qwen3-Max-Thinking:支持自适应工具调用,性能对标 GPT-5.2阿里通义实验室正式发布 Qwen3-Max-Thinking,作为 Qwen 系列的最新旗舰推理模型。通过显著扩大参数规模并投入大量强化学习训练算力,该模型在事实准确性、复杂推理、指令遵循、人类偏好对...大语言模型# Qwen3-Max-Thinking# 推理模型2个月前0760
天气 AI 革命!英伟达发布 Earth-2 开放模型:0-6 小时预警 + 15 天预报,主权国家可自托管美国冬季风暴来袭前,多地降雪量预测差出“天壤之别”——有的说下5厘米,有的说下20厘米,气象部门和民众都陷入纠结。 在 2026 年 1 月于休斯敦举行的美国气象学会(AMS)年会上,英伟达正式发布了...世界模型# Earth-2# 英伟达2个月前0510
Odyssey 推出交互式世界模型Odyssey-2 Pro,支持实时模拟与多端集成今天,Odyssey 正式推出 Odyssey-2 Pro——目前最强大的通用世界模型——以及配套的 开发者 API。Odyssey表示,这标志着世界模型领域迎来了自己的 “GPT-2 时刻”:一个可...世界模型# Odyssey# Odyssey-2 Pro# 世界模型2个月前01240
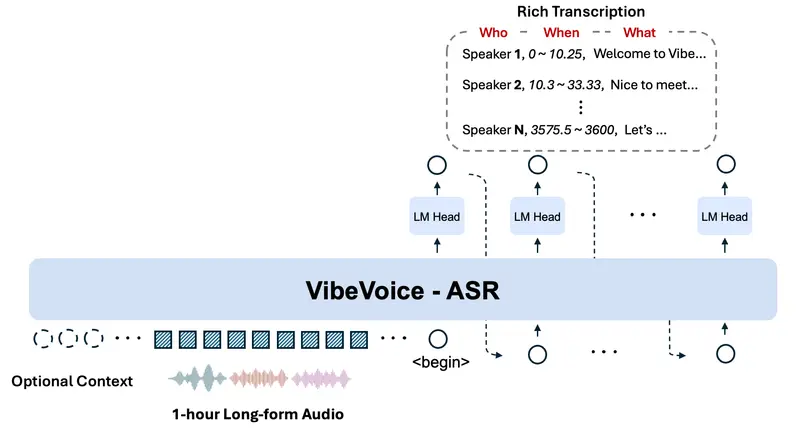
微软开源 VibeVoice-ASR:支持60分钟长音频的端到端语音转写模型微软正式开源 VibeVoice-ASR——一款面向真实场景的统一语音识别模型。它能单次处理长达60分钟的连续音频,并输出包含说话人身份、精确时间戳与文本内容的结构化转录结果,同时支持用户注入自定义热...语音模型# VibeVoice-ASR# 微软2个月前0250
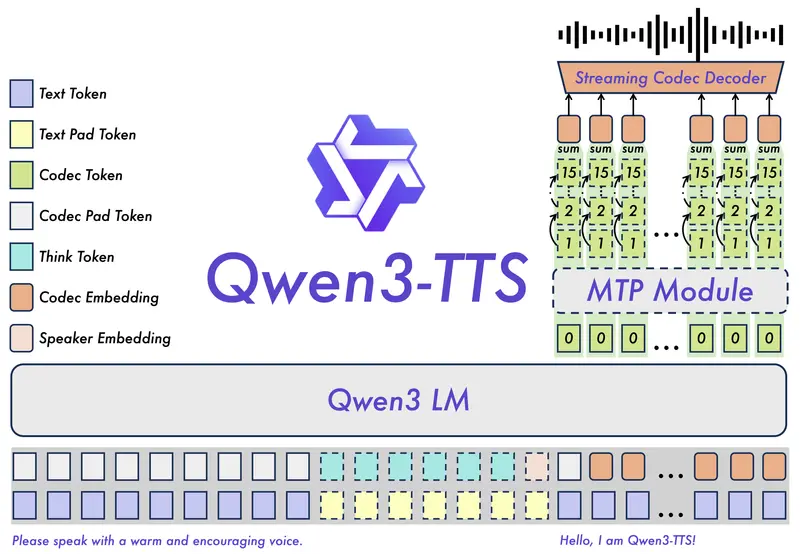
Qwen3-TTS 全家桶开源:支持音色克隆、创造与多语言拟人语音在语音生成技术快速迭代的当下,开发者与用户对高保真、可定制、低延迟的语音合成方案需求日益迫切。阿里Qwen项目组推出的 Qwen3-TTS 开源全家桶,凭借音色克隆、音色创造、拟人化语音生成与自然语言...语音模型# Qwen3-TTS# 阿里3个月前01260
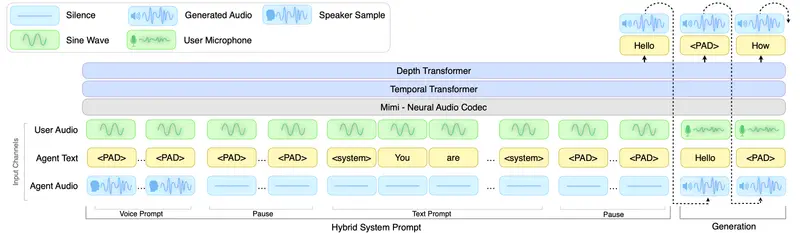
英伟达推出实时语音对话模型PersonaPlex,打造支持自定义角色与声音的自然对话AI长期以来,语音对话 AI 面临一个根本性矛盾: 传统级联系统(ASR → LLM → TTS)允许你自定义角色和声音,但对话僵硬、延迟高、无法被打断; 全双工模型(如 Moshi)实现了自然的话轮转换...语音模型# PersonaPlex# 实时语音对话模型# 英伟达3个月前0340
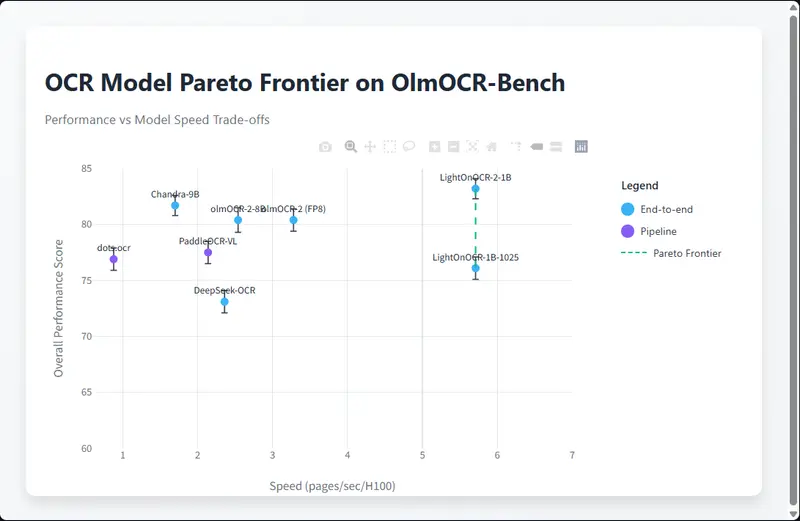
LightOn AI推出的第二代模型 LightOnOCR-2-1B:1B 参数端到端 OCR 模型,支持边界框输出在文档数字化处理领域,兼顾高精度转录、轻量化部署、高效推理的OCR模型一直是行业刚需。LightOn AI推出的第二代模型 LightOnOCR-2-1B,以1B参数量实现端到端PDF文档转写能力,不...多模态模型# LightOn AI# LightOnOCR-2-1B# OCR 模型3个月前01230
FlashLabs推出Chroma 1.0:首个开源实时语音对话模型,支持低延迟个性化语音克隆在虚拟人交互与语音合成领域,兼顾低延迟、高保真语音克隆、多轮对话理解的模型一直是技术难点。由FlashLabs开发的 Chroma 1.0 正是一款突破性的多模态因果语言模型,它不仅能直接处理音频输入...语音模型# Chroma# FlashLabs# 实时语音对话模型3个月前05110
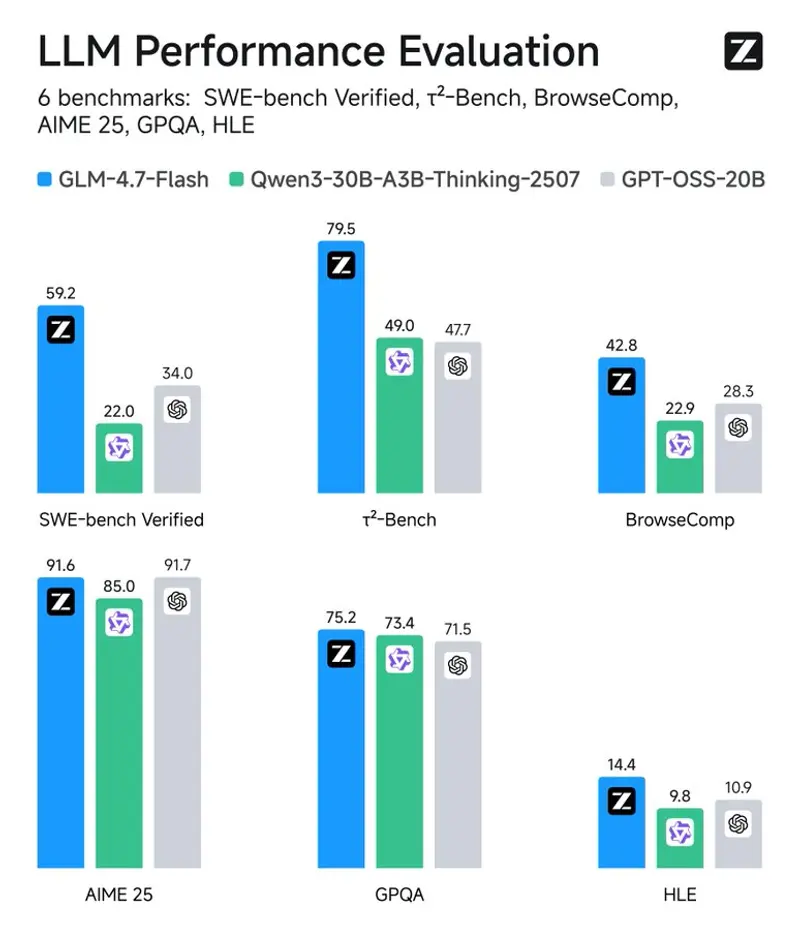
智谱发布 GLM-4.7-Flash:30B 级 MoE 模型,本地部署首选编码与代理助手智谱 AI 正式推出 GLM-4.7-Flash——一款基于 30B 总参数、激活 3B(A3B)的稀疏混合专家(MoE)架构 的大语言模型。它在高性能与高效率之间取得出色平衡,成为本地部署场景下理想...大语言模型# GLM-4.7-Flash# 智谱3个月前0510
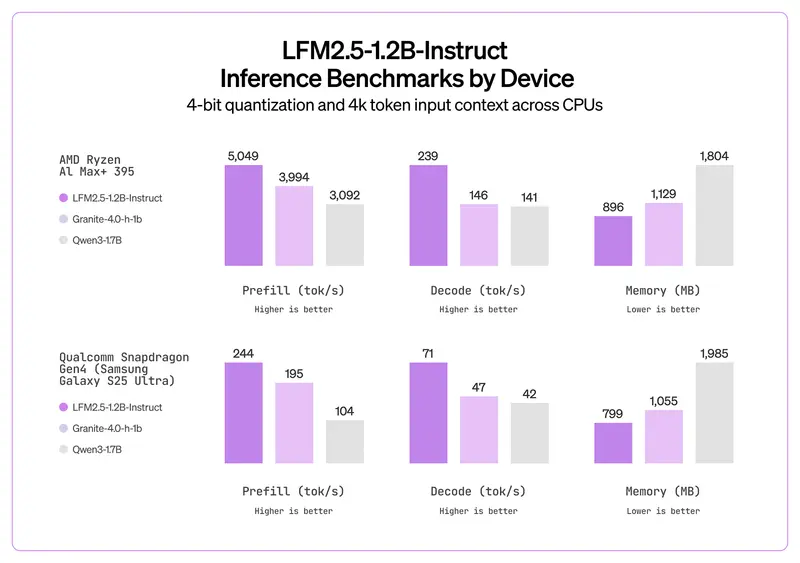
Liquid AI发布LFM2.5系列模型:新一代设备端AI,开放权重+多模态+边缘高效部署Liquid AI 正式推出 LFM2.5 系列模型,这是该团队针对边缘 AI 部署打造的新一代旗舰产品,基于 LFM2 设备优化架构升级而来,实现了 1B 级模型能力边界的重大突破。此次发布覆盖基础...大语言模型# LFM2.5# Liquid AI3个月前0280
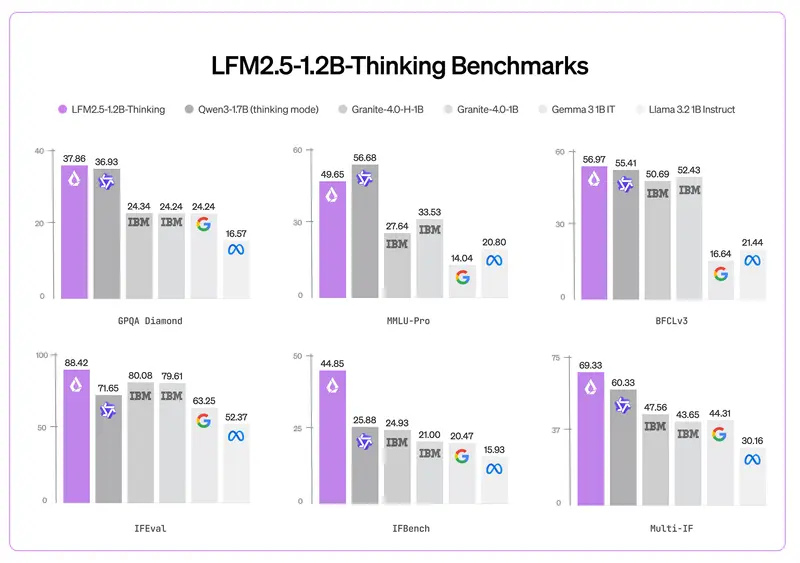
Liquid AI 发布 LFM2.5-1.2B-Thinking:900MB 内存即可运行的设备端推理模型两年前,复杂的推理任务还需要依赖数据中心。如今,Liquid AI 发布的 LFM2.5-1.2B-Thinking 模型,让这一切在任何拥有 900MB 可用内存的手机上成为可能。 地址:https...大语言模型# LFM2.5-1.2B-Thinking# Liquid AI3个月前0440