Stable Video Infinity(SVI)发布 2.0 Pro:基于错误回收机制的无限长视频生成模型洛桑联邦理工学院(EPFL)的研究团队推出 Stable Video Infinity(SVI) ——一款能够生成任意长度视频的人工智能模型。它通过一项名为 “错误回收微调(Error-Recycli...视频模型# Stable Video Infinity3个月前01450
StoryMem:基于Wan2.2的新框架,用“视觉记忆”生成连贯的多镜头长视频生成一段包含多个镜头、角色一致、场景连贯、时长达一分钟的叙事视频,是当前视频生成模型的重大挑战。主流方法要么局限于单镜头,要么在跨镜头切换时出现角色崩坏、场景断裂等问题。 由南洋理工大学与字节跳动联合...视频模型# StoryMem# Wan2.23个月前0850
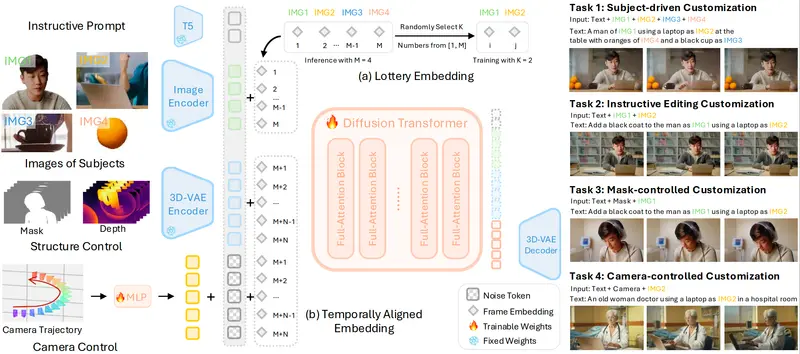
OmniVCus:用多模态控制信号实现前馈式主题驱动视频定制在视频生成领域,一个长期挑战是:如何让用户通过简单指令(如文本、草图或相机轨迹),灵活定制视频中一个或多个主体的外观、动作与空间关系? 由约翰·霍普金斯大学、Adobe 研究院、香港大学、香港中文大学...视频模型# OmniVCus# 视频3个月前0290
TurboDiffusion:视频扩散模型提速 100–200 倍,质量几乎无损视频扩散模型虽能生成高质量内容,但其缓慢的推理速度长期制约实际应用。近日,清华大学、生数科技与加州大学伯克利分校联合提出 TurboDiffusion——一个端到端视频生成加速框架,在单张 RTX 5...视频模型# TurboDiffusion# Wan2.24个月前0330
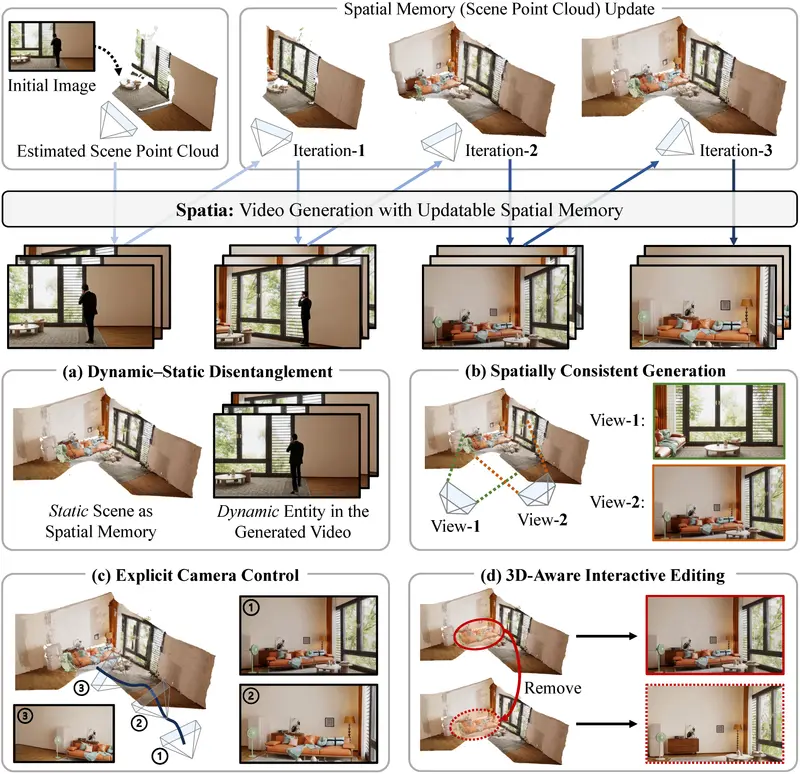
Spatia:基于可更新空间记忆的长期一致视频生成框架传统视频生成模型在生成长视频时,常因高维时空信号的复杂性而难以维持长期的空间与时间一致性——场景结构漂移、物体位置突变、相机运动不连贯等问题普遍存在。 项目主页:https://zhaojingjin...视频模型# Spatia# 视频生成4个月前0330
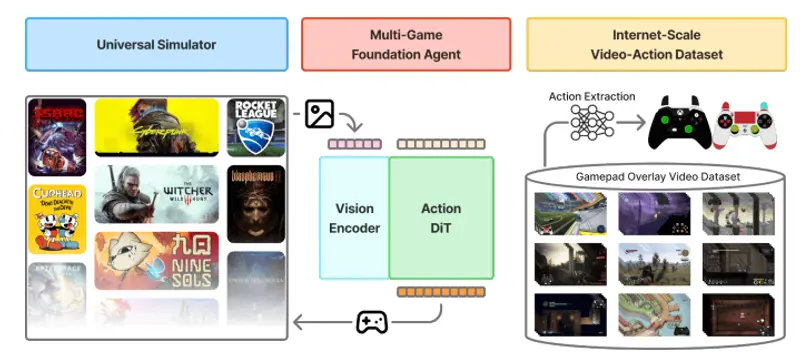
英伟达推出NitroGen:基于人类游戏视频的通用视觉-动作基础模型NitroGen 是由英伟达开发的开放性具身智能基础模型(foundation model for embodied agents),旨在通过观察人类玩家的游戏视频,直接学习从原始画面到手柄动作的映射...视频模型# NitroGen# 英伟达4个月前0860
FlashPortrait:端到端生成无限长度肖像动画,6倍加速且身份一致在肖像动画(Portrait Animation)任务中,身份一致性与推理效率是两大长期瓶颈。现有扩散模型即便能生成逼真短片,也常在长序列中出现身份漂移、颜色偏移或动作断裂,且生成速度慢,难以用于实际...视频模型# FlashPortrait# 肖像动画4个月前0990
美团 LongCat 发布统一音频驱动视频模型LongCat-Video-Avatar:支持长视频、多模态输入与多人物动画音频驱动的人类视频合成(Audio-Driven Talking Head)近年来在唇形同步和画面逼真度上取得显著进展。但生成长时间、高动态、身份一致的视频仍是行业难题:现有方法要么在长序列中出现身份...视频模型# LongCat-Video-Avatar# 美团4个月前0570
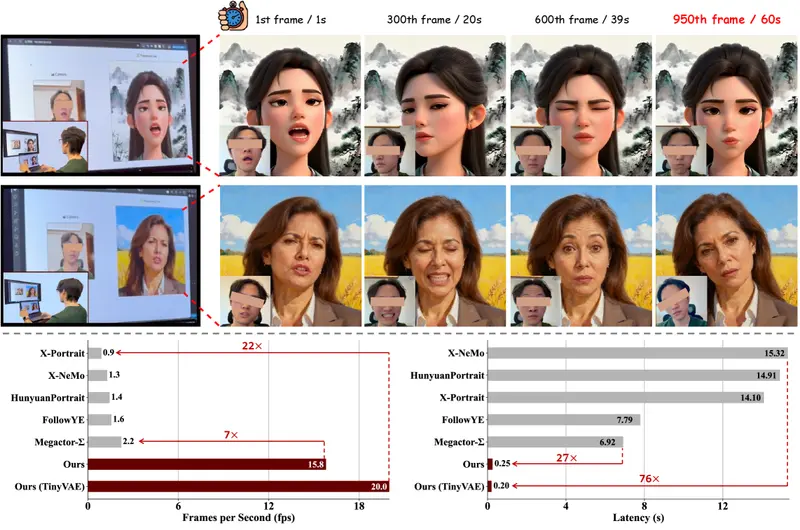
PersonaLive:基于扩散模型的实时肖像动画系统,延迟仅0.25秒在数字人、虚拟主播和直播场景中,高质量、低延迟、身份一致的肖像动画是核心需求。然而,主流扩散模型虽能生成逼真画面,却因高计算成本与多步去噪,难以满足实时交互要求——生成一段3秒视频往往需要数十秒,远不...视频模型# PersonaLive# 肖像动画4个月前0220
MoLingo:通过语义对齐潜在空间实现高保真文本到动作生成在虚拟角色动画、VR/AR交互和智能体控制中,如何让AI根据一句自然语言(如“一个人正在跳华尔兹”)生成逼真、连贯且语义一致的人体动作,一直是核心挑战。传统方法要么动作生硬,要么与文本描述脱节,难以兼...视频模型# MoLingo# 动作生成4个月前01140
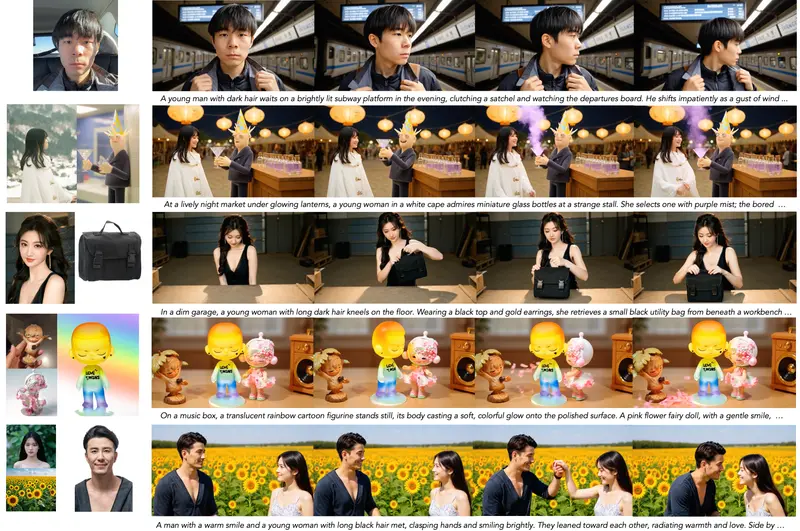
智谱AI发布 Kaleido:通过多参考图像生成主体一致视频的 S2V 框架在主体到视频(Subject-to-Video, S2V)生成任务中,目标是根据用户提供的多张目标主体参考图像和文本提示,合成一段主体身份一致、动作自然、背景可控的视频。尽管近期 S2V 模型取得进展...视频模型# Kaleido# 智谱AI4个月前0700
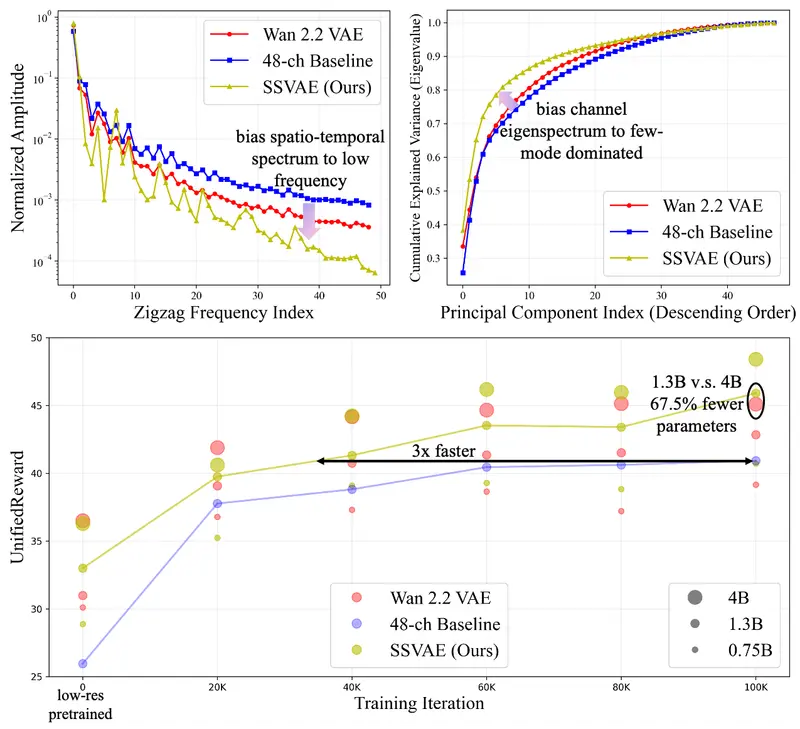
智谱AI提出 SSVAE:通过谱结构优化提升视频VAE“可扩散性”的新方法在基于扩散模型的视频生成系统中,视频变分自编码器(VAE) 扮演着关键角色:它将像素空间视频压缩到潜在空间,供扩散模型高效训练。然而,现有视频 VAE 的设计往往过度聚焦于重建保真度,却忽视了一个更根...视频模型# SSVAE# 智谱AI4个月前0210