LoRA-Edit:首帧引导+掩膜控制,实现高质量视频编辑的新方法在视频生成与编辑领域,如何在保持整体一致性的同时实现灵活可控的局部修改,一直是一个挑战。近日,来自香港中文大学与商汤研究院的研究团队提出了一种新型视频编辑方法——LoRA-Edit,该方法基于掩膜感知...视频模型# LoRA-Edit# 视频编辑10个月前03090
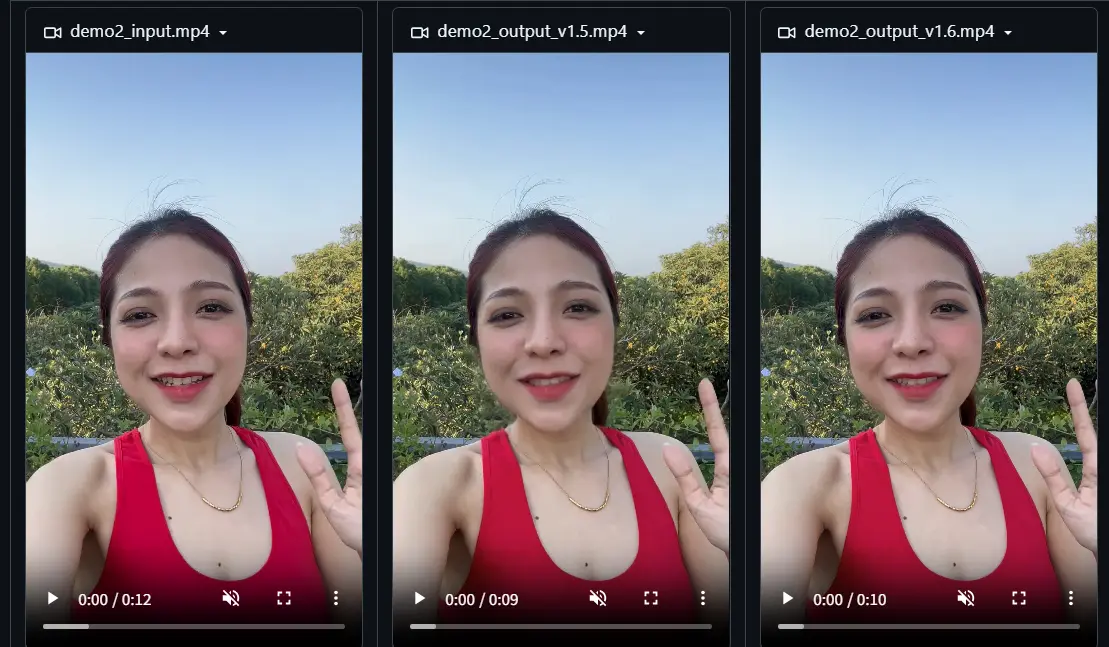
字节跳动发布 LatentSync 1.6:聚焦高分辨率视频生成,解决模糊问题字节跳动发布了其对口型视频生成模型 LatentSync 的新版本 1.6,重点解决了此前版本中生成牙齿和嘴唇区域模糊的问题。 模型:https://huggingface.co/ByteDance...视频模型# LatentSync 1.6# 字节跳动10个月前03300
字节跳动发布Seaweed APT2:专为实时交互式场景设计的流式视频生成模型字节跳动研究团队推出了Seaweed APT2,一款专为实时交互式场景设计的流式视频生成模型。该模型能够在单块H100 GPU上实现每秒24帧、分辨率高达736x416(等效640x480)的不间断视...视频模型# Seaweed APT2# 字节跳动10个月前02710
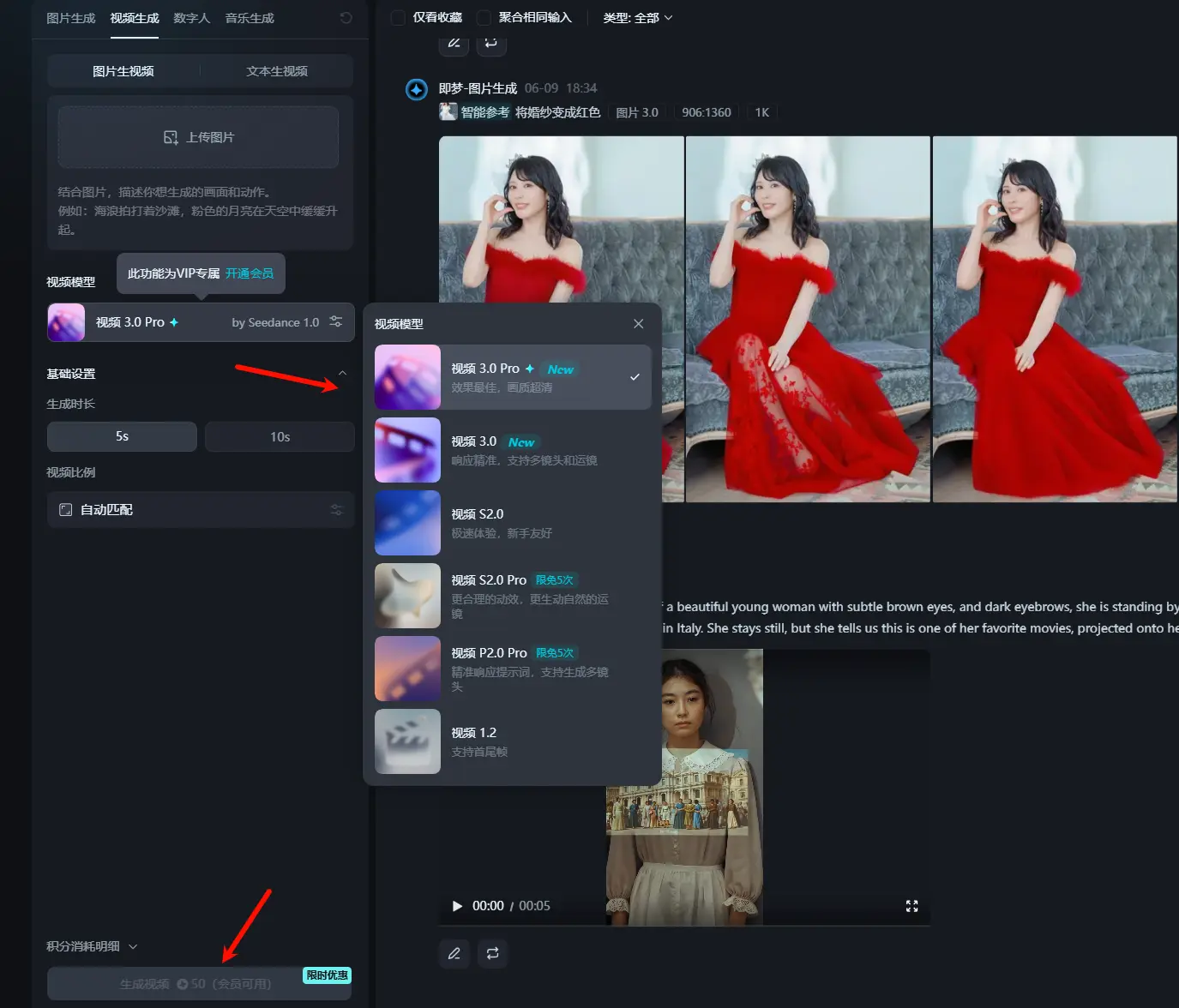
字节跳动推出视频生成模型 Seedance 1.0,视频生成迈入“电影级”体验字节跳动正式发布了其最新的视频生成模型 Seedance 1.0。该模型已集成在字节旗下 AI 创作平台“即梦”中,并以“视频生成3.0 Pro”版本面向用户开放(需会员权限使用)。目前,每生成一个5...视频模型# Seedance 1.0# 字节跳动# 视频生成模型10个月前03180
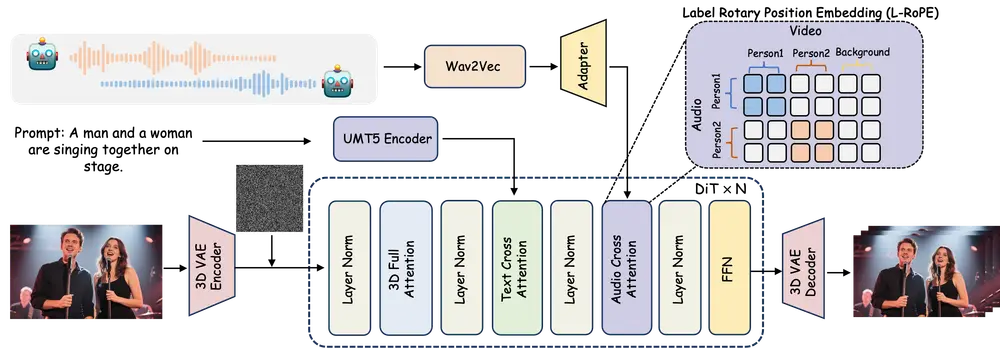
用于音频驱动的多人对话视频生成的新框架 MultiTalk:根据多路音频输入和提示生成包含互动的视频,同时确保唇部动作与音频同步中山大学深圳校区、美团和香港科技大学的研究人员推出用于音频驱动的多人对话视频生成的新框架 MultiTalk,该框架能够根据多路音频输入和提示生成包含互动的视频,同时确保唇部动作与音频同步。 项目主页...视频模型# MultiTalk# 多人对话视频生成10个月前01930
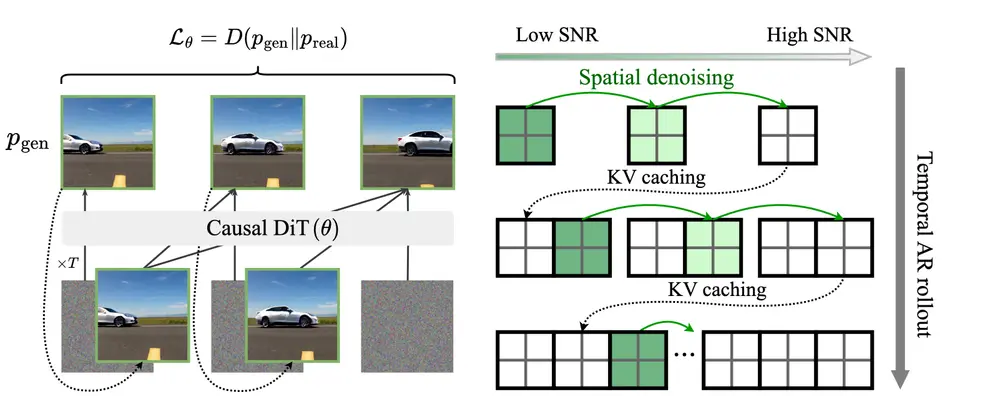
新型训练范式Self Forcing:用于自回归视频扩散模型,解决模型在训练和推理时的分布不一致问题Adobe研究和德克萨斯大学奥斯汀分校的研究人员推出新型训练范式Self Forcing ,用于自回归视频扩散模型,旨在解决模型在训练和推理时的分布不一致问题(即暴露偏差问题),从而提高视频生成的...视频模型# Self Forcing# 训练范式10个月前05120
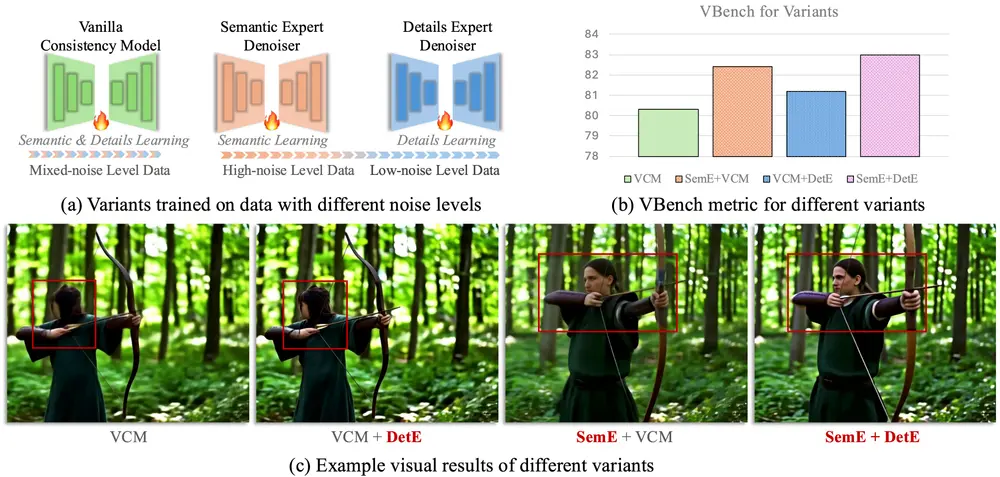
DCM:双专家一致性模型,实现高效高质量视频生成扩散模型在图像和视频合成任务中展现出卓越性能,但其依赖多步迭代去噪的过程,导致计算成本高昂。为解决这一问题,一致性模型(Consistency Models) 在加速扩散模型方面取得了重要进展。 然而...视频模型# DCM# 一致性模型10个月前04310
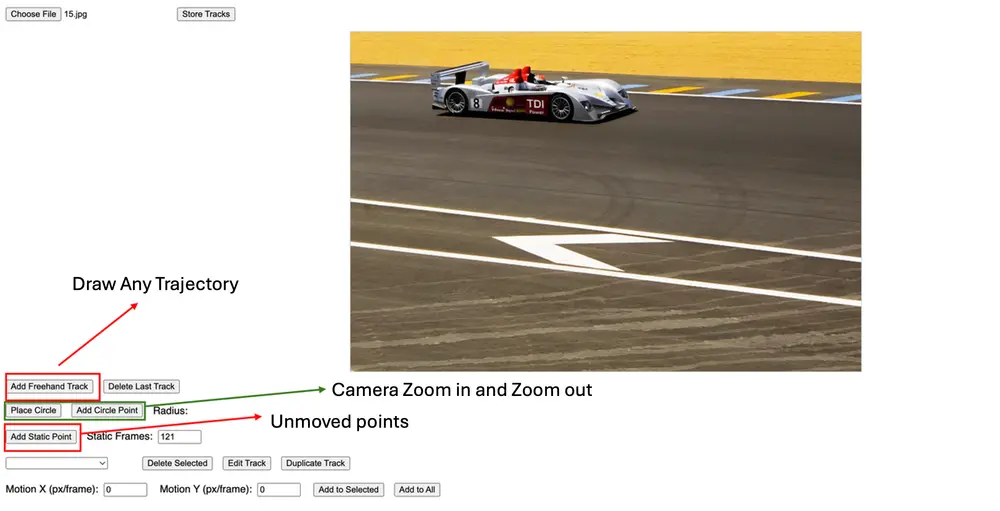
字节跳动推出全新视频生成框架 ATI:用“画轨迹”控制视频运动,对象、视角、局部变形一应俱全!字节跳动 AI 实验室发布了一项令人眼前一亮的视频生成技术 —— ATI(Any Trajectory Instruction),它让普通人也能通过“画轨迹”的方式,精准控制视频中物体的运动、镜头的移...视频模型# ATI# ATI-Wan2.1 14B# 字节跳动10个月前03870
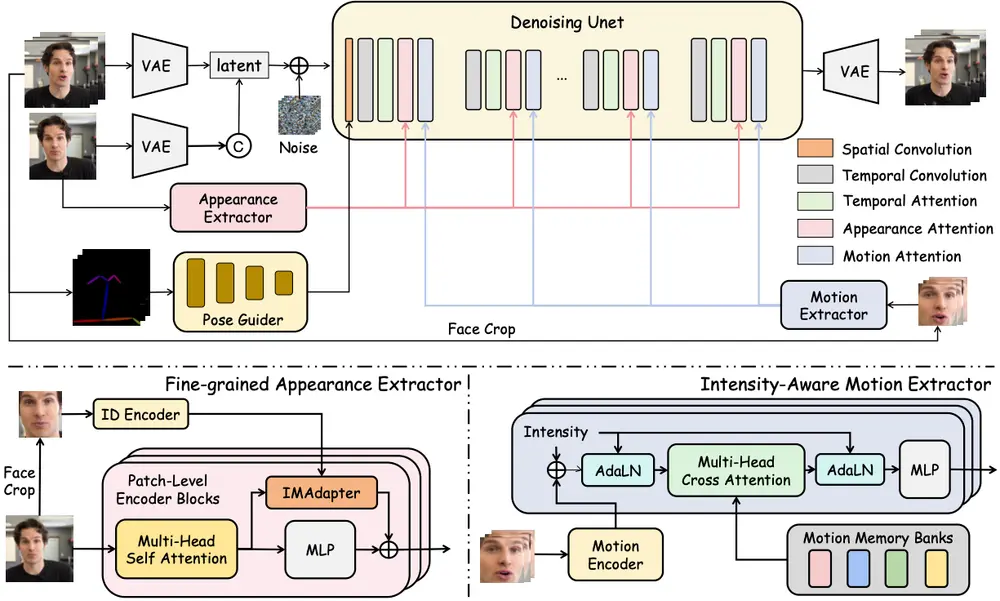
腾讯混元项目组推出数字人头像生成模型 HunyuanPortrait :用于高度可控且逼真的肖像动画生成腾讯混元项目组推出基于扩散模型的条件控制方法 HunyuanPortrait ,用于高度可控且逼真的肖像动画生成。该方法通过隐式表示来控制肖像动画,能够利用单张肖像图像作为外观参考和视频片段作为驱动模...视频模型# HunyuanPortrait# 腾讯混元10个月前01950
腾讯混元推出HunyuanVideo-Avatar:音频驱动、情感可控、支持多角色的虚拟人视频生成模型近年来,音频驱动人物动画(Audio-driven Avatar Animation)取得了显著进展,但仍有几个关键挑战尚未完全解决: 如何在保持角色一致性的前提下生成高度动态的视频; 实现角色与音频...视频模型# HunyuanVideo-Avatar# 腾讯混元# 视频生成模型10个月前04230
别让好模型消失,这个 WAN2.1 LoRA 合集值得收藏”近日,CivitAI 在 Visa 和 Mastercard 的压力下进一步收紧内容政策,导致平台上大量 模型被删除。这些模型中包含了许多创作者精心训练的作品,尤其是 NSFW类内容。 地址:http...视频模型# WAN2.1 LoRA10个月前01,1170
视频生成模型的高效推理新方案Jenga:无需重新训练模型即可实现HunyuanVideo和Wan2.1显著提速近年来,基于 DiT架构的视频生成模型在生成质量上取得了显著突破,但其高昂的计算成本却严重限制了实际部署与落地。 为了解决这一瓶颈,来自香港中文大学、香港科技大学、快手科技和思谋科技的研究团队提出了 ...视频模型# HunyuanVideo# Jenga# Wan2.110个月前05110