LIFT:利用人类反馈进行文生视频模型对齐的新型微调方法文本到视频(T2V)生成模型近年来取得了显著进展,能够生成高质量的合成视频。然而,这些模型在将合成视频与人类偏好(例如,准确反映文本描述)对齐方面仍然存在不足。复旦大学、上海人工智能科学院和阿德莱德大...视频模型# LIFT# 微调# 文生视频模型12个月前03550
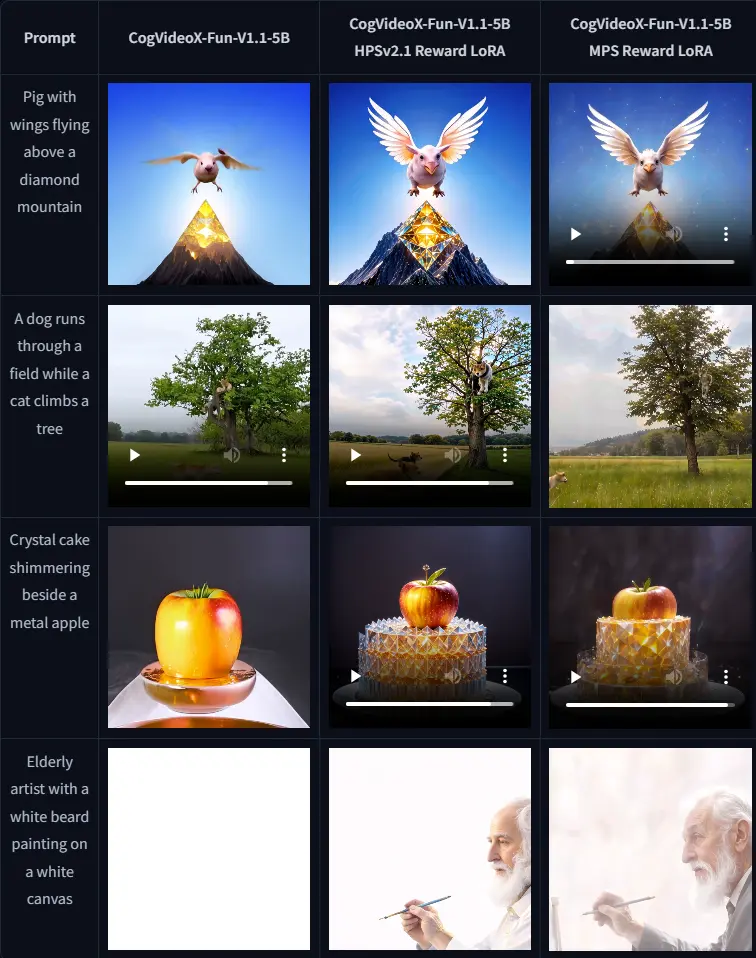
CogVideoX-Fun-V1.1-Reward-LoRAs:通过奖励反向传播技术训练Lora,以优化CogVideoX-Fun-V1.1生成的视频CogVideoX-Fun-V1.1-Reward-LoRAs是通过奖励反向传播技术训练Lora,以优化CogVideoX-Fun-V1.1生成的视频,使其更好地与人类偏好保持一致。 地址:https...视频模型# CogVideoX-Fun-V1.1# CogVideoX-Fun-V1.1-Reward-LoRAs12个月前03490
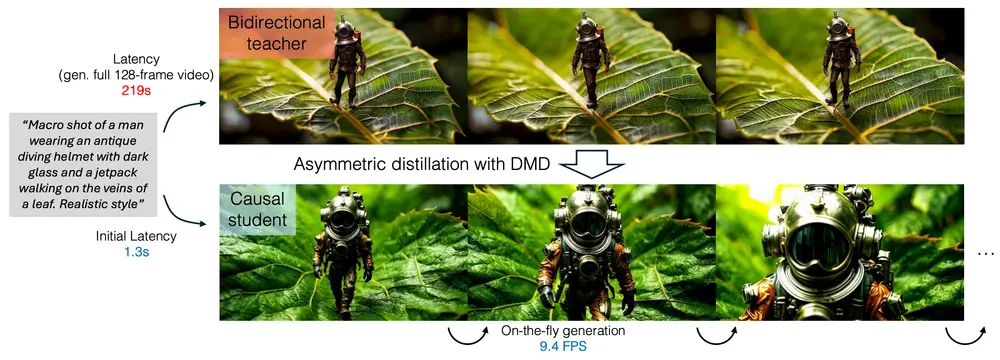
新型自回归视频扩散模型CausVid:解决传统双向扩散模型在交互式应用中的高延迟问题麻省理工学院和Adobe的研究人员推出新型自回归视频扩散模型CausVid,旨在解决传统双向扩散模型在交互式应用中的高延迟问题。通过将双向扩散模型蒸馏为快速自回归生成器,CausVid 能够实现低延迟...视频模型# CausVid# 自回归视频扩散模型9个月前03470
新型事件增强型网络 Ev-DeblurVSR:从低分辨率(LR)和模糊的输入视频中恢复出高分辨率(HR)的清晰视频中国科学技术大学类脑智能感知与认知教育部重点实验室、合肥人工智能研究院和新加坡国立大学推出新型事件增强型网络 Ev-DeblurVSR ,旨在解决模糊视频超分辨率(BVSR)任务,即从低分辨率(LR...视频模型# Ev-DeblurVSR# 视频超分模型9个月前03470
LTX-Video推出0.9.5版本:原生 ComfyUI 支持,关键帧与视频扩展增强可控性时隔近3个月,LTX-Video再次引来更新,随着2025年3月5日发布的v0.9.5版本,LTX-Video带来了多项改进和新特性,进一步增强了用户体验。通过质量提升、功能增强和用户体验改进,LTX...视频模型# LTX# LTX Video# 视频生成11个月前03380
腾讯开源混元图生视频模型HunyuanVideo-I2V在腾讯开源其混元视频模型HunyuanVideo之后,经过三个月的等待,腾讯终于推出了专注于图像到视频生成任务的混元图生视频模型HunyuanVideo-I2V。 GitHub:https://git...视频模型# HunyuanVideo-I2V# 混元图生视频模型# 腾讯11个月前03370
潞晨科技开源视频生成模型 Open-Sora 2.0,号称性能接近 OpenAI Sora潞晨科技宣布推出开源视频生成模型 Open-Sora 2.0,并全面开源模型权重、推理代码及分布式训练全流程。这款模型仅用 20 万美元(相当于 224 张 GPU 的计算成本)便成功训练出商业级 1...视频模型# Open-Sora 2.0# OpenAI# Sora11个月前03360
人体图像动画生成DisPose:从参考图像和驱动视频中生成视频,同时保持人物外观的一致性,并允许对动画进行精确控制可控的人体图像动画旨在使用驱动视频从参考图像生成视频。为了确保运动对齐,最近的工作尝试引入额外的密集条件(例如,深度图),但这些方法在参考角色的体型与驱动视频中的体型显著不同时,可能会损害生成视频的质...视频模型# DisPose# 人体图像动画生成12个月前03280
阿里云 PAI发布 Wan2.2-Fun:扩展Wan2.2文生视频与可控视频生成的能力边界阿里云 PAI 团队昨日正式推出 Wan2.2-Fun 系列模型,作为其 VideoX-Fun 项目的重要更新,进一步扩展了文生视频与可控视频生成的能力边界。 模型:https://huggingfa...视频模型# Wan2.2-Fun# 阿里云 PAI6个月前03250
ltx-video-0.9-vae-finetune:基于 LTX Video 0.9 VAE 进行的微调VAE模型ltx-video-0.9-vae-finetune 是由开发者 spacepxl 基于 LTX Video 0.9 VAE 进行的微调VAE模型,旨在解决该模型中常见的棋盘伪影问题。通过专注于解码器...视频模型# ltx-video-0.9-vae-finetune# VAE模型12个月前03250
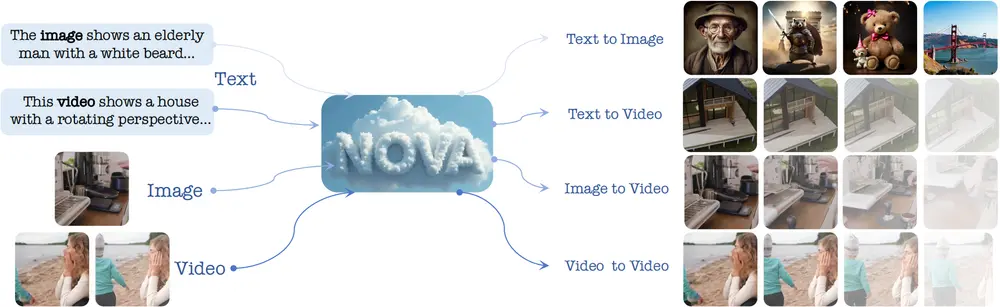
新型自回归视频生成模型NOVA:能够在无需向量量化的情况下,高效地生成视频北京邮电大学、中国科学院计算技术研究所、大连理工大学和北京智源研究院的研究人员提出了一种名为 NOVA 的新型自回归视频生成模型。该模型能够在无需向量量化的情况下,通过重新表述视频生成问题,实现了在时...视频模型# NOVA# 自回归视频生成模型12个月前03250
LIA-X:一种可解释的肖像动画方法,让面部动作“看得见、控得住”上海人工智能实验室和蔚蓝海岸大学的研究人员推出一种新颖的可解释肖像动画器LIA-X,旨在将驱动视频中的面部动态转移到源肖像上,并实现精细控制。 项目主页:https://wyhsirius.githu...视频模型# LIA-X# 肖像动画6个月前03240