SteadyDancer:用 I2V 范式解决首帧失真,生成身份一致的高保真人像动画人体图像动画技术迎来颠覆性突破!南京大学、腾讯与上海AI实验室联合推出的SteadyDancer框架,通过彻底摒弃传统参考图到视频(R2V)范式,转向图像到视频(I2V)全新思路,从根源上解决了长期困...视频模型# SteadyDancer2个月前01070
SLA:清华与伯克利联合提出可训练稀疏线性注意力,加速DiT视频生成在高分辨率、长时序视频生成任务中,扩散变换器(Diffusion Transformer, DiT)已成为主流架构。然而,其核心组件——自注意力机制——面临着一个根本性瓶颈:计算复杂度随序列长度呈平方...视频模型# SLA# 可训练混合注意力机制4个月前01020
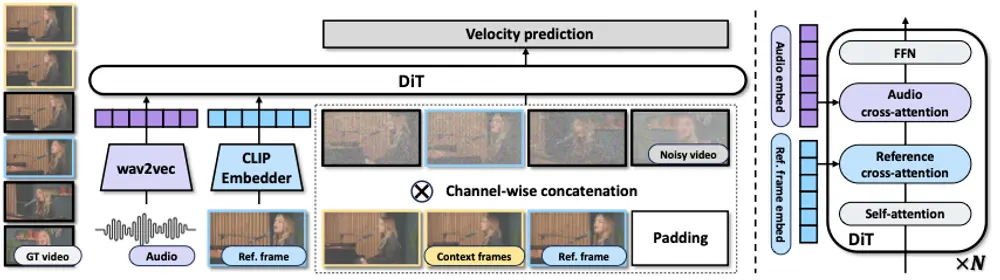
InfiniteTalk:支持稀疏帧输入的全动态音频驱动视频生成,实现全身协调的说话视频生成在虚拟人、影视后期、跨语言内容本地化等场景中,理想的配音技术不仅要实现精准的唇部同步,还需让头部运动、面部表情、身体姿态自然地跟随语音节奏变化,同时保持人物身份一致性。 项目主页:https://me...视频模型# InfiniteTalk# 对口型5个月前01020
FantasyPortrait:基于DIT架构模型的多角色肖像动画生成框架由阿里巴巴与北京邮电大学联合提出,FantasyPortrait 是一个基于扩散变换器(Diffusion Transformer)的创新框架,用于从静态图像生成高保真、富有表现力的单角色与多角色面部...视频模型# FantasyPortrait# 多角色肖像动画生成7个月前0960
清华大学 & 字节跳动联合推出 HuMo:一个以人为中心的多模态视频生成框架一段文字描述 + 一张人物照片 + 一段语音音频,能否生成一个口型同步、动作自然、形象一致的高质量人物视频? 现在,可以了。 清华大学与字节跳动智能创作团队合作推出 HuMo(Human-Centri...视频模型# HuMo# 字节跳动5个月前0940
腾讯开源混元视频音效生成模型HunyuanVideo-Foley:端到端TV2A模型,为创作者打造高保真音视频体验腾讯今天正式开源 HunyuanVideo-Foley —— 一个端到端的文本-视频-音频(Text-Video-to-Audio, TV2A)生成模型,专注于为视频内容自动生成高保真、语义对齐的音效...视频模型# HunyuanVideo-Foley# 混元视频音效生成模型# 腾讯5个月前0930
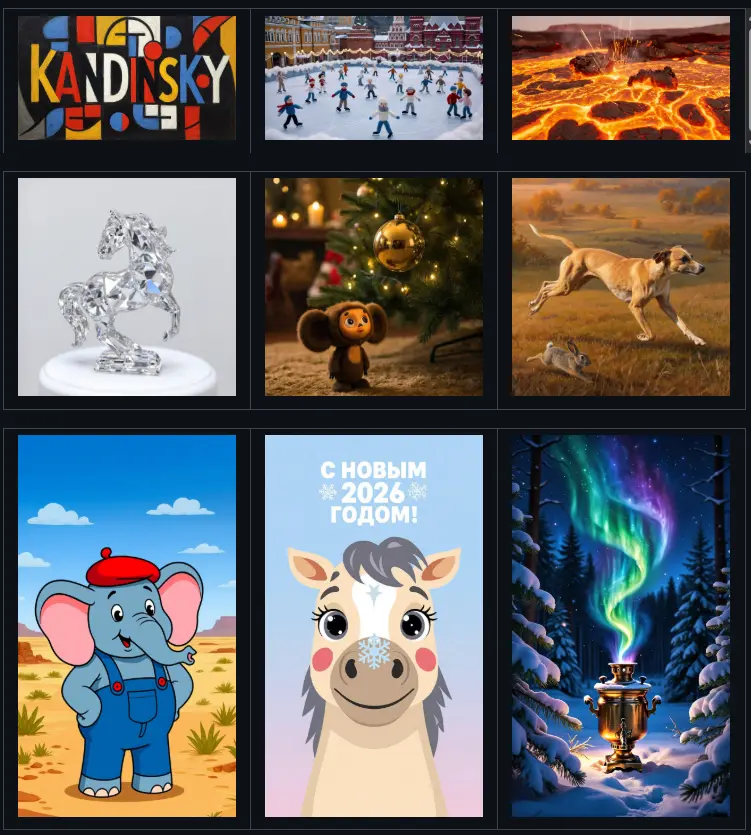
Kandinsky 5.0 全系列开源:190亿参数视频Pro+轻量版,支持中俄双语+5-10秒HD生成来自俄罗斯的AI企业Sber AI,正式推出新一代扩散模型家族 Kandinsky 5.0,以“全场景覆盖+开源开放”为核心亮点,涵盖视频生成(T2V/I2V)、图像生成(T2I)、图像编辑三大核心能...图像模型视频模型# Kandinsky 5.02个月前0910
Stable Video Infinity(SVI)发布 2.0 Pro:基于错误回收机制的无限长视频生成模型洛桑联邦理工学院(EPFL)的研究团队推出 Stable Video Infinity(SVI) ——一款能够生成任意长度视频的人工智能模型。它通过一项名为 “错误回收微调(Error-Recycli...视频模型# Stable Video Infinity1个月前0890
腾讯开源HunyuanVideo-1.5:83亿参数实现顶级画质,14G显存消费级显卡即可运行在视频生成模型多追求大参数堆料的当下,腾讯混元项目组推出的HunyuanVideo-1.5走出了一条“小而精”的差异化路线。这款仅搭载83亿参数的轻量级视频生成模型,不仅实现了开源领域顶尖的视觉质量与...视频模型# HunyuanVideo-1.5# 腾讯2个月前0790
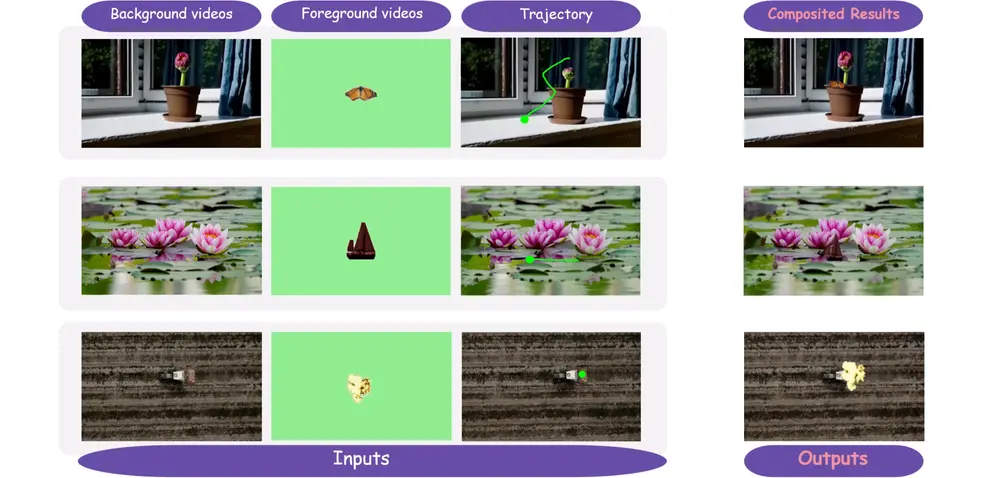
新型视频合成方法GenCompositor:实现轨迹可控的视频级前景融合由北京大学经济与管理学院、腾讯PCG ARC实验室、大湾区大学与香港中文大学联合提出的新型视频合成方法 GenCompositor,为视频创作中的“前景-背景融合”问题提供了一种自动化解决方案。该方法...视频模型# GenCompositor# 视频合成5个月前0790
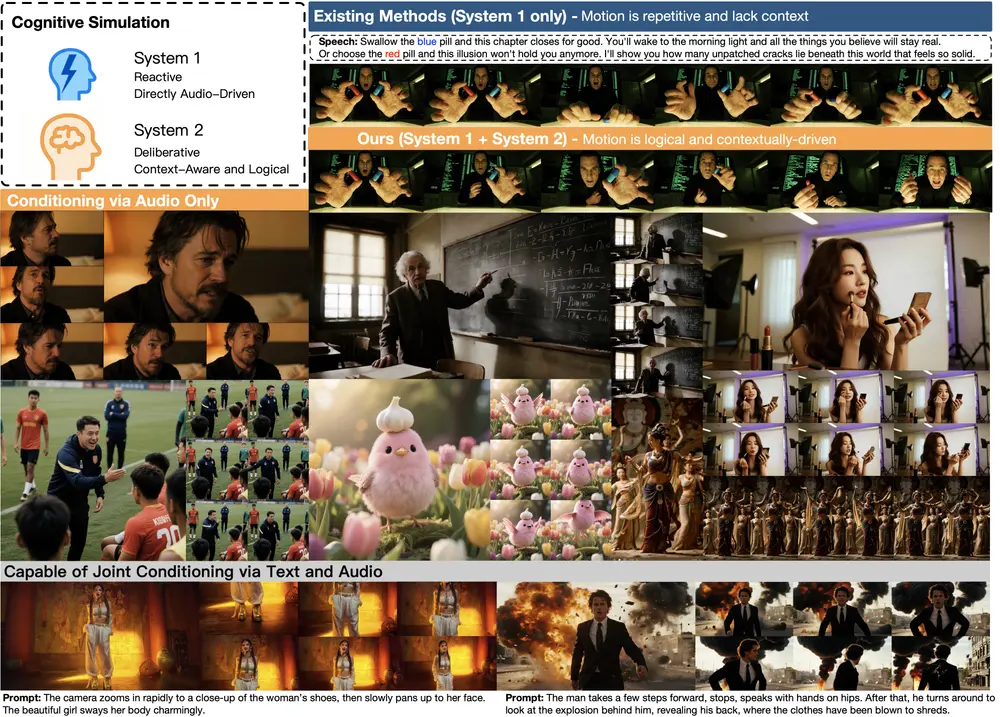
字节跳动发布OmniHuman-1.5:模拟人类双重认知,生成语义连贯的高逼真角色动画字节跳动近期推出新型视频角色生成框架 OmniHuman-1.5,核心突破在于模拟人类“系统1(快速直觉反应)+系统2(缓慢深思规划)”的双重认知过程,实现从“单一图像+语音轨道”到“物理逼真、语义连...视频模型# OmniHuman-1.5# 字节跳动5个月前0720
腾讯发布混元世界模型 - Voyager:单图生成 3D 场景,实现长距离沉浸式探索腾讯今天正式推出混元世界模型 - Voyager(HunyuanWorld-Voyager),这是一款创新的视频扩散框架。其核心能力在于:基于单张输入图像即可生成具备世界一致性的 3D 点云,支持用户...视频模型# HunyuanWorld-Voyager# 混元世界模型 - Voyager# 腾讯5个月前0700