新谷歌推出 Veo 3.1 Lite:最具成本效益的视频生成模型,助力开发者大规模应用谷歌今日正式宣布推出 Veo 3.1 Lite,这是其 Veo 3.1 系列中最具成本效益的视频生成模型。该模型现已通过 Gemini API 和 Google AI Studio 向开发者开放,旨在...早报视频模型# Veo 3.1 Lite# 谷歌2天前0130
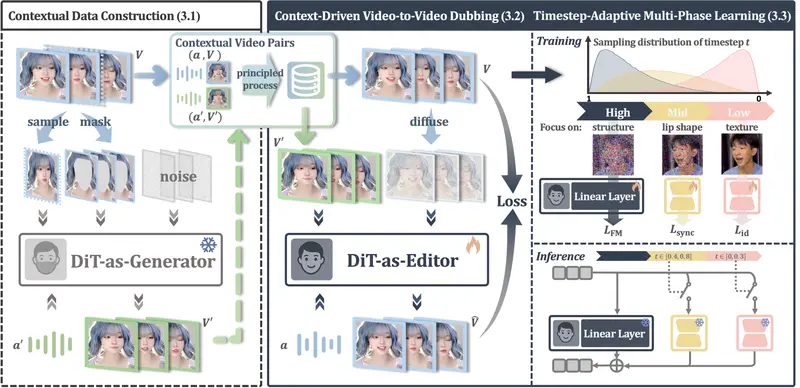
X-Dub:告别“面具式”配音,AI 让视频唇同步更自然逼真在影视翻译、虚拟人互动和短视频创作中,音频驱动的视觉配音(Visual Dubbing)技术至关重要。然而,传统方法长期受困于一个核心难题:缺乏完美的成对训练数据(即除了嘴型不同,其他完全一致的视频...视频模型# X-Dub# 数字人# 配音4天前0130
daVinci-MagiHuman:单流架构重塑音视频生成,1080p 仅需 38 秒的开源新标杆在 AI 生成内容(AIGC)领域,音视频联合生成一直被视为“皇冠上的明珠”。然而,现有的开源方案往往陷入两难:要么采用复杂的多流架构导致推理缓慢、难以优化,要么为了速度牺牲了人物表情与语音的自然度...视频模型# daVinci-MagiHuman# 视频生成1周前01240
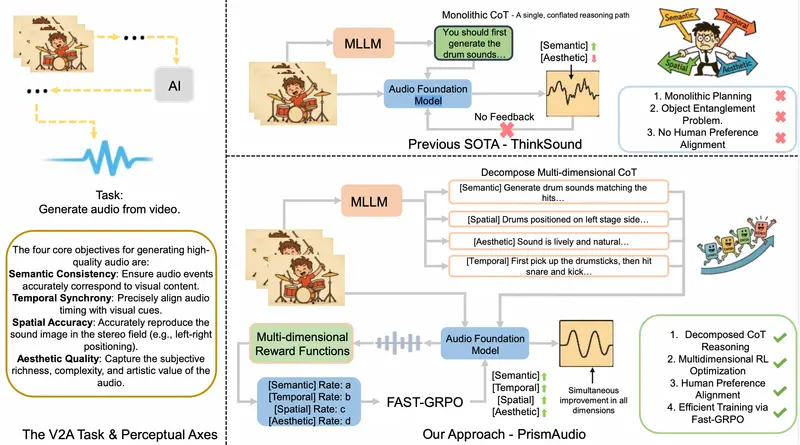
PrismAudio:阿里通义首创“思维链+强化学习”视频音效框架,让AI学会“先思考再发声”在视频生成领域,画面与声音的同步一直是难以攻克的“最后一公里”。传统的视频转音频(Video-to-Audio)模型往往采用“端到端”的黑箱模式:输入视频,直接输出音频。这种“直觉式”生成容易导致声音...视频模型# PrismAudio# 视频音效1周前0170
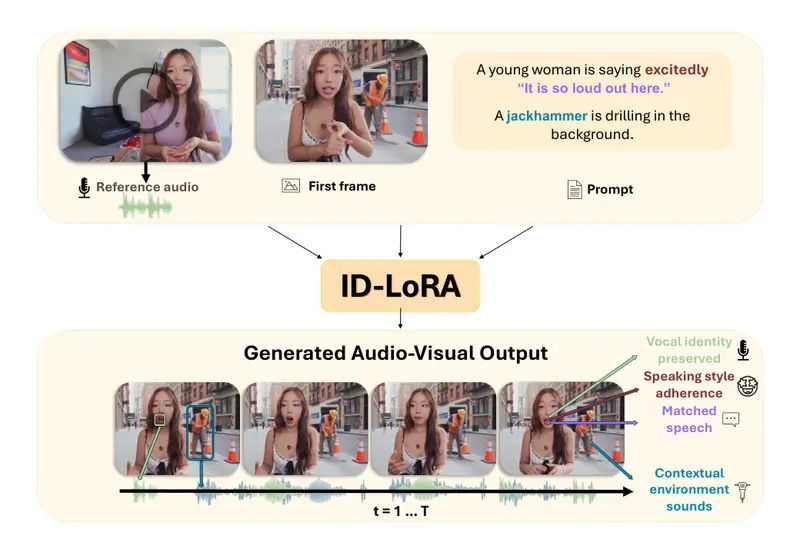
ID-LoRA:让AI同时“克隆”你的长相和声音,还能配合场景表演你有没有想过,如果AI能根据一张照片和一段声音,就能生成一个“数字分身”,让这个分身在任何场景中说话、表演,而且声音和口型都能完美匹配,这会带来什么可能? 这正是特拉维夫大学等研究机构最新发布的 ID...视频模型# ID-LoRA# 数字人3周前0280
EffectMaker:腾讯混元新作,无需微调即可“克隆”电影级特效,让普通人也能做 VFX 大师“好莱坞大片里那些令人震撼的火焰、冰霜、能量波,曾经需要数百万美元和数年训练才能制作。现在,只需一段参考视频和一张照片,AI 就能为你‘克隆’出同样的奇迹。” 由 腾讯混元 (Tencent HunY...视频模型# AI特效# EffectMaker3周前0300
Lightricks 双重重磅发布:LTX-2.3 模型进化与 LTX Desktop 开源编辑器,本地视频生成时代正式来临Lightricks 今日宣布同步推出两项里程碑式产品:LTX-2.3,一个经过实战打磨、架构全面升级的视频生成模型;以及 LTX Desktop,一款直接构建于该引擎之上的生产级本地视频编辑器。 这...早报视频模型# Lightricks# LTX Desktop# LTX-2.34周前02040
Helios:北大与字节联手打造 14B 实时长视频模型,单卡 19.5 FPS 刷新生成速度纪录在 AI 视频生成领域,长期存在一个“不可能三角”:生成速度快、视频时长长、画面质量高,三者往往难以兼得。主流模型要么只能生成几秒的短视频,要么需要数十分钟才能渲染出几秒钟的画面,且长视频极易出现人物...视频模型# Helios# 实时长视频模型4周前01810
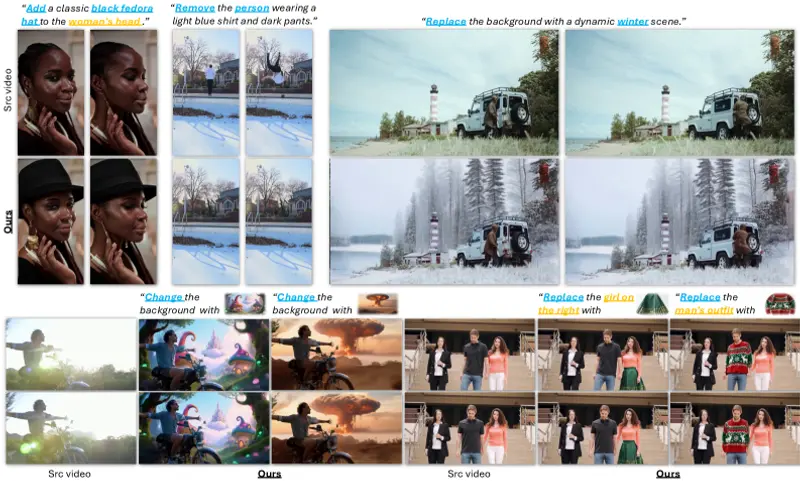
Kiwi-Edit:开源视频编辑新标杆,首创“指令 + 参考图”双模驱动,打破商业模型数据垄断在 AI 视频编辑领域,我们常面临一个尴尬境地:文字指令难以描述精确的视觉细节(如“把那辆车换成特定的红色法拉利”),而现有的参考图引导编辑又受限于高质量训练数据的极度匮乏。 Kiwi-Edit 是由...视频模型# Kiwi-Edit# 视频编辑4周前0330
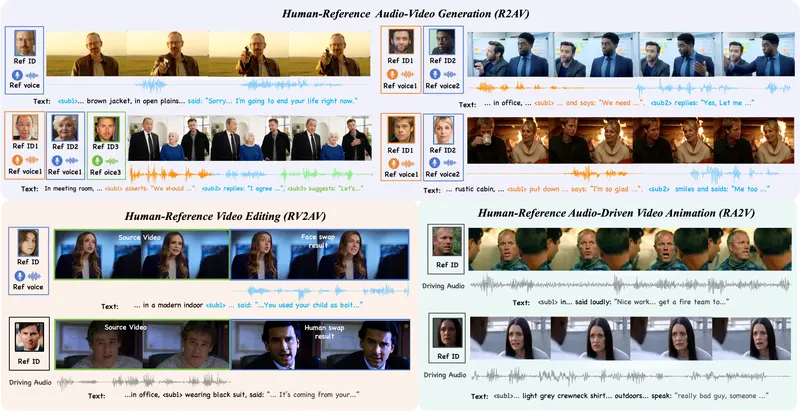
虚拟数字人项目DreamID-Omni:清华&字节联合发布统一框架,一人一模型搞定“换脸、变声、让照片说话”想象一下:你上传一张爱因斯坦的照片和一段录音,AI 就能生成他在办公室里发表演讲的完整视频,口型完美匹配,声音惟妙惟肖;或者,你想把电影片段中的主角换成自己,连声音也一并替换,动作表情却原汁原味。 这...视频模型# DreamID-Omni# 数字人1个月前0880
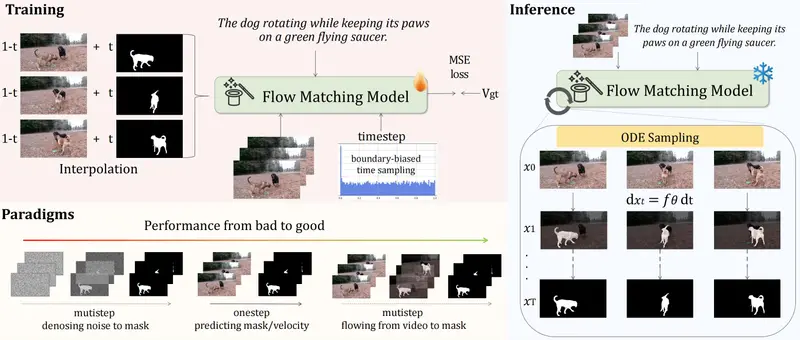
FlowRVS:颠覆“定位 - 分割”旧范式,用“视频变形”魔法实现指代视频对象分割新 SOTA想象这样一个场景:视频里有两只狗在玩耍,你对 AI 说:“帮我追踪那只正在跳的白色狗。”或者在一群人中,你指定:“锁定那个先骑自行车进画面的男人。” 这种用自然语言描述来指定视频中特定对象,并让 AI...视频模型# FlowRVS# 分割模型1个月前0550
Capybara:统一视觉创作模型,一个模型搞定文生图、视频生成与全能编辑在当前的 AI 视觉创作领域,我们正陷入一种“工具碎片化”的困境:生成图片用 Midjourney,生成视频换 Runway,修图得开 Photoshop,剪视频又要另一套流程。这些工具不仅接口割裂...视频模型# Capybara# 统一视觉创作模型1个月前0910