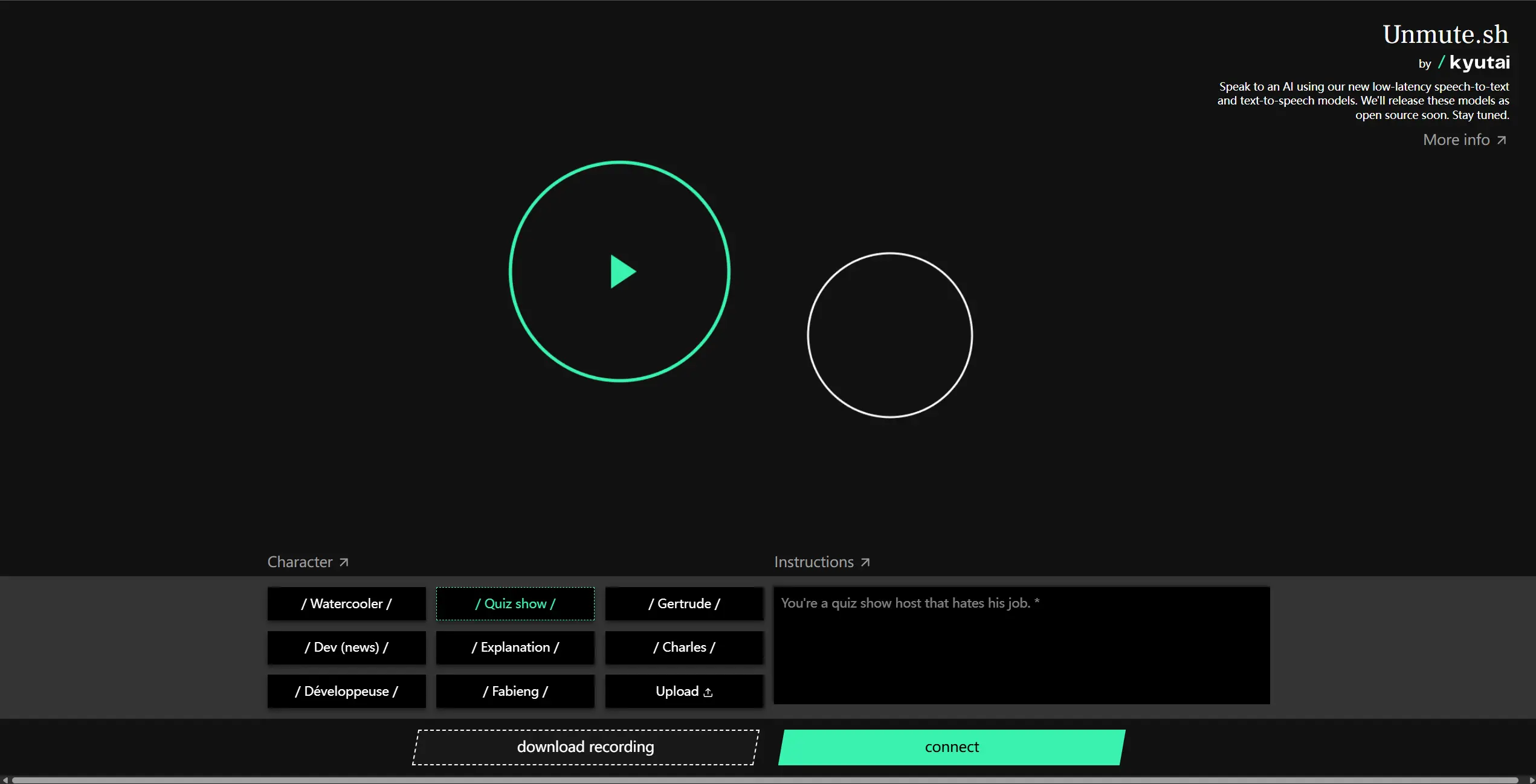
Kyutai 推出全新语音系统Unmute,让任何大模型都能“说话”Kyutai 近日发布了一款名为 Unmute 的全新语音 AI 系统。与以往语音模型不同,Unmute 并不试图替代现有的语言模型,而是作为一个高度模块化的“插件”,可以无缝接入任意文本大语言模型...语音模型# Kyutai# Unmute# 语音模型8个月前01480
阶跃星辰开源 Step-Audio-EditX:首个基于 LLM 的迭代式音频编辑模型阶跃星辰(Step AI)正式发布 Step-Audio-EditX —— 一款革命性的基于大语言模型(LLM)的音频编辑系统,首次实现对语音情感、说话风格与副语言特征的高精度、迭代式、零样本控制,并...语音模型# Step-Audio-EditX# 阶跃星辰# 音频编辑模型3个月前01430
新型歌曲生成模型JAM:让歌词精准变成完整歌曲你有没有想过,输入一段歌词,再标上每个词该在什么时候唱,就能自动生成一首旋律自然、节奏准确、风格统一的完整歌曲? 这不是未来设想,而是已经实现的技术突破。 新加坡科技设计大学(SUTD)与 Lambd...语音模型# JAM# 歌曲生成模型6个月前01250
艾伦AI研究所推出全新开源 ASR 模型家族OLMoASR在自动语音识别(ASR)领域,Whisper 一直是开源社区的标杆——强大、鲁棒、支持零样本迁移。但它有一个根本局限:训练数据未公开,模型行为难以分析,也无法完全复现。 现在,艾伦人工智能研究所(AI...语音模型# OLMoASR# 艾伦AI研究所5个月前01140
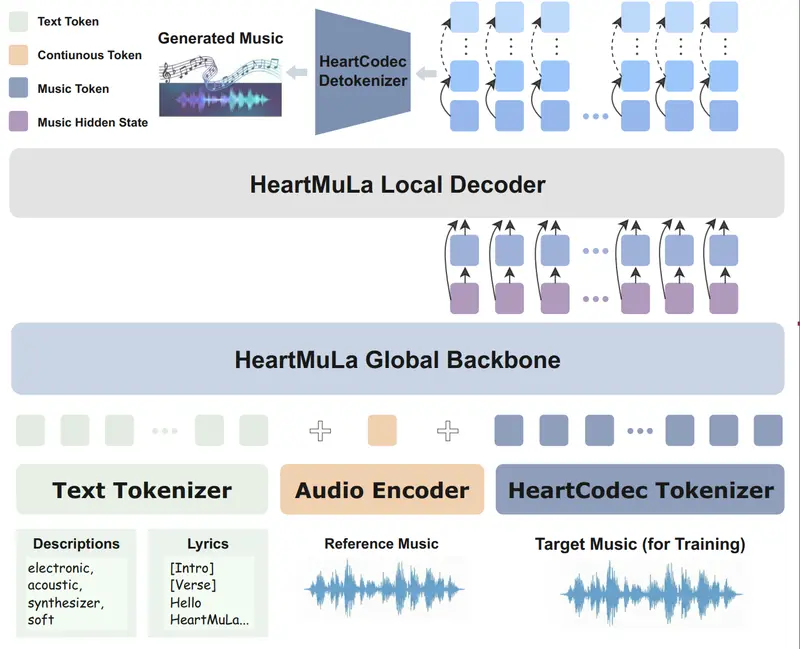
HeartMuLa:开源音乐基础模型家族,支持歌词识别、高保真生成与细粒度控制如果你曾幻想过——只需输入一段歌词和一句描述(如“一首欢快的流行歌,吉他伴奏,副歌要有电子音效”),AI 就能生成一首结构完整、音质高保真的歌曲——那么 HeartMuLa 项目正将这一愿景变为现实...语音模型# HeartMuLa# 音乐模型2周前01110
SongPrep:腾讯提出自动化歌曲预处理方案,破解AIGC歌曲生成的数据难题在AIGC的众多分支中,歌曲生成因兼具“音乐旋律”“歌词文本”“结构韵律”的多维度创作需求,一直是技术难点。尽管互联网上有海量歌曲资源,但要将这些原始音频转化为可训练AIGC模型的“结构化数据”,传统...语音模型# SongPrep# 腾讯# 音乐模型4个月前01090
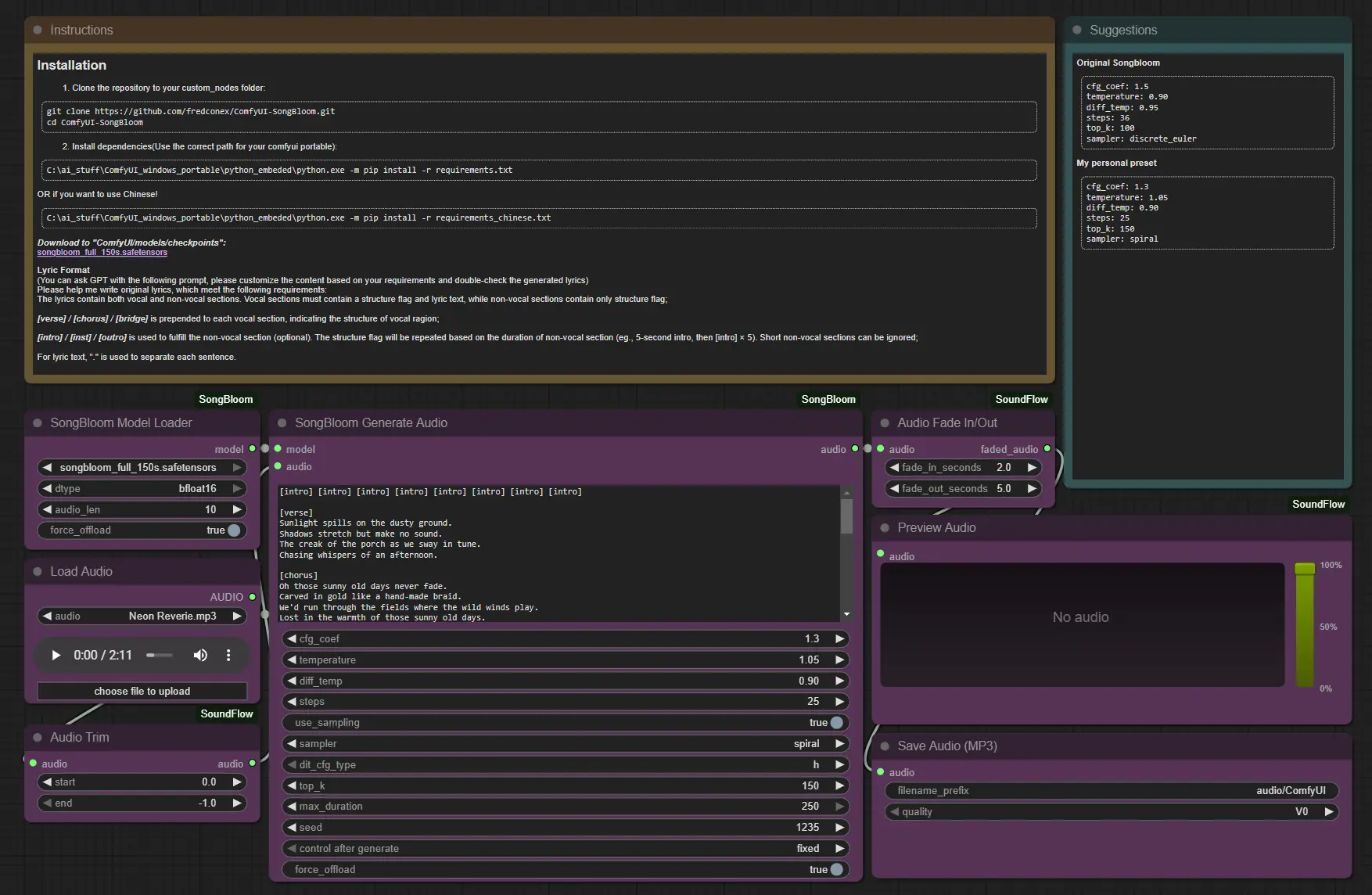
SongBloom:一种实现结构连贯与高保真度的全曲生成新框架在自动音乐生成领域,生成一首具备完整结构、风格统一、人声与伴奏和谐融合的全长歌曲,依然是极具挑战性的任务。 现有方法——无论是基于语言模型的自回归生成,还是基于扩散模型的音频合成——往往面临两难困境...语音模型# SongBloom# 音乐生成6个月前01000
阿里通义实验室发布 Qwen3-ASR-Flash:支持多语种、歌声识别与上下文定制的新一代语音识别服务阿里通义实验室近日正式推出 Qwen3-ASR-Flash,一款基于 Qwen3 大模型基座 构建的高性能语音识别(ASR)服务。该服务融合千万小时级语音数据与海量多模态训练样本,致力于在准确率、鲁棒...语音模型# Qwen3-ASR-Flash5个月前0960
Hume AI 发布 Octave 2:更智能、多语言、低延迟的语音合成系统Hume AI 正式推出 Octave 2 ——其下一代文本到语音(TTS)模型的重大升级版本。作为“语音语言模型”(Speech Language Model, SLM)架构的延续,Octave 2...语音模型# EVI 4 mini# Hume AI# Octave 24个月前0890
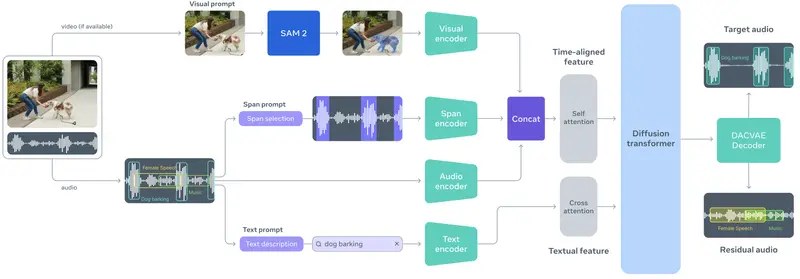
Meta发布SAM Audio:首个支持文本、视觉、时间提示的统一音频分离模型在图像领域,Meta 的 Segment Anything Model (SAM) 通过“任意分割”能力,彻底改变了计算机视觉的交互范式。如今,这一理念正式延伸至音频领域。 Meta 正式发布 SAM...语音模型# Meta# SAM Audio# 音频分离模型1个月前0830
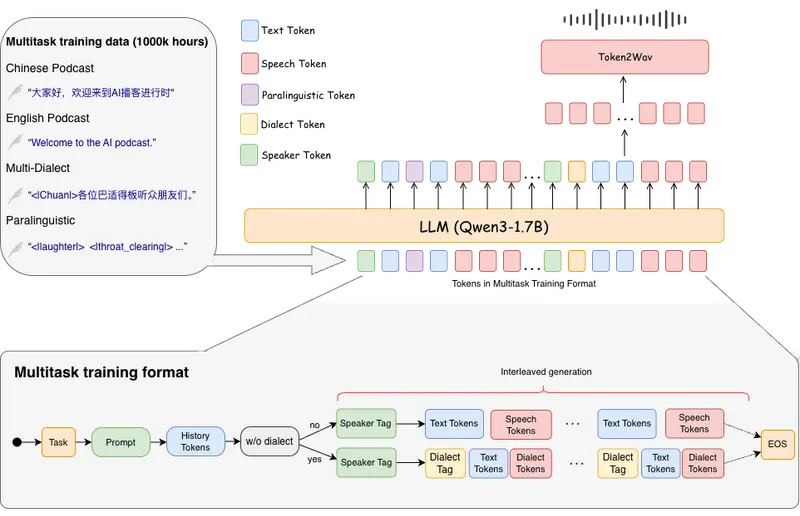
SoulX-Podcast:支持方言与副语言的真实感播客语音合成系统西北工业大学、Soul AI 实验室与上海交通大学联合推出 SoulX-Podcast —— 一个专为长篇、多轮次、多说话者对话场景设计的语音合成系统。它不仅能生成高质量的播客风格对话语音,也在传统单...语音模型# SoulX-Podcast# 播客3个月前0740
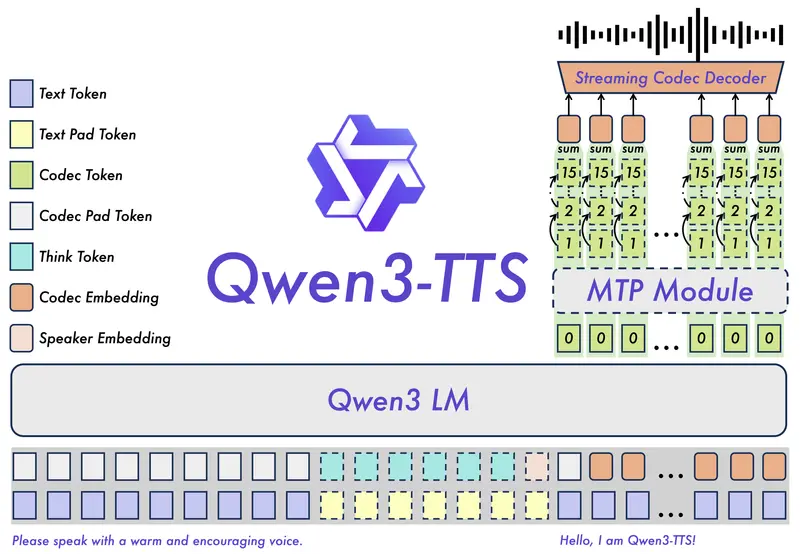
Qwen3-TTS 全家桶开源:支持音色克隆、创造与多语言拟人语音在语音生成技术快速迭代的当下,开发者与用户对高保真、可定制、低延迟的语音合成方案需求日益迫切。阿里Qwen项目组推出的 Qwen3-TTS 开源全家桶,凭借音色克隆、音色创造、拟人化语音生成与自然语言...语音模型# Qwen3-TTS# 阿里1周前0730