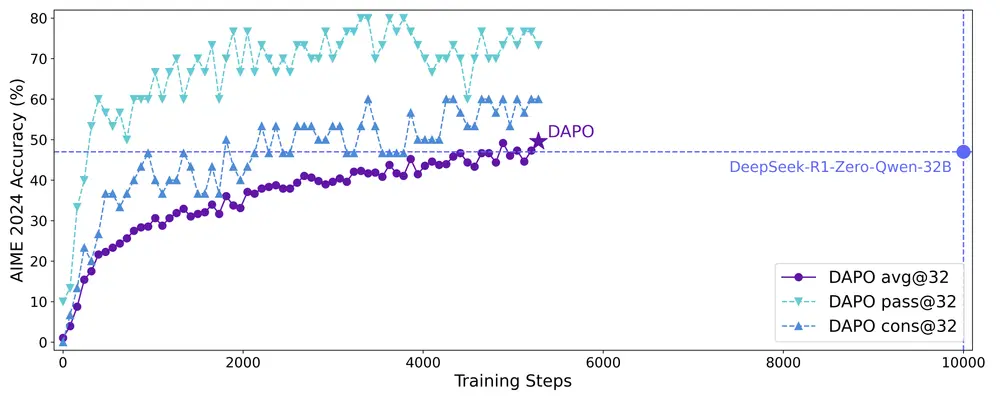
字节跳动发布DAPO(动态采样策略优化):提升大语言模型的推理能力来自字节跳动、清华大学和香港大学的研究团队共同推出了一款名为 DAPO(动态采样策略优化)的开源系统,旨在提升大语言模型(LLM)的推理能力。DAPO 的发布标志着在强化学习(RL)技术应用于大规模语...新技术# DAPO# 动态采样策略优化# 大语言模型1年前02640
字节跳动提出MAGREF:支持多参考图像和文本提示的高质量视频生成框架近年来,随着扩散模型等深度生成技术的发展,视频生成能力取得了显著进步。然而,在涉及多个参考主体的场景中,如何保证各主体之间的视觉一致性、身份一致性和生成稳定性,依然是一个重大挑战。 为了解决这一问题...视频模型# MAGREF# 字节跳动# 视频生成框架10个月前02530
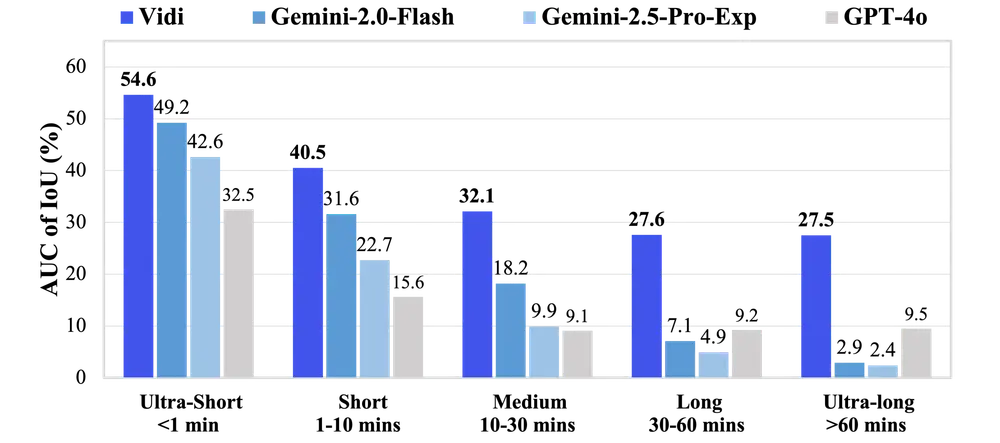
字节跳动推出多模态模型Vidi:专门用于视频理解和编辑字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成...多模态模型# Vidi# 多模态模型# 字节跳动11个月前02330
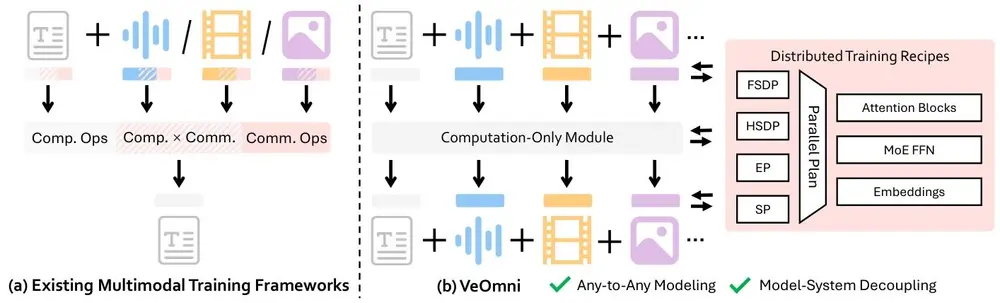
字节跳动开源 VeOmni:一个面向全模态大模型的 PyTorch 原生训练框架在大模型从“能说”向“能看、能听、能理解”演进的当下,多模态统一模型(Omni-Modal LLMs)正成为技术前沿。然而,训练一个同时处理文本、图像、语音和视频的全能模型,仍面临工程复杂、扩展困难...多模态模型# VeOmni# 多模态统一模型# 字节跳动8个月前02110
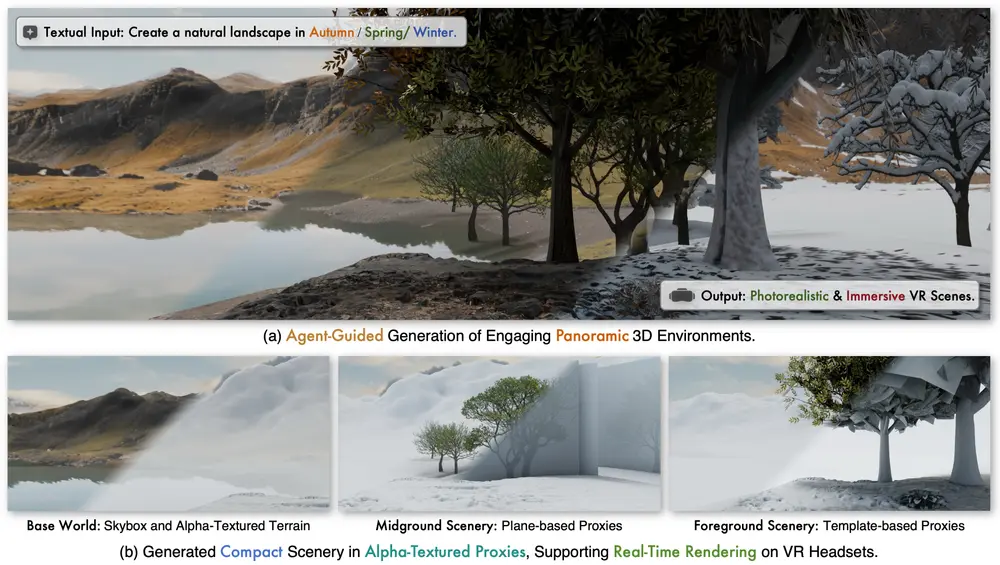
字节跳动推出新型框架ImmerseGen:用于从文本提示自动生成沉浸式 3D 场景字节跳动和浙江大学的研究人员推出新型框架ImmerseGen ,用于从文本提示自动生成沉浸式 3D 场景。ImmerseGen 通过使用轻量级的几何代理(如简化地形和带有 alpha 通道的纹理平面...3D模型# ImmerseGen# 字节跳动9个月前02100
字节跳动开源 BitDance:14B 参数自回归模型,生成速度超越扩散模型 30 倍在 AI 绘画领域,长期存在着“画质”与“速度”的博弈,以及“扩散模型”与“自回归模型”的路线之争。扩散模型(如 Stable Diffusion)画质优异但推理步骤繁琐;自回归模型(类似 LLM 生...图像模型# BitDance# 字节跳动# 自回归模型1个月前02080
字节跳动 Seed 团队正式发布 SeedEdit 3.0:支持 4K 图像编辑,编辑可用率显著提升今日,字节跳动 Seed 团队正式发布了新一代图像编辑模型 SeedEdit 3.0。该模型基于文生图模型 Seedream 3.0,融合多样化的训练数据与奖励机制,在图像主体与背景一致性、指令理解能...图像模型# SeedEdit 3.0# 字节跳动10个月前02040
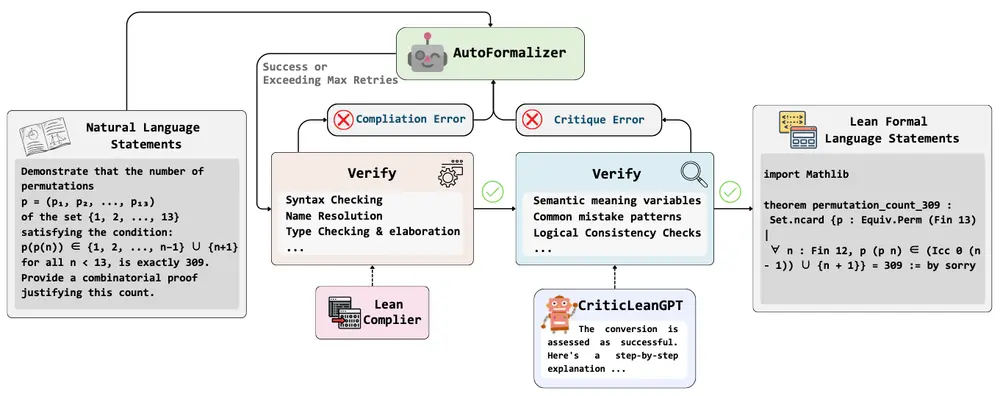
字节跳动 & 南大联合推出 CriticLean 框架:让 AI 更准确地翻译数学为代码将自然语言数学语句自动转化为形式化代码(如 Lean 4)是计算数学中的核心挑战之一。尽管已有许多自动化工具尝试解决这一问题,但其准确性仍面临瓶颈,尤其是在需要深入理解语义的复杂场景中。 为此,字节跳...大语言模型# CriticLean# 字节跳动9个月前01980
字节跳动发布Vidi2:攻克细粒度时空定位,视频检索性能领先GPT - 5字节跳动智能创作团队推出的第二代多模态视频模型Vidi2,凭借在时空定位、时间检索和视频问答三大核心能力上的突破,打破了传统视频模型在长视频理解和精细交互上的局限。该模型不仅在核心任务中实现对Gemi...多模态模型# Vidi2# 多模态视频模型# 字节跳动4个月前01960
字节跳动推出新型框架 InfiniteYou (InfU):用于在保留个人身份特征的前提下,通过自由形式的文本描述重新创作照片字节跳动推出新型框架 InfiniteYou (InfU),用于在保留个人身份特征的前提下,通过自由形式的文本描述重新创作照片。该框架利用先进的扩散变换器(Diffusion Transformers...图像模型# InfiniteYou# InfU# 字节跳动1年前01960
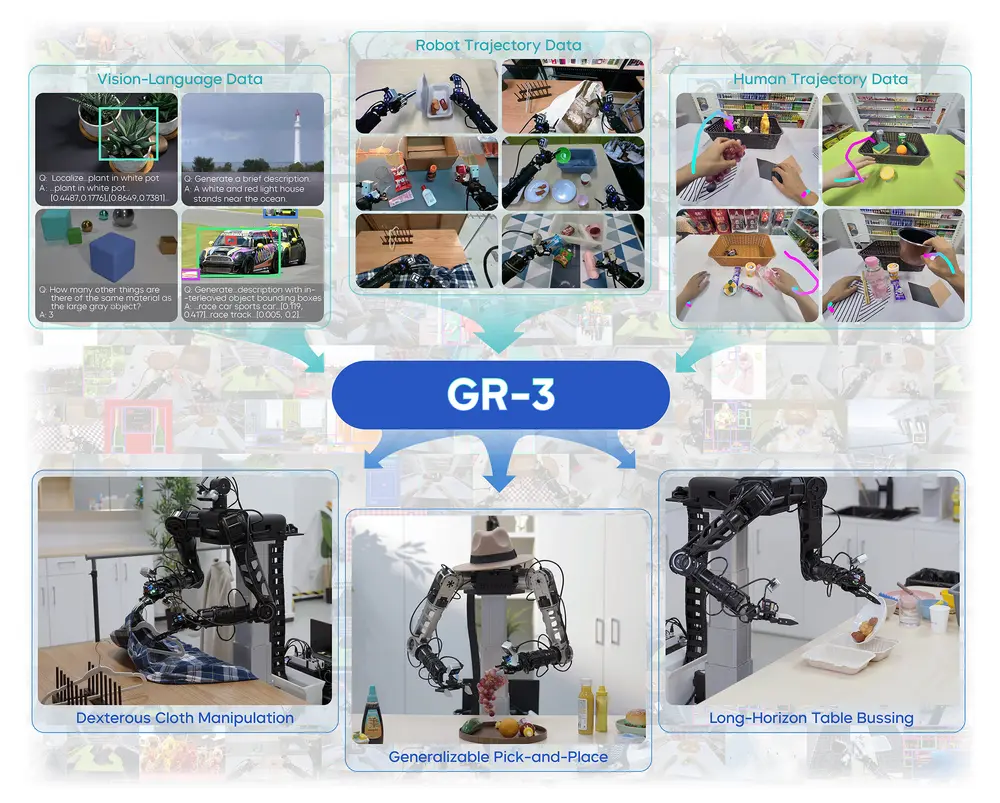
字节跳动Seed团队发布新一代机器人操作大模型Seed GR-3字节跳动Seed团队近日推出一款面向复杂操作任务的大规模机器人模型——Seed GR-3(Generalist Robot Model-3)。该模型具备良好的泛化能力,支持长序列任务执行与多模态指令理...多模态模型# Seed GR-3# 字节跳动8个月前01950
派拉蒙与迪士尼接连发函,指控字节跳动旗下Seedance 2.0侵犯影视 IP继迪士尼之后,派拉蒙天空之舞(Paramount Skydance)也正式向字节跳动发出法律停止函,指控其旗下 AI 生成平台 Seedance 视频 和 Seedream 图像 “公然侵犯”其知识产...早报# 字节跳动# 派拉蒙# 迪士尼1个月前01640