字节跳动提出OmniInsert:无需遮罩,任意对象都能自然插入视频在影视后期、广告制作乃至虚拟内容创作中,“将一个新角色或物体自然地加入已有视频”是一项高频需求。传统方法依赖精确的遮罩标注、关键帧追踪和复杂的合成流程,成本高、耗时长。 近期,基于扩散模型的技术为这一...视频模型# OmniInsert# 字节跳动# 视频编辑6个月前01600
Dolphin-v2:字节跳动发布支持21类元素的通用文档解析模型在办公自动化、知识管理与智能体工作流中,将非结构化文档转化为结构化数据是关键第一步。然而,现实中的文档来源复杂:既有干净的 PDF、Word,也有手机拍摄的带畸变、阴影、模糊的纸质文件。现有解析模型往...多模态模型# Dolphin-v2# 字节跳动# 文档解析模型4个月前01570
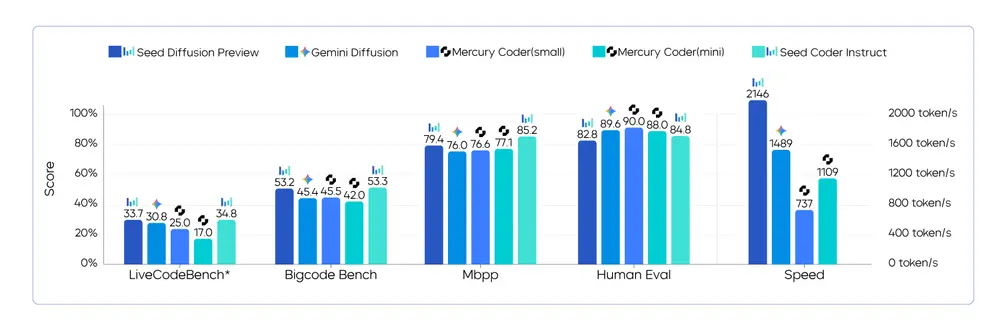
字节跳动 Seed 团队推出Seed Diffusion:打破自回归瓶颈,实现 5.4 倍代码生成加速字节跳动 Seed 团队近期发布了一款实验性语言模型——Seed Diffusion 预览版,它采用离散状态扩散机制,专注于代码生成任务,在推理速度上实现了显著突破:最高可达 2,146 token...大语言模型# Seed Diffusion# 字节跳动8个月前01490
RewardDance:用生成式奖励重塑视觉强化学习,让AI生成的图像和视频真正“理解”你的需求在视觉生成领域,强化学习(Reinforcement Learning, RL)正成为提升模型表现的关键手段。其中,奖励模型(Reward Model, RM)作为引导生成方向的核心组件,直接影响最终...新技术# RewardDance# 字节跳动7个月前01410
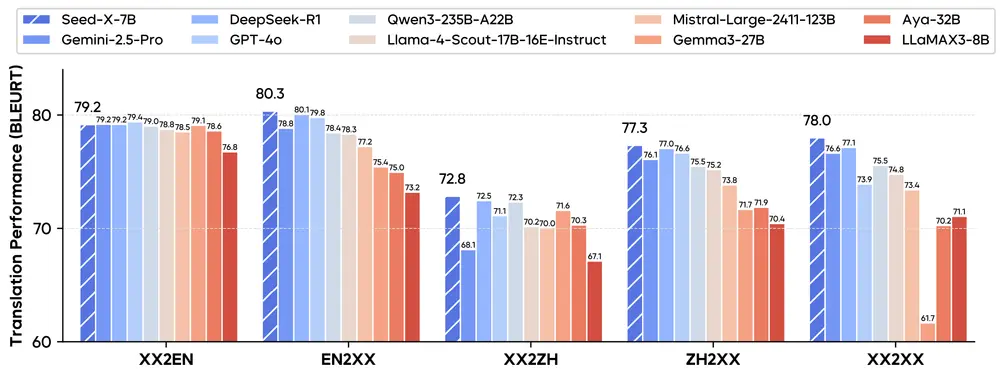
字节跳动开源 Seed-X:70亿参数的多语言翻译模型,性能媲美 GPT-4 和 Gemini字节跳动推出Seed-X,这是一个开源的多语言翻译模型系列,包括指令模型、强化学习模型和奖励模型,参数规模为 70亿(7B),却在翻译能力上展现出媲美甚至超越超大规模闭源模型(如 Gemini-2.5...大语言模型# SEED-X# 多语言翻译模型# 字节跳动9个月前01200
字节跳动Seed项目组推出基于大语言模型(LLM)的自动化定理证明系统 Seed-Prover字节跳动Seed项目组推出基于大语言模型(LLM)的自动化定理证明系统 Seed-Prover,Seed-Prover 通过结合 LLM 的推理能力和形式化语言(如 Lean)的验证能力,实现了对数学...大语言模型# Seed-Prover# 字节跳动# 自动化定理证明8个月前01040
清华大学 & 字节跳动联合推出 HuMo:一个以人为中心的多模态视频生成框架一段文字描述 + 一张人物照片 + 一段语音音频,能否生成一个口型同步、动作自然、形象一致的高质量人物视频? 现在,可以了。 清华大学与字节跳动智能创作团队合作推出 HuMo(Human-Centri...视频模型# HuMo# 字节跳动7个月前0990
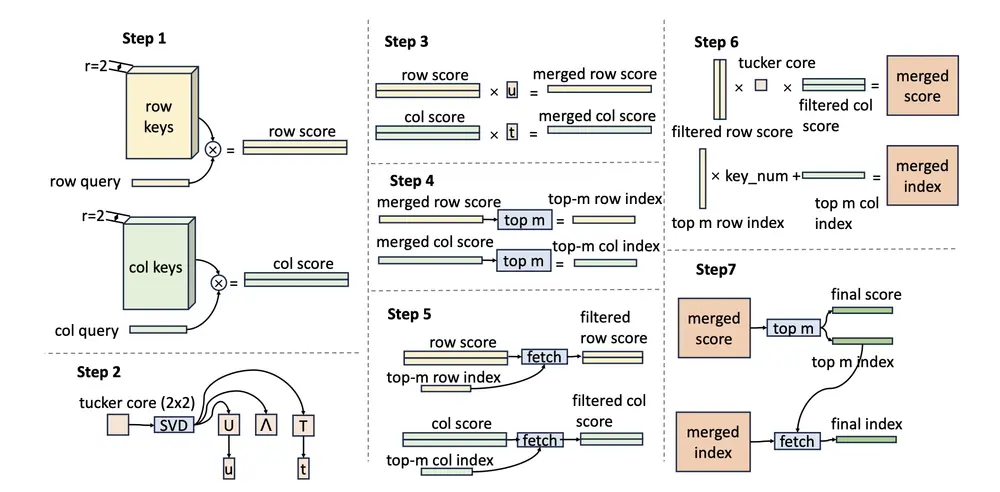
字节跳动推出 UltraMemV2:在低内存访问下,追平8专家MoE性能在大模型稀疏化架构的演进中,效率与性能的权衡始终是核心挑战。 MoE(Mixture of Experts)通过仅激活部分专家实现高效推理,但其频繁的跨专家参数访问带来了高昂的内存开销。为解决这一问题...新技术# UltraMemV2# 字节跳动7个月前0900
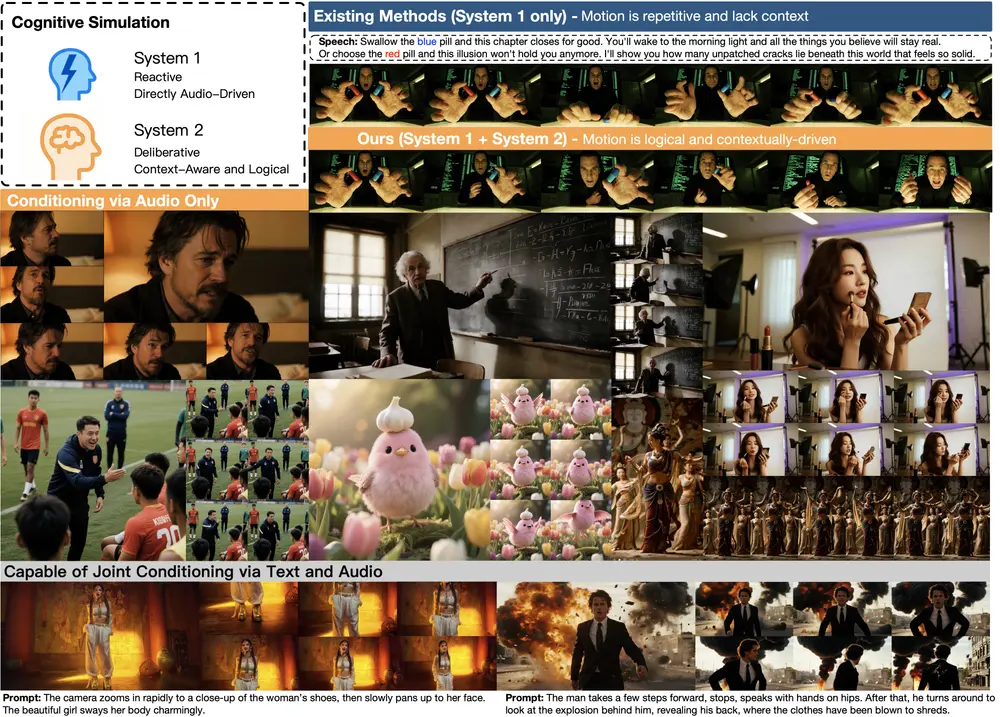
字节跳动发布OmniHuman-1.5:模拟人类双重认知,生成语义连贯的高逼真角色动画字节跳动近期推出新型视频角色生成框架 OmniHuman-1.5,核心突破在于模拟人类“系统1(快速直觉反应)+系统2(缓慢深思规划)”的双重认知过程,实现从“单一图像+语音轨道”到“物理逼真、语义连...视频模型# OmniHuman-1.5# 字节跳动7个月前0780
字节跳动旗下 AI 编程助手Trae 一周年福利:免费领 600~800 次「超快请求」额度字节跳动旗下 AI 编程助手 Trae 迎来上线一周年。为感谢用户支持,官方推出限时周年庆活动:登录 Trae 国际版,即可免费领取额外「Fast Request」(快速请求)额度,用于加速代码生成与...早报# AI 编程助手# Trae# 字节跳动2个月前0320
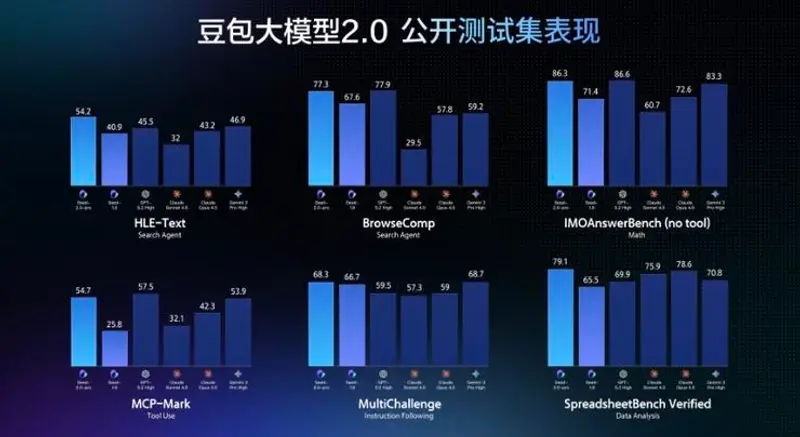
字节跳动发布豆包大模型2.0:数学推理顶尖,复杂任务执行强,API价格仅为竞品五分之一继 Seedance 2.0 视频模型和 Seedream 5.0 Lite 图像模型后,字节跳动于 2 月 14 日正式推出 豆包大模型 2.0(Doubao-Seed-2.0)系列。新版本针对大规...大语言模型早报# Doubao-Seed-2.0# 字节跳动# 豆包大模型2.02个月前0300
复杂运动、多模态参考、双声道音频!字节跳动正式发布Seedance 2.0:统一多模态架构, 支持导演级编辑的工业级音视频生成字节跳动正式推出新一代视频创作模型 Seedance 2.0。作为迭代升级后的重磅版本,它采用全新统一的多模态音视频联合生成架构,全面支持文本、图片、音频、视频四种模态输入,集成了当前行业内覆盖面最广...早报视频模型# Seedance 2.0# 字节跳动2个月前0160