字节跳动推出专注于提升多模态理解与推理能力的视觉-语言基础模型Seed1.5-VL字节跳动正式推出 Seed1.5-VL,这是一款专注于提升多模态理解与推理能力的视觉-语言基础模型。Seed1.5-VL 不仅在视觉和视频理解任务中表现出色,还在智能体相关任务及复杂推理挑战中展现了卓...多模态模型# Seed1.5-VL# 字节跳动# 视觉-语言基础模型11个月前05320
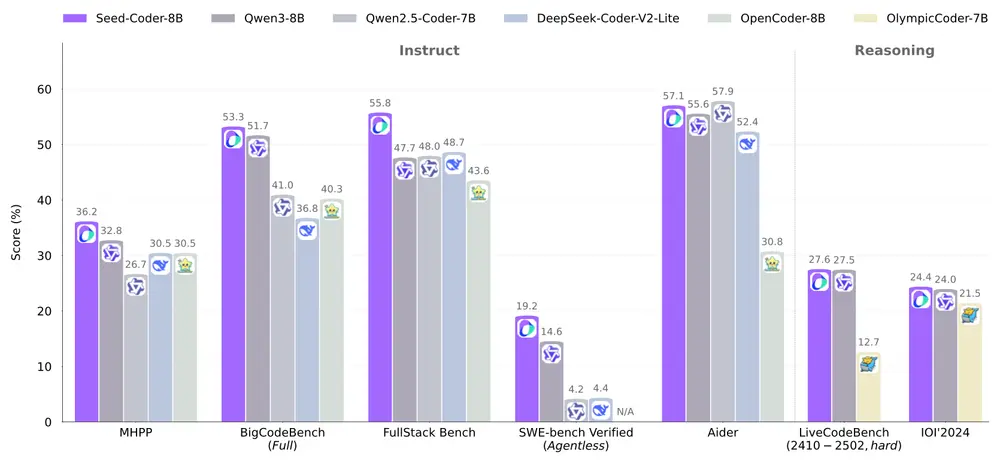
字节跳动推出Seed-Coder:轻量级开源代码大模型,性能媲美更大规模模型字节跳动近日发布了全新的开源代码大语言模型(LLM)系列——Seed-Coder,标志着其在开源大语言模型生态系统中的首次重要贡献。这一系列模型以轻量化和高性能为核心特点,包括基础模型、指令模型和推理...大语言模型# Seed-Coder# 代码大模型# 字节跳动11个月前04150
字节跳动推出新型图像编辑方法 SuperEdit :通过改进监督信号来提升基于指令的图像编辑性能字节跳动和佛罗里达中央大学计算机视觉研究中心的研究人员推出新型图像编辑方法 SuperEdit ,通过改进监督信号来提升基于指令的图像编辑性能。 项目主页:https://liming-ai.gith...图像模型# SuperEdit# 图像编辑# 字节跳动11个月前02920
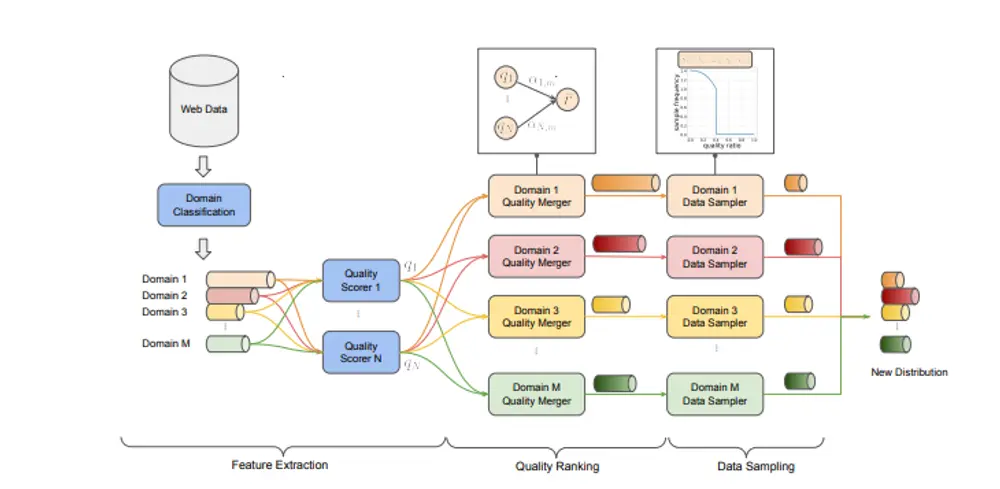
字节跳动推出统一优化数据质量与多样性的LLM预训练框架QuaDMix大语言模型(LLM)的性能和泛化能力在很大程度上依赖于其预训练数据的质量和多样性。然而,传统的数据整理方法往往将质量和多样性视为独立的目标,先进行质量过滤,再平衡领域分布。这种顺序优化忽略了两者之间的...新技术# QuaDMix# 字节跳动11个月前03890
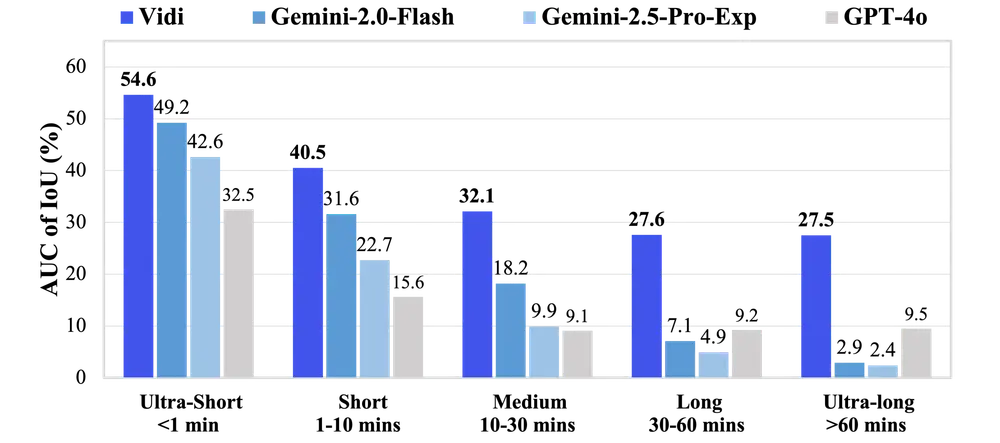
字节跳动推出多模态模型Vidi:专门用于视频理解和编辑字节跳动推出多模态模型Vidi,专门用于视频理解和编辑。Vidi 的主要目标是支持高质量、大规模视频内容的创作,通过处理原始输入材料(如未编辑的视频片段)和编辑组件(如视觉效果),帮助用户更高效地完成...多模态模型# Vidi# 多模态模型# 字节跳动11个月前02330
字节跳动旗下AI编程工具Trae带来一系列令人瞩目的更新:聊天与构建器的融合、上下文能力的拓展等字节跳动旗下AI编程工具Trae带来一系列令人瞩目的更新,这些改进将极大地提升开发体验,重塑 AI 开发的未来。 1. 聊天与构建器的融合 Trae v1.3.0版本将聊天(Chat)和构建器(Bui...早报# Trae# 字节跳动11个月前04070
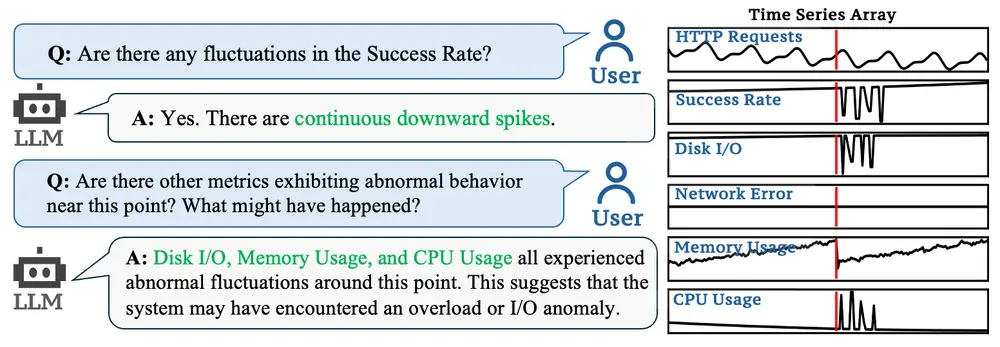
字节跳动推出多模态大语言模型ChatTS:专门用于时间序列分析清华大学和字节跳动的研究人员推出多模态大语言模型ChatTS ,专门用于时间序列分析。它通过自然语言命令帮助用户快速理解时间序列数据,执行日常任务,并处理复杂的推理问题。ChatTS 的核心优势在于其...多模态模型# ChatTS# 多模态大语言模型# 字节跳动12个月前02730
开源版GPT‑4o?新型多模态生成模型 Liquid,用一个模型搞定视觉与语言任务在OpenAI旗下GPT‑4o凭借原生生成及编辑图像功能,火爆网络后,大家都在期待有相对应的开源模型推出。而将视觉和语言任务高效整合一直是研究的热点。华中科技大学、字节跳动和香港大学的研究人员推出了新...图像模型# GPT‑4o# OpenAI# 多模态生成模型12个月前02700
字节跳动推出视频生成模型Seaweed-7B:以较低的计算成本实现高效的训练和生成近年来,随着视频生成技术的快速发展,如何在资源有限的情况下实现高性能的模型训练成为研究热点。字节跳动提出了一种创新的训练策略,推出了一个中等规模的视频生成模型——Seaweed-7B。这个模型拥有约7...视频模型# Seaweed-7B# 字节跳动# 视频生成模型12个月前02820
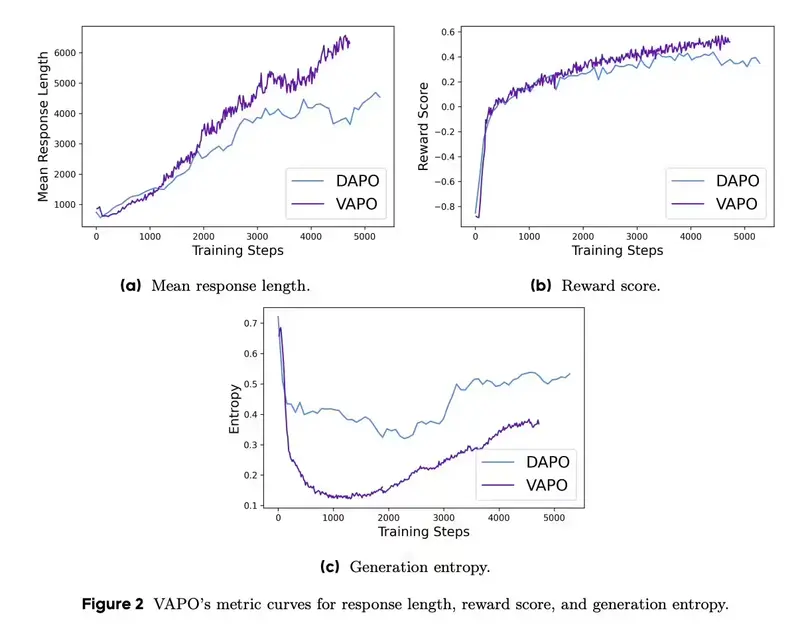
字节跳动推出VAPO框架:让大语言模型在复杂推理任务中更高效字节跳动Seed研究团队发布了一项名为 VAPO 的强化学习训练框架。这一框架专为提升大语言模型(LLM)在复杂、冗长任务中的推理能力而设计,特别是在数学推理和长链推理(Long Chain-of-T...新技术# VAPO# 大语言模型# 字节跳动12个月前05880
字节跳动推出基于Flux的通用框架UNO:支持虚拟试穿、风格化生成、产品设计等功能字节跳动近日推出了UNO,这是一个强大的通用框架,能够从单一主体到多主体进行定制化演进。UNO不仅展示了出色的泛化能力,还能将多样化的任务统一在一个模型之下,为图像生成领域带来了新的突破。 项目主页...图像模型# FLUX# UNO# 字节跳动12个月前06800
字节跳动推出基于DiT模型的人类图像动画框架DreamActor-M1:实现整体性、表现力和鲁棒性的人类图像动画生成字节跳动推出一个基于DiT模型的人类图像动画框架DreamActor-M1,实现整体性(holistic)、表现力(expressive)和鲁棒性(robust)的人类图像动画生成。该框架通过混合引导...新技术# DiT模型# DreamActor-M1# 字节跳动1年前02840