字节跳动与浙大联合发布轻量高效TTS模型MegaTTS3字节跳动和浙江大学的研究人员推出的一款轻量级TTS模型:MegaTTS3,0.45B,高质量语音克隆,支持中英文以及中英文混合,支持口音强度控制,后面会支持更细粒度的发音和时长调整。 GitHub:h...语音模型# MegaTTS3# TTS模型# 字节跳动1年前04840
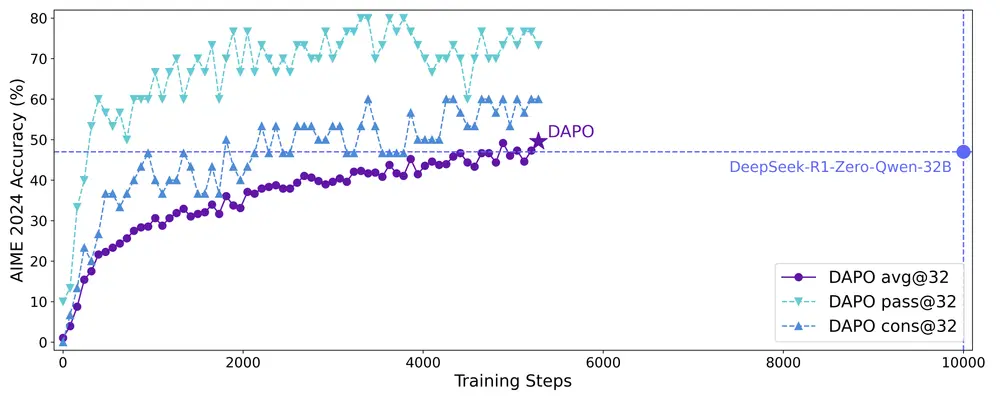
字节跳动发布DAPO(动态采样策略优化):提升大语言模型的推理能力来自字节跳动、清华大学和香港大学的研究团队共同推出了一款名为 DAPO(动态采样策略优化)的开源系统,旨在提升大语言模型(LLM)的推理能力。DAPO 的发布标志着在强化学习(RL)技术应用于大规模语...新技术# DAPO# 动态采样策略优化# 大语言模型1年前02640
字节跳动推出新型框架 InfiniteYou (InfU):用于在保留个人身份特征的前提下,通过自由形式的文本描述重新创作照片字节跳动推出新型框架 InfiniteYou (InfU),用于在保留个人身份特征的前提下,通过自由形式的文本描述重新创作照片。该框架利用先进的扩散变换器(Diffusion Transformers...图像模型# InfiniteYou# InfU# 字节跳动1年前01960
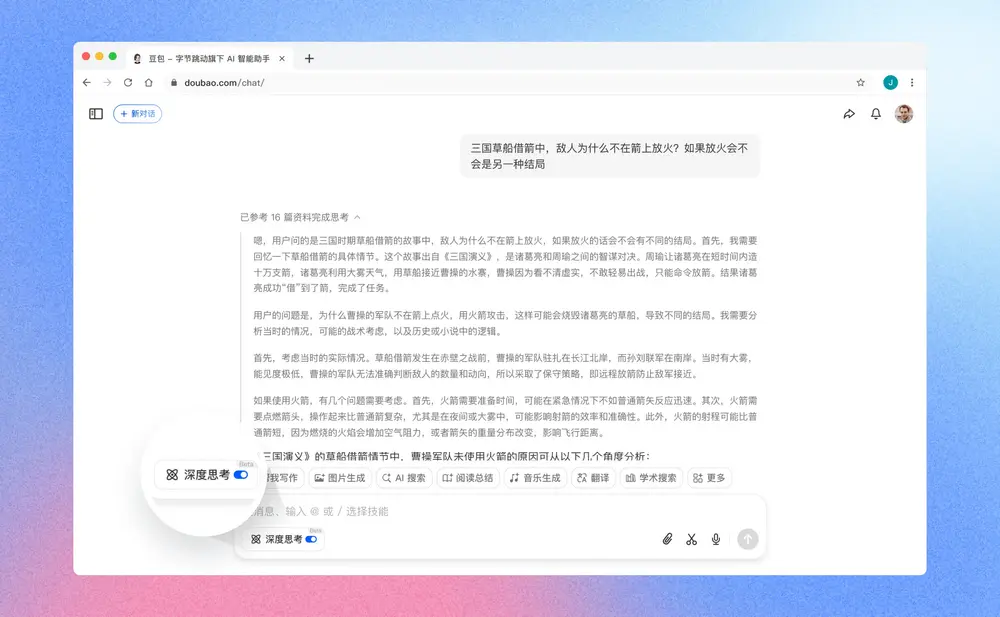
字节跳动旗下AI助手豆包上线「深度思考」推理模式在2025年3月5日,字节跳动旗下的AI助手豆包宣布正式上线了名为「深度思考」的推理模式。这一更新全面覆盖了问答、搜索、写作和阅读等应用场景,旨在为用户提供更加透明和详细的AI决策过程展示。用户只需简...早报# 字节跳动# 推理模式# 深度思考1年前03800
字节跳动推出统一的视频生成框架Phantom :通过跨模态对齐实现主体一致性的视频生成字节跳动的研究人员推出一个统一的视频生成框架Phantom ,通过跨模态对齐实现主体一致性的视频生成(Subject-to-Video, S2V),用于单主体和多主体参考,构建在现有的文本到视频和图像...新技术# Phantom# 字节跳动# 视频生成11个月前02960
字节跳动推出基于修正流Transformer 架构的新型图像和视频生成模型家族Goku香港大学和字节跳动的研究人员推出新型图像和视频生成模型家族Goku,它基于修正流Transformer 架构,实现了行业领先的图像和视频联合生成性能。Goku 的目标是通过高质量的视觉内容生成,推动媒...视频模型# Goku# 字节跳动# 视频生成1年前05080
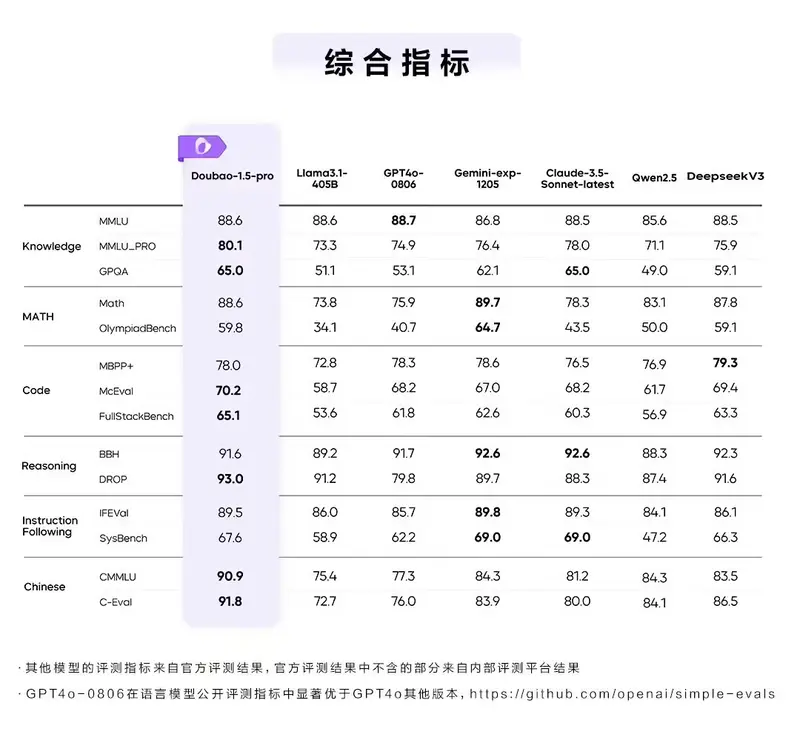
字节跳动发布豆包大模型 1.5 Pro,性能超越 GPT-4o 和 Claude 3.5 Sonnet字节跳动今日正式发布了其最新的豆包大模型 1.5 Pro(Doubao-1.5-pro),该模型在多个测评基准上,包括知识、代码、推理和中文等方面,展现了优于 GPT-4o 和 Claude 3.5 ...早报# 字节跳动# 豆包大模型 1.5 Pro1年前03270
字节跳动推出新型单目深度估计方法Video Depth Anything:专门用于超长视频(数分钟)的高质量、一致的深度估计字节跳动推出新型单目深度估计方法Video Depth Anything,专门用于超长视频(数分钟)的高质量、一致的深度估计。该方法基于 Depth Anything V2,通过引入高效的空间-时间头...新技术# Video Depth Anything# 字节跳动1年前02660
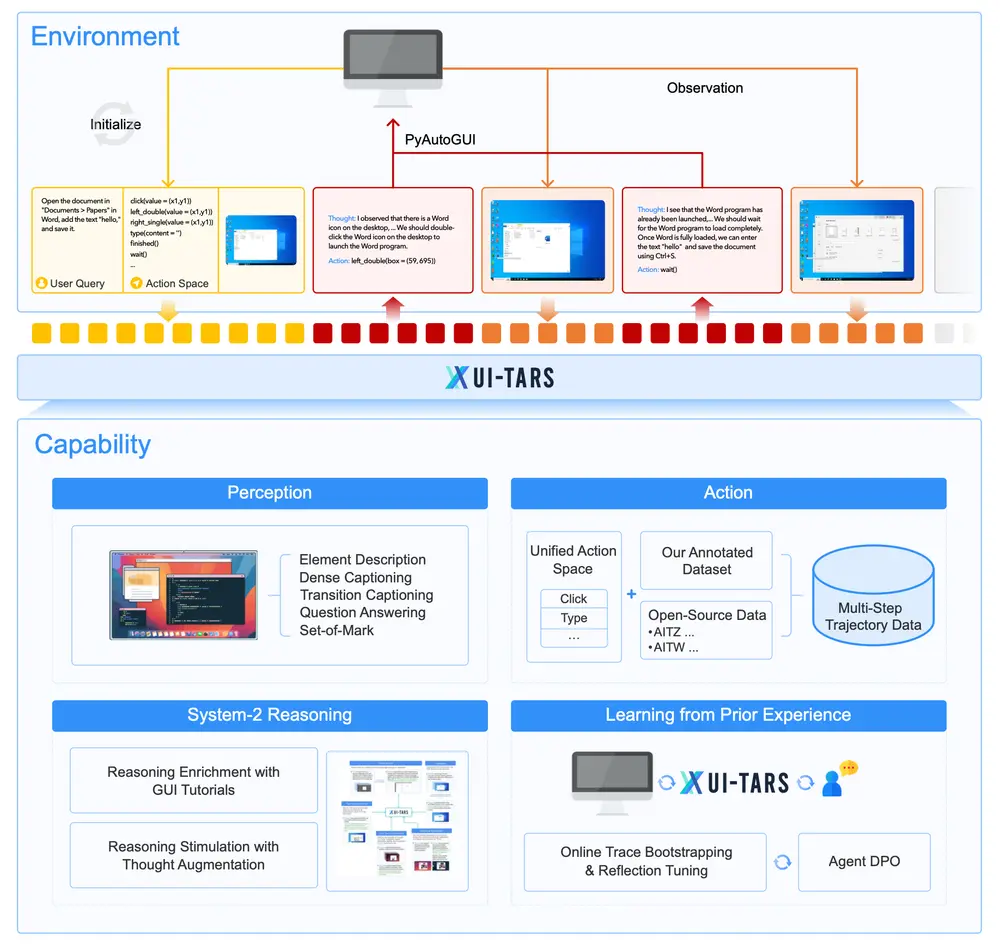
新型自动化 GUI交互模型 UI-TARS:能够通过感知屏幕截图作为输入,并执行类似人类操作的交互任务(如键盘输入和鼠标操作)字节跳动与清华大学的研究人员推出新型自动化 GUI(图形用户界面)交互模型 UI-TARS,它是一种原生的 GUI 代理模型,能够通过感知屏幕截图作为输入,并执行类似人类操作的交互任务(如键盘输入和鼠...多模态模型# UI-TARS# 字节跳动12个月前03800
字节跳动推出视频生成模型训练新方法APT:通过在扩散预训练的基础上对真实数据进行对抗训练,以实现一步视频生成扩散模型在图像和视频生成领域展示了卓越的能力,但其迭代性质导致了生成过程缓慢且计算成本高昂。尽管现有的蒸馏方法尝试通过一步生成来解决这一问题,但往往伴随着显著的生成质量下降。为了解决这些挑战,字节跳动...新技术# APT# Seaweed-APT模型# 字节跳动1年前02690
字节跳动推出新型图像分词器TA-TiTok及掩码生成模型MaskGen字节跳动和浦项科技大学的研究人员提出了一种名为TA-TiTok的新型图像分词器。这是一种基于Transformer架构的文本感知一维分词器,能够高效处理离散或连续的一维标记。基于TA-TiTok的成功...新技术# MaskGen# TA-TiTok# 字节跳动1年前02710
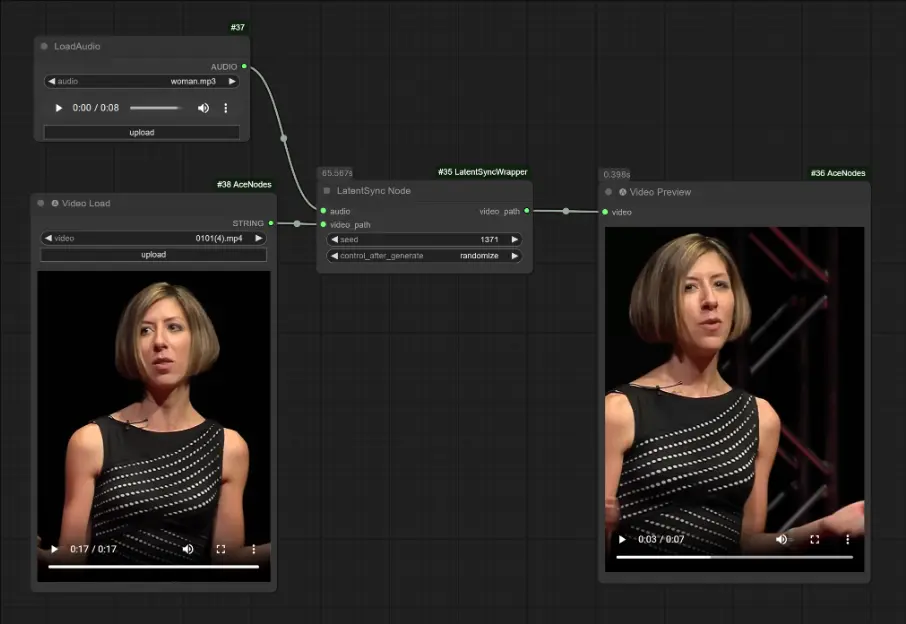
ComfyUI-LatentSyncWrapper:基于字节跳动唇音同步框架LatentSync的非官方ComfyUI节点ComfyUI-LatentSyncWrapper是专门为ComfyUI设计的非官方节点,基于字节跳动的LatentSync框架,实现视频中嘴唇动作与音频输入的同步。借助这一工具,用户可以在Comfy...插件# LatentSync# LatentSync 1.5# 唇音同步1年前01,7000