UFC:韩国科学技术院推出的通用少样本图像控制适配器在文本到图像生成领域,如何让预训练模型快速适应新的空间控制条件(如边缘图、深度图、人体姿态等),一直是一个挑战。传统方法通常需要大量标注数据和高昂的训练成本,限制了其灵活性与实用性。 GitHub:h...图像模型# UFC# 图像控制适配器5个月前01280
RecA:一种高效提升统一多模态模型图像生成能力的后训练方法近年来,统一多模态模型(Unified Multimodal Models, UMMs)因其在视觉理解与生成任务中的双重能力而受到广泛关注。这类模型旨在通过单一架构实现对图像和文本的联合建模,既能“看...图像模型# RecA# 统一多模态模型5个月前02270
FLUX-Reason-6M & PRISM-Bench:600 万级 T2I 推理数据集 + 七轨道基准,开源模型研发新助力在文本到图像(Text-to-Image, T2I)生成领域,一个长期存在的困境是:开源模型越做越像,却始终难以真正“理解”复杂指令。 问题不在架构,而在数据与评估 —— 缺乏大规模、注重语义推理的训...图像模型# FLUX-Reason-6M# PRISM-Bench5个月前01230
腾讯混元联合高校提出 Direct-Align:用“一步恢复”实现扩散模型的高效偏好对齐在文生图模型日益成熟的今天,提升生成质量已不再是唯一目标——如何让图像真正符合人类的审美偏好,成为更高阶的挑战。 现有方法通常依赖强化学习或可微奖励机制,将模型输出与人类偏好对齐。但这些方法普遍存在两...图像模型# Direct-Align# flux.1-dev-SRPO# 腾讯混元5个月前01810
字节跳动开源UMO:统一多身份优化框架,让AI准确“认出”每个人在图像定制领域,个性化生成已逐渐从“一个人一个风格”迈向“多人协同场景”的复杂需求。然而,当一张图中需要同时呈现多个真实人物时,模型常常出现“张冠李戴”——面部特征混淆、身份错位,导致输出失真。这不仅...图像模型# UMO# 字节跳动5个月前03590
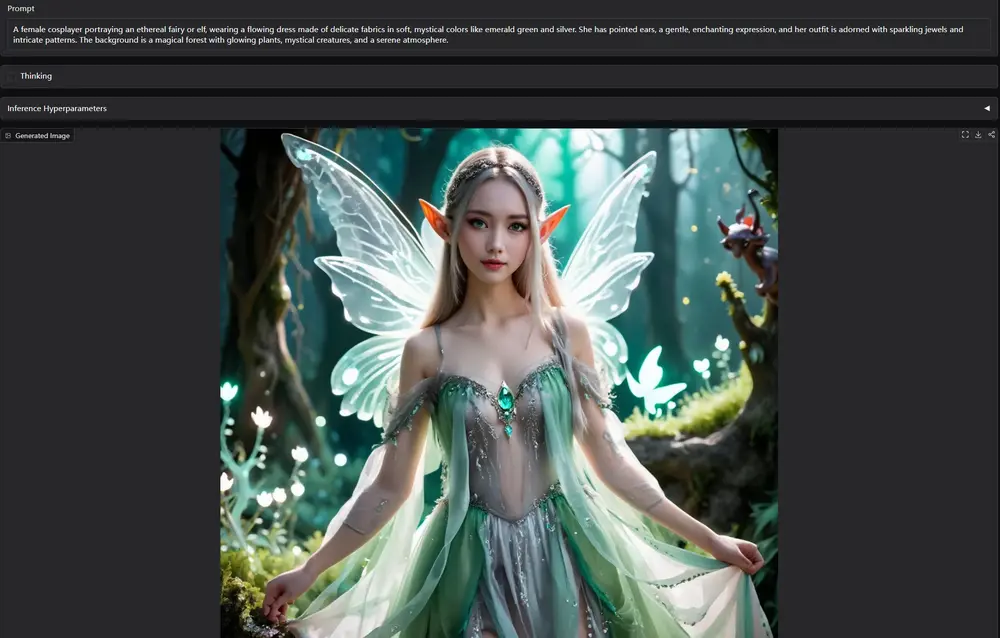
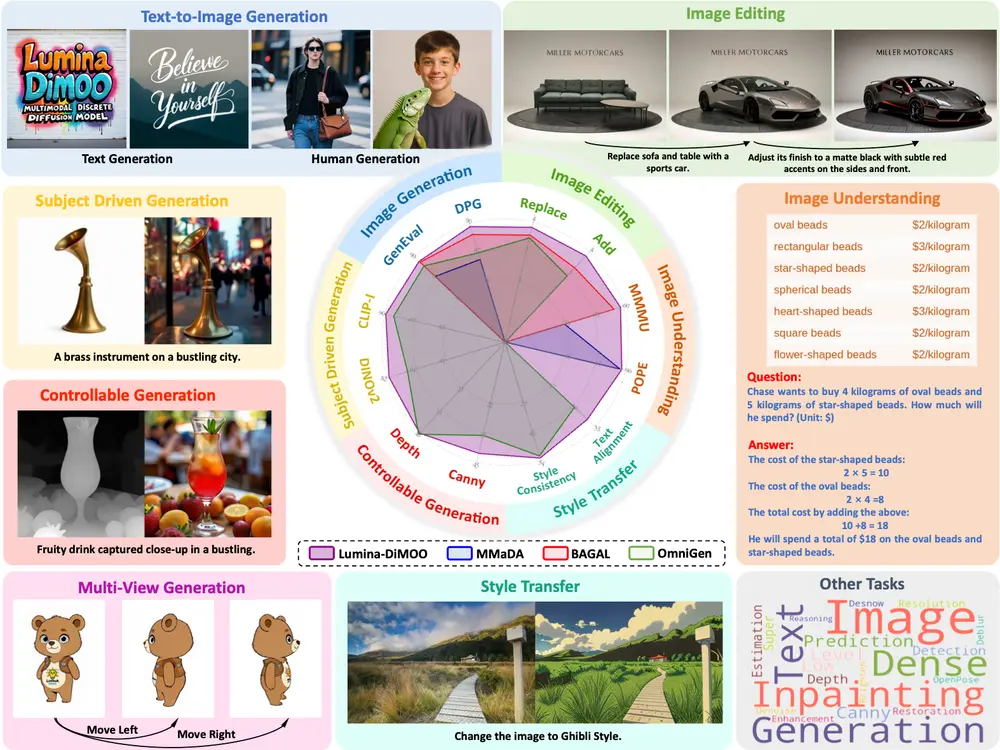
中国团队推出 Lumina-DiMOO:支持生成与理解的全能多模态模型由上海人工智能实验室牵头,联合上海创智学院、上海交通大学、悉尼大学、南京大学、香港中文大学和清华大学的研究团队,共同推出 Lumina-DiMOO ——一个面向多模态生成与理解一体化的新型基础模型。 ...图像模型# Lumina-DiMOO# 多模态模型5个月前02190
字节跳动发布 Seedream 4.0:首次支持多模态生图,同一模型实现 文生图、图像编辑、组图生成字节跳动正式推出 Seedream 4.0(即梦图片4.0),新一代图像创作模型。该模型在前代 Seedream 3.0 和 SeedEdit 3.0 的基础上,全面增强逻辑理解与多模态推理能力,首次...图像模型# Seedream 4.0# 即梦图片4.0# 字节跳动5个月前03440
腾讯混元开源 HunyuanImage 2.1:支持 2K 分辨率的高效文生图模型腾讯混元项目组正式开源HunyuanImage 2.1,一款支持 2048×2048 超高分辨率(2K)生成的文生图模型。该模型在语义对齐、细节控制与推理效率方面实现显著提升,具备电影级构图能力,并原...图像模型# HunyuanImage 2.1# 文生图模型5个月前03850
突破 SD3.5/FLUX.1!TiM模型实现少步高效与多步高质无缝衔接来自香港中文大学MMLab、上海人工智能实验室和悉尼大学的研究团队,推出了一款名为Transition Models (TiM) 的新型生成模型。该模型通过重构生成学习的核心目标,成功破解了生成模型领...图像模型# Transition Models# 生成模型6个月前02290
Drawing2CAD:一键把二维工程图转成三维参数化 CAD 模型在工业设计、机械工程、产品开发领域,有一个长期存在的“效率瓶颈”: 设计师画好了二维工程图 → 工程师手动在 CAD 软件里重建三维模型 → 耗时、易错、难迭代。 现在,这个问题有了一个自动化解法 ...图像模型# CAD 模型# Drawing2CAD6个月前04650
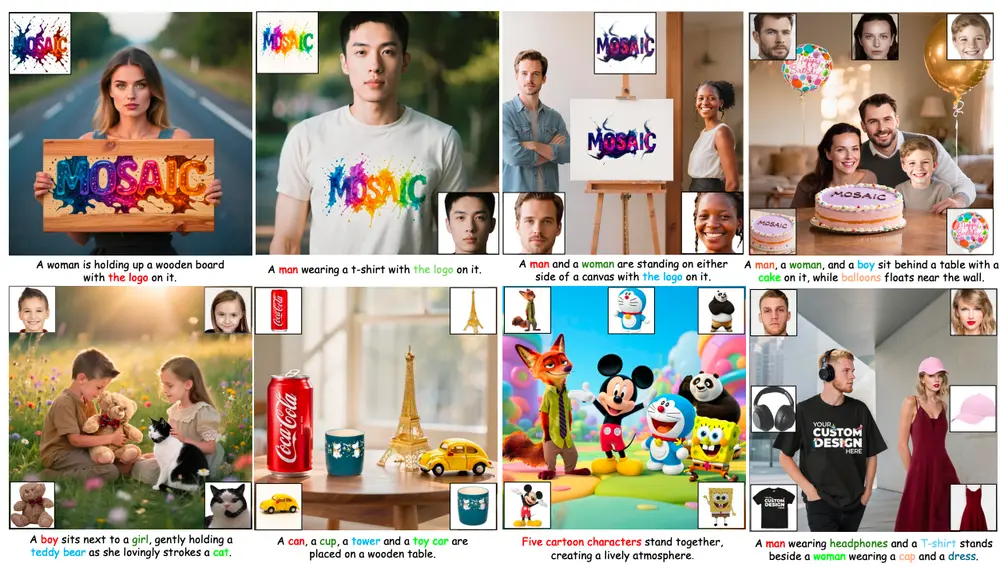
MOSAIC:通过语义对齐与特征解耦实现高保真的多主体个性化生成在个性化图像生成任务中,我们常常希望将多个参考主体(如人物、动物、物体)的特征融合到一张新图像中——例如,“让A的脸型、B的发型、C的表情和D的服饰出现在同一人身上”。这类任务被称为多主体个性化生成...图像模型# MOSAIC# 个性化生成6个月前01550
基于图像编辑模型的 FE2E:革新单目密集几何预测在单目深度估计、表面法线预测等密集几何预测任务中,如何在有限标注数据下实现高精度的零样本泛化,一直是三维视觉的核心挑战。 近年来,研究者尝试利用文本到图像生成模型(如Stable Diffusion...图像模型# FE2E# 图像编辑6个月前02690