高效且多功能的框架Ctrl-Adapter:在各种图像和视频生成模型中加入丰富的控制功能北卡罗来纳大学教堂山分校的研究人员推出高效且多功能的框架CTRL-Adapter,它能够为任何图像或视频扩散模型添加多样的空间控制功能。它支持多种实用的应用,如视频控制、多条件视频控制、稀疏帧条件下的...图像模型# Ctrl-Adapter# 空间控制# 视频生成模型12个月前08380
Stability AI推出新模型Stable Cascade关键要点摘要: Stable Cascade模型发布: 今天,Stability AI推出了基于Würstchen架构的文生图模型Stable Cascade,并仅允许在非商业许可下使用,限定于非商业...图像模型# Stability AI# Stable Cascade# 模型12个月前08190
开源版GPT-4o!字节跳动开源新一代多模态模型 BAGEL:多模态理解、图像生成、图像编辑,还能“思考”字节跳动发布了一款名为 BAGEL 的开源多模态基础模型,该模型拥有 70 亿活跃参数(总规模为 140 亿),在大规模交错多模态数据上进行训练。BAGEL 不仅在标准多模态理解排行榜中超越了当前主流...图像模型# BAGEL# GPT-4o# 多模态模型8个月前07950
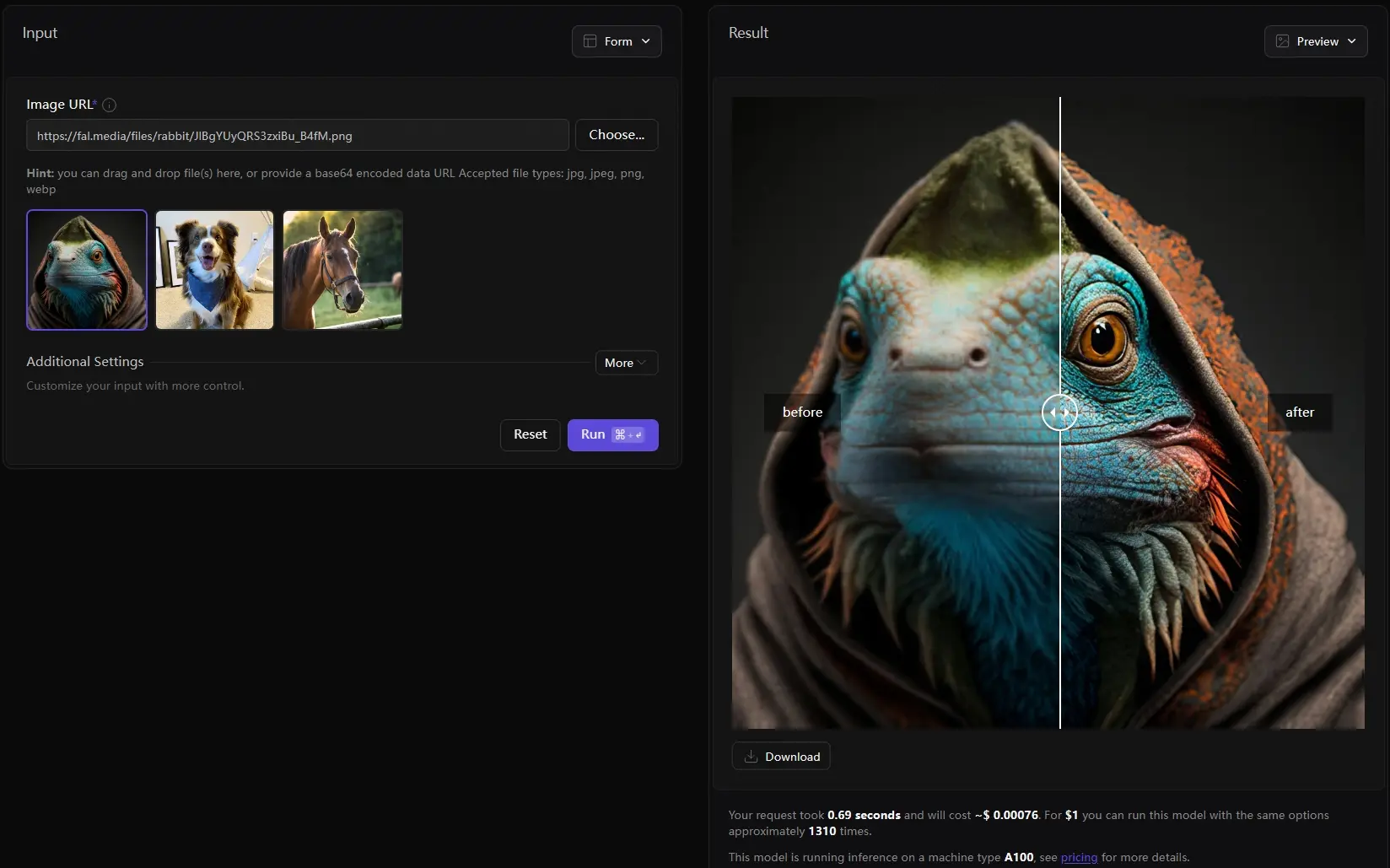
基于扩散模型(SDXL)的新型图像恢复方法InstantIR盲图像恢复(Blind Image Restoration, BIR)的主要挑战之一是处理测试时未知的退化,这需要模型具备高泛化能力。北京大学、InstantX团队和香港中文大学的研究人员提出了一种新...图像模型# InstantIR# 即时参考图像恢复# 高清修复12个月前07940
新型文生图框架Ranni:利于大语言模型,更准确地理解和执行复杂的文本提示阿里巴巴和蚂蚁集团推出新型文生图框架Ranni,Ranni的核心特点是它能够更准确地理解和执行复杂的文本提示,尤其是那些包含数量描述、对象属性绑定和多主题描述的提示。这使得Ranni在生成图像时能够更...图像模型# Ranni# 文生图模型12个月前07810
新型文生图框架SANA:能够高效地生成高达4096×4096分辨率的高清晰度图像英伟达、麻省理工学院和清华大学的研究人员推出新型文本到图像生成框架SANA,它能够高效地生成高达4096×4096分辨率的高清晰度图像。SANA的核心优势在于它不仅生成的图像质量高,而且与文本的匹配度...图像模型# SANA# 文生图框架12个月前07790
Stable Diffusion XL(SDXL)Stability AI于北京时间2023年 7 月 27 日正式发布 Stable Diffusion XL 首个正式版 1.0,SDXL 1.0 能生成更加鲜明准确的色彩,在对比度、光线和阴影方面...图像模型# AI绘画# SDXL# Stable Diffusion XL12个月前07530
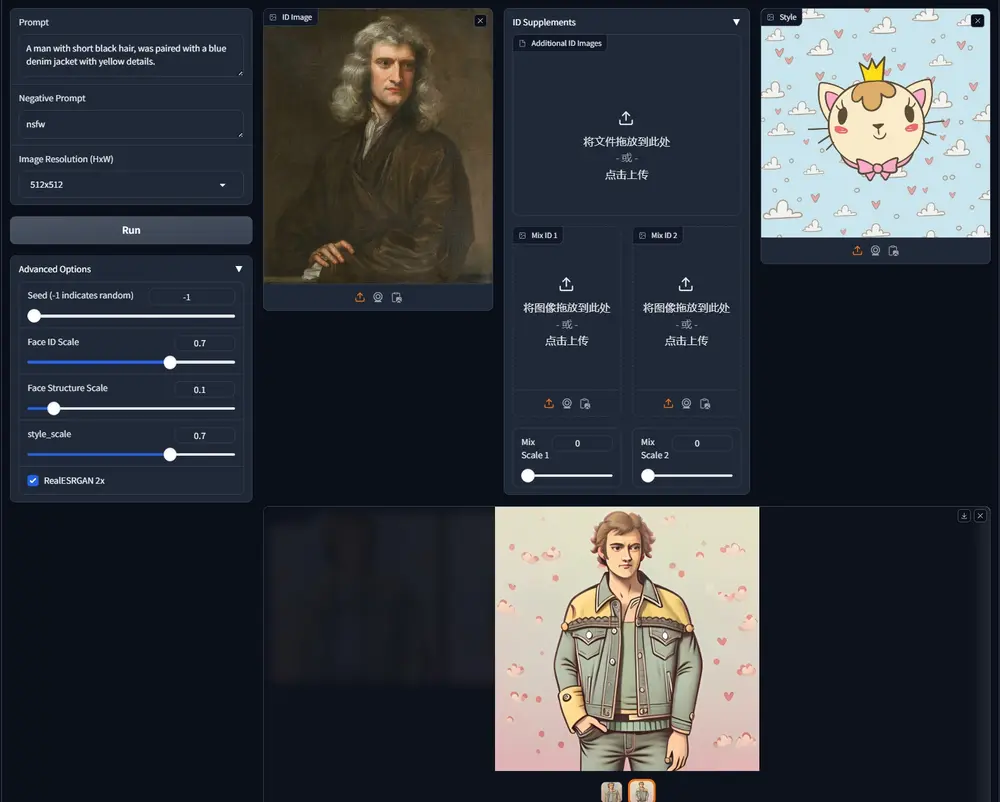
人像个性化框架UniPortrait:支持单人物(Single-ID)和多人物(Multi-ID)图像的定制化生成阿里巴巴集团智能计算研究院推出人像个性化框架UniPortrait,支持单人物(Single-ID)和多人物(Multi-ID)图像的定制化生成。简单来说,UniPortrait能够根据用户提供的文本...图像模型# UniPortrait# 人像个性化12个月前07510
统一框架UniFL:通过统一的反馈学习来提升稳定扩散模型(Stable Diffusion)的性能来自字节跳动和中山大学的研究人员推出利用反馈学习机制来全面增强扩散模型的统一框架UniFL,它通过统一的反馈学习来提升稳定扩散模型(Stable Diffusion)的性能。UniFL作为一种通用、高...图像模型# Stable Diffusion# UniFL12个月前07500
Fal.ai平台推出了新一代GAN 图像放大工具AuraSR的第二版AuraSR-v2Fal.ai平台推出了新一代GAN 图像放大工具AuraSR的第二版,上个月它们推出了AuraSR 第一版后,得到了开源社区积极回应,让他们立刻着手开发新版。AuraSR 以 Adobe 的 Giga...图像模型# AuraSR# AuraSR-v2# Fal.ai12个月前07380
以Stable Cascade为基础!新型超高分辨率图像生成方法UltraPixel:生成从1K至6K多种分辨率的高品质图像 香港科技大学(广州)、 华为诺亚方舟实验室、马克斯普朗克信息研究所和香港科技大学的研究人员推出一种新型超高分辨率图像生成方法UltraPixel,此方法是以Stability AI的模型Stable...图像模型# Stable Cascade# UltraPixel# 超高分辨率图像生成12个月前07150
新型多模态自回归模型Lumina-mGPT:能够执行各种视觉和语言任务,尤其擅长根据文本描述生成逼真的图片上海人工智能实验室和香港中文大学的研究人员推出新型多模态自回归模型Lumina-mGPT,它能够执行各种视觉和语言任务,尤其擅长根据文本描述生成逼真的图片。与现有的基于自回归的图像生成方法不同,Lum...图像模型# Lumina-mGPT# 多模态自回归模型12个月前07120