Science-T2I框架:通过整合科学知识,提升图像合成模型生成图像的现实感和科学一致性纽约大学、华盛顿大学、宾夕法尼亚大学和 加州大学圣地亚哥分校介绍了一个名为 Science-T2I 的框架,旨在通过整合科学知识,提升图像合成模型生成图像的现实感和科学一致性。该研究的核心是解决现有图...图像模型# Science-T2I# 图像生成模型# 科学10个月前03190
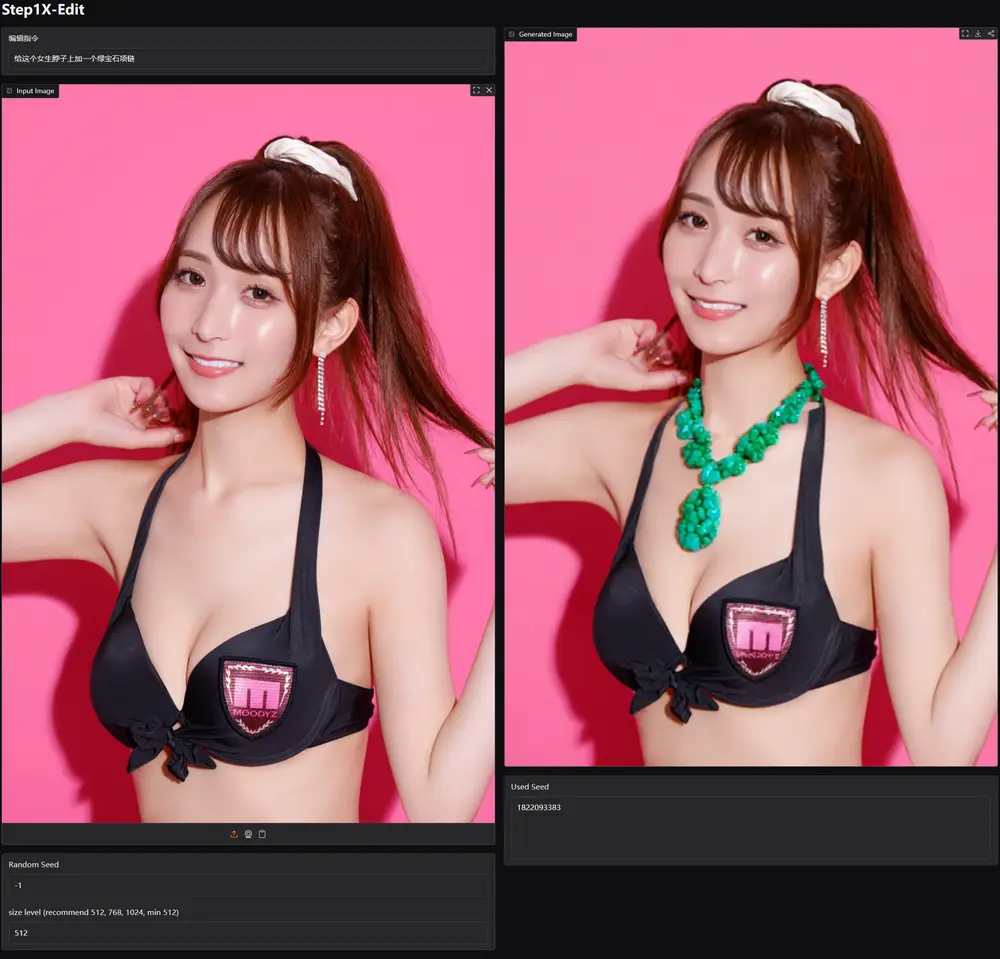
阶跃星辰推出新型通用图像编辑模型Step1X-Edit 阶跃星辰推出新型通用图像编辑模型Step1X-Edit ,图像编辑与自然语言指令结合已成为视觉-语言研究中日益重要的任务。用户可以通过直观的自然语言指令来编辑图像,但这在技术上带来了独特的挑战,例如理...图像模型# Step1X-Edit# 图像编辑模型# 阶跃星辰10个月前03630
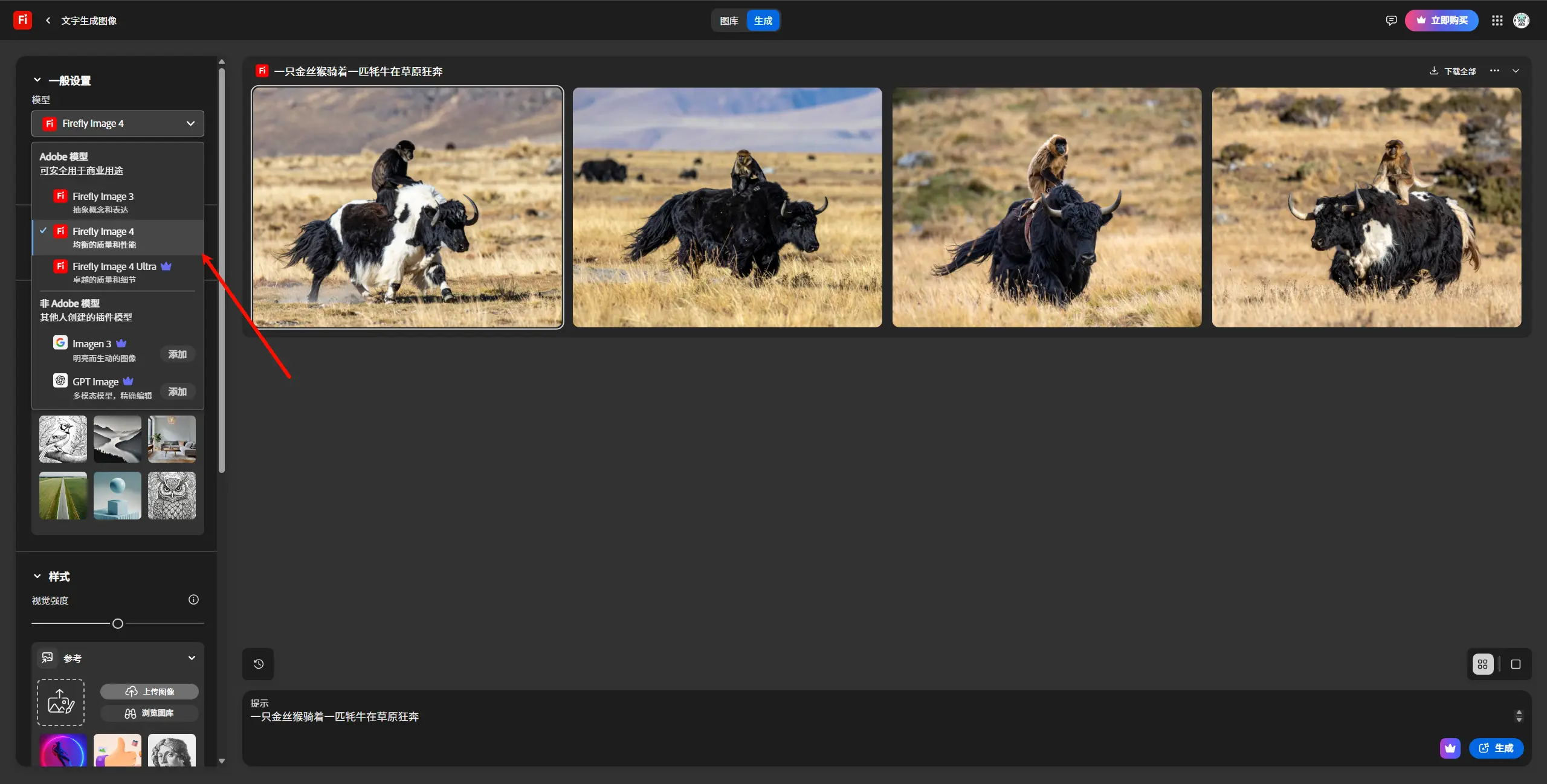
Adobe 推出 Firefly 系列新模型与重新设计的 Web 应用Adobe 在生成式 AI 领域再次迈出重要一步,推出了 Firefly 系列图像生成模型的最新迭代版本、一个全新的 矢量生成模型(Firefly Vector Model),以及一个经过重新设计的 ...图像模型# Adobe# Firefly Image 4# Image 4 Ultra10个月前03760
Flex.2-preview:基于 Flux.1 Schnell 微调而成的开源 80 亿参数文生图模型Flex.2-preview 是一款开源的文本到图像扩散模型,具有 80 亿参数,支持通用控制和图像修复功能。它基于 Flux.1 Schnell 微调而成,旨在为用户提供更灵活、更强大的图像生成能力...图像模型# Flex.2-preview# FLUX.1 [schnell]# 文生图模型10个月前06950
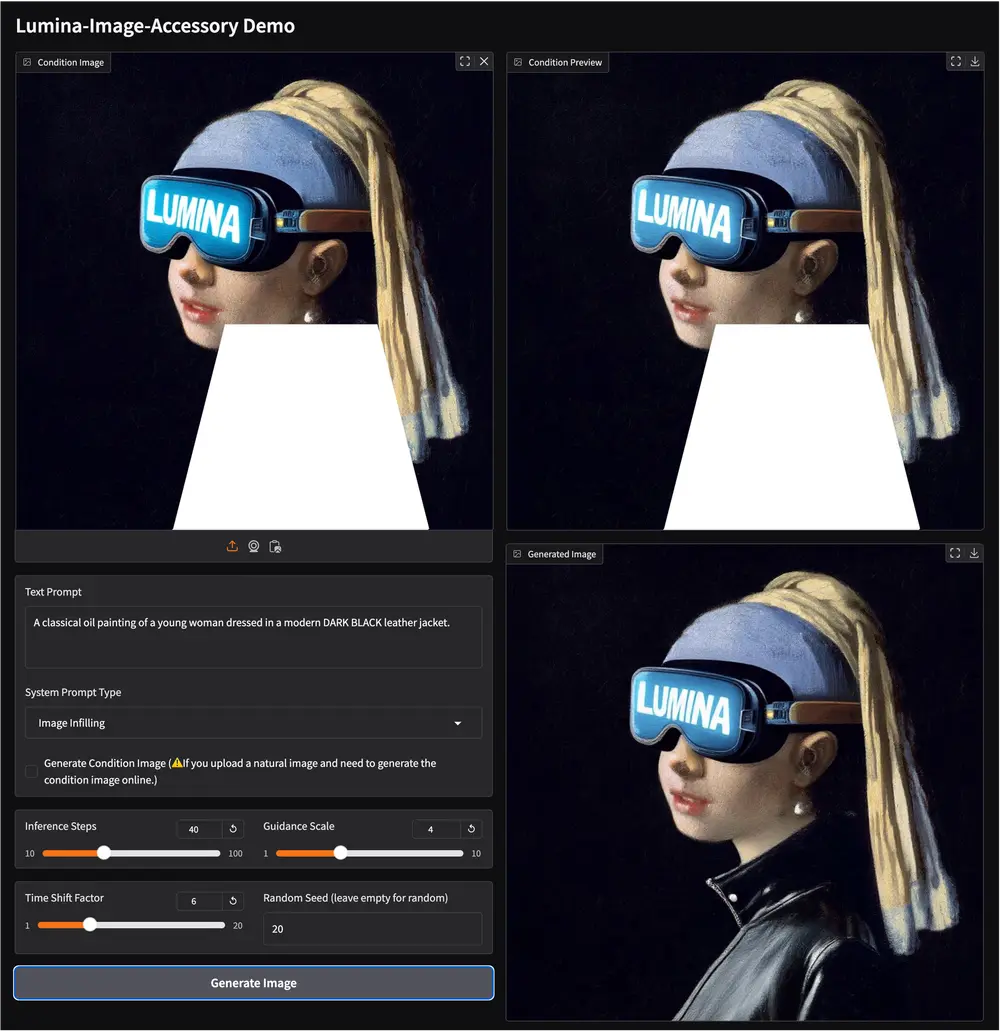
Lumina-Accessory:专为 Lumina 系列模型设计的多任务指令微调框架Lumina-Accessory 是一个专为 Lumina 系列模型设计的多任务指令微调框架,目前支持 Lumina-Image-2.0。该框架通过一系列创新设计,为图像生成和编辑任务提供了强大的支持...图像模型# Lumina-Accessory# Lumina-Image 2.0# 图像生成10个月前03470
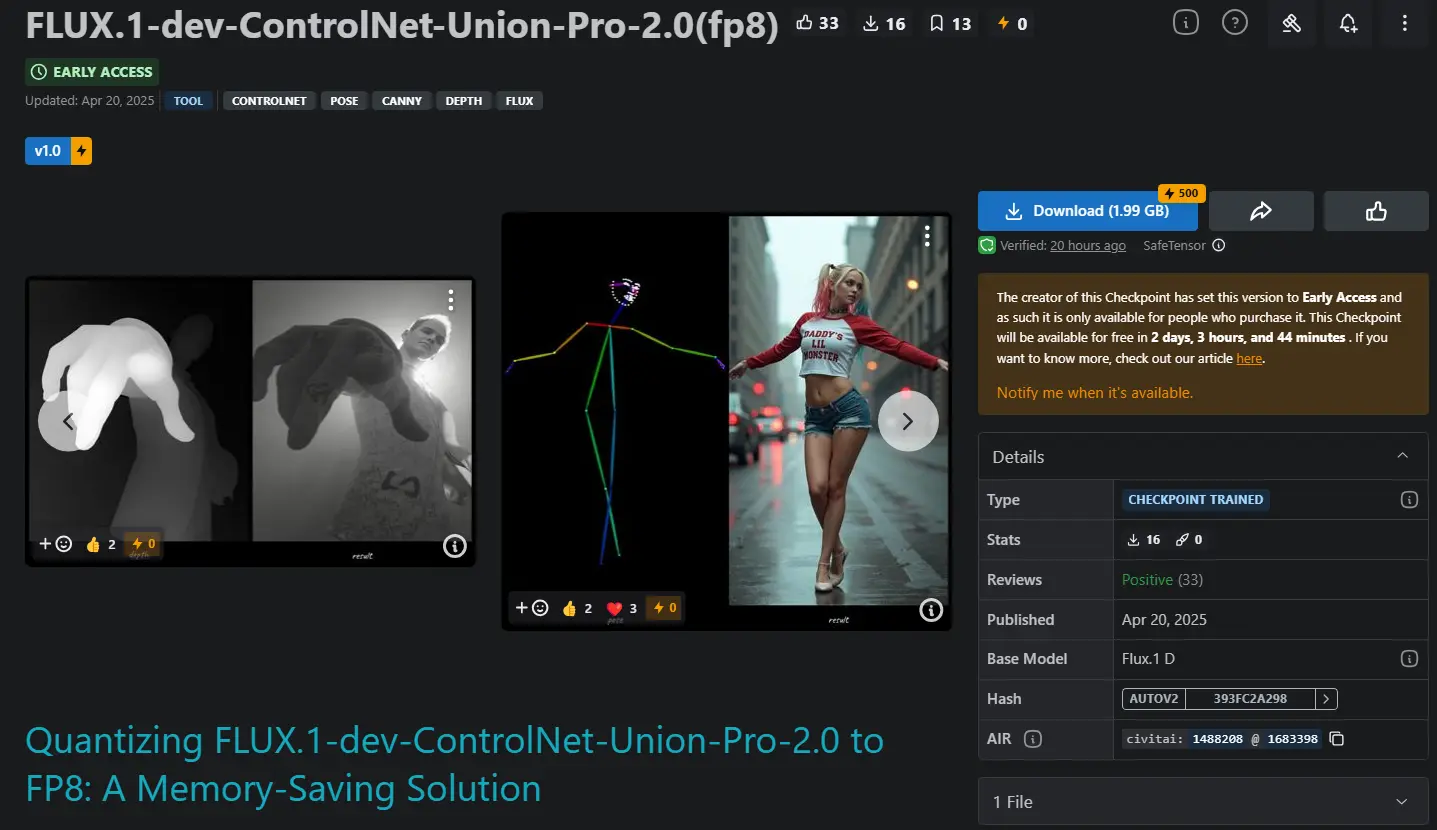
FLUX.1-dev-ControlNet-Union-Pro-2.0 FP8 量化版本:降低对于显存的需求近期Shakker Labs发布了FLUX.1-dev-ControlNet-Union-Pro-2.0,但原版模型对于显存要求过高,于是就有开发者推出了FP8 量化版本。这不是一个经过微调的模型,而...图像模型# FLUX.1-dev-ControlNet-Union-Pro-2.0# FP8 量化版本# Shakker Labs10个月前06780
基于蒸馏的多功能图像生成模型DMM:通过蒸馏模型合并技术实现多功能图像生成在文本到图像(Text-to-Image, T2I)生成领域,开发者通常会基于强大的基础模型(如Stable Diffusion 1.5)进行微调,以适应特定风格或场景的需求。例如,某些模型专注于生成...图像模型# DMM# 图像生成模型# 蒸馏模型10个月前02530
对角蛇形扫描自回归图像生成框架DAR:用于生成高质量图像的新型自回归模型传统的自回归图像生成方法(如VQGAN)通常按照光栅扫描(raster scan)顺序生成图像令牌。这种方式在行末换行时会导致相邻令牌之间的欧几里得距离过大,从而影响生成效果。例如,当生成一张256...图像模型# DAR# 自回归模型10个月前02630
基于Flux模型的创新角色生成框架InstantCharacter:单张图像生成高质量角色图像腾讯混元团队与InstantX团队近日联合推出了一种全新的角色定制方法——InstantCharacter。这一方法无需调优,仅通过单张图像即可实现高保真、文本可控且角色一致的图像生成,支持多种下游任...图像模型# FLUX模型# InstantCharacter# InstantX10个月前05540
开源版GPT‑4o?新型多模态生成模型 Liquid,用一个模型搞定视觉与语言任务在OpenAI旗下GPT‑4o凭借原生生成及编辑图像功能,火爆网络后,大家都在期待有相对应的开源模型推出。而将视觉和语言任务高效整合一直是研究的热点。华中科技大学、字节跳动和香港大学的研究人员推出了新...图像模型# GPT‑4o# OpenAI# 多模态生成模型10个月前02650
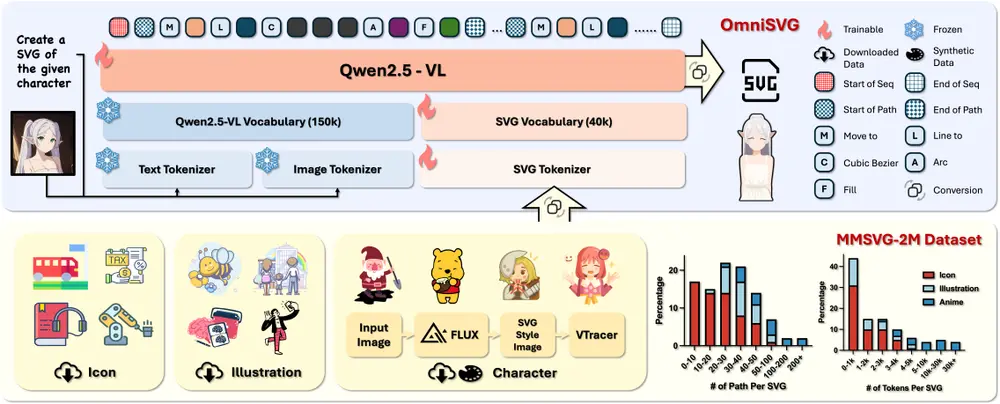
基于视觉语言模型的端到端多模态 SVG 生成框架OmniSVG:能够生成从简单图标到复杂动漫角色的高质量 SVG 图形复旦大学和阶跃星辰的研究人员推出基于视觉语言模型(VLMs)的端到端多模态 SVG 生成框架OmniSVG,能够生成从简单图标到复杂动漫角色的高质量 SVG 图形,支持文本到 SVG、图像到 SVG ...图像模型# OmniSVG# SVG# 视觉语言模型7个月前02530
基于像素空间流的图像生成模型PixelFlow:根据给定的文本描述生成高质量、语义一致的图像香港大学和Adobe的研究人员推出基于像素空间流的图像生成模型PixelFlow,它直接在像素空间中进行操作,与传统的基于潜在空间(latent space)的模型不同。PixelFlow通过高效的级...图像模型# PixelFlow# 图像生成模型10个月前01970