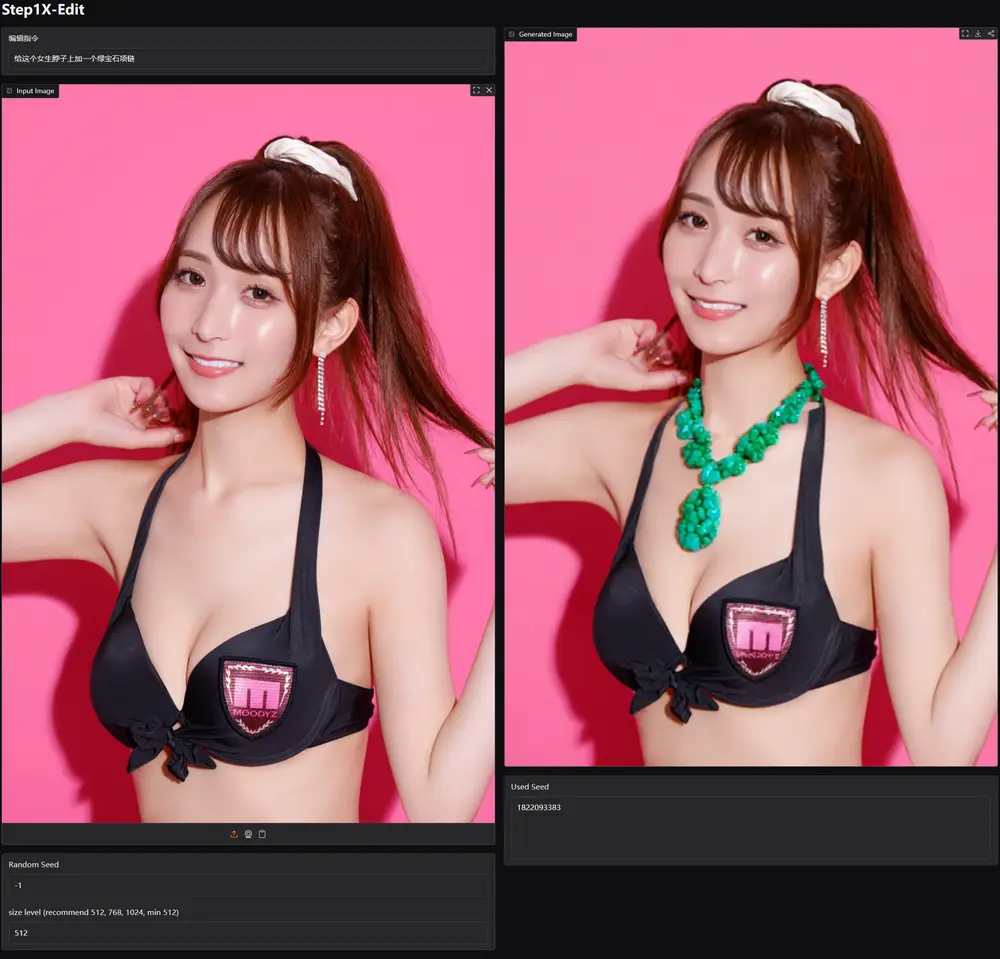
阶跃星辰推出新型通用图像编辑模型Step1X-Edit ,图像编辑与自然语言指令结合已成为视觉-语言研究中日益重要的任务。用户可以通过直观的自然语言指令来编辑图像,但这在技术上带来了独特的挑战,例如理解细微的语义、精确地定位编辑区域以及保持图像的保真度。
- 项目主页:https://step1x-edit.github.io
- GitHub:https://github.com/stepfun-ai/Step1X-Edit
- 模型:Hugging Face|魔塔
- Demo:https://huggingface.co/spaces/stepfun-ai/Step1X-Edit
近年来,图像编辑技术发展迅速。像 GPT-4o 和 Gemini2 Flash 等先进的闭源多模态模型展现出了令人印象深刻的图像编辑能力。然而,开源算法与这些闭源模型之间仍然存在较大差距。因此,Step1X-Edit 旨在发布一个最先进的图像编辑模型,其性能可与 GPT-4o 和 Gemini2 Flash 等闭源模型媲美。
要求:
以下表格显示了运行 Step1X-Edit 模型(批次大小 = 1,不使用配置文件蒸馏)进行图像编辑的要求:
| Model | height/width | Peak GPU Memory | 28 steps w flash-attn |
|---|---|---|---|
| Step1X-Edit | 512x512 | 42.5 GB | 5 s |
| Step1X-Edit | 768x768 | 46.5 GB | 11 s |
| Step1X-Edit | 1024x1024 | 49.8 GB | 22 s |
- 该模型在一台H800 GPU上进行了测试。
- 测试的操作系统:Linux
- 官方建议使用具有80GB内存的GPU,以获得更好的生成质量。
主要功能
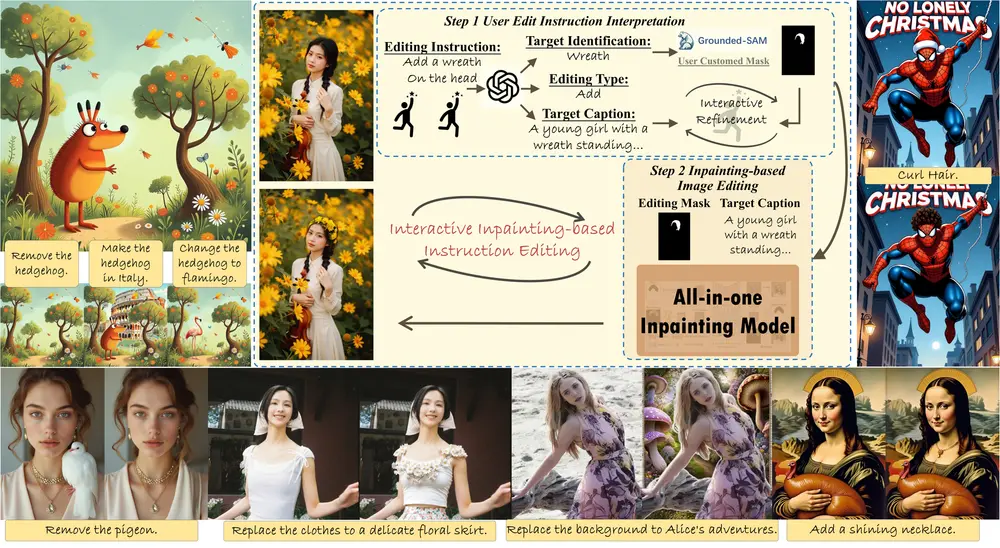
Step1X-Edit 是一种 通用图像编辑模型,具备全面的编辑能力。它基于对常用编辑指令的深入分析,将图像编辑问题系统地分为 11 个不同的任务类别。这些类别旨在全面涵盖实际中绝大多数的图像编辑需求。
主体添加与移除 (Subject Addition & Removal): 例如,“移除图像左侧的建筑物”或“在图像左侧添加建筑物”。 主体替换与背景改变 (Subject Replacement & Background Change): 例如,“将画面中心右侧的胶带替换为一个彩色的魔法折叠扇,并倾斜放置”或“把背景改为春天的公园,然后这个人这个不要变化”。 颜色改变与材质修改 (Color Alteration & Material Modification): 例如,“把龙虾的材质改为青花瓷”或“将伞的颜色改为棕色”。 文本修改 (Text Modification): 例如,“请将图像中的单词‘Saul’改为‘mall’”或“将文本 'TOES' 替换为 'NIKE'”。 动作改变 (Motion Change): 例如,“让图像中的人竖起大拇指”或“请给我生成这张照片他笑起来的样子”。 肖像美化 (Portrait Beautification): 例如,“请去掉我脸上的痘痘并化妆让我看起来更好”或“把他的鼻子变高点”。 风格迁移 (Style Transfer): 例如,“将它转换为吉卜力风格”或“改为数字插画风格”。 色调转换 (Tone Transformation): 例如,“恢复并高清上色这张老照片”或“感觉我的照片有点暗黄,帮我的照片调下色”。
其他任务还包括背景改变 (Background Change)、颜色改变 (Color Alteration) 和材质修改 (Material Modification)。
主要特点 (主要特点)
开源性 (Open-Source): Step1X-Edit 将开源发布,以缩小开源与闭源图像编辑系统之间的性能差距,并促进该领域的进一步研究。 高性能 (High Performance): 实验结果表明,Step1X-Edit 在 GEdit-Bench 基准测试中大幅优于现有的开源基线模型。在与 GPT-4o 和 Gemini2 Flash 等闭源模型比较时,其性能接近,甚至在风格改变和颜色修改等某些方面超过 GPT-4o。在处理中文指令时,Step1X-Edit 的性能也保持稳定,甚至超过了 Gemini2 和 Doubao。 基于真实世界用户指令的评估 (Real-world Evaluation): 论文引入了一个名为 GEdit-Bench 的新基准测试,它基于从互联网(如 Reddit)收集的真实世界用户编辑指令。这确保了对模型在实际应用场景中能力的更真实和全面的评估。 高质量大规模数据集 (High-quality Large-scale Dataset): 为了训练模型,Step1X-Edit 构建了一个数据生成管道,生成了超过 100 万高质量的图像编辑三元组(源图像、编辑指令和目标图像)。该数据集在规模上超过了现有的大多数编辑数据集。 统一架构 (Unified Architecture): 模型结合了多模态大型语言模型 (MLLM) 的强大语义推理能力与 DiT (Diffusion in Transformer) 风格的扩散解码器。这种架构无需在编辑过程中依赖额外的遮罩 (mask)。 双语支持 (Bilingual Support): 数据集的标注是双语的(中文和英文),支持多语言模型训练和评估。基准测试也在英文和中文指令下进行了评估。
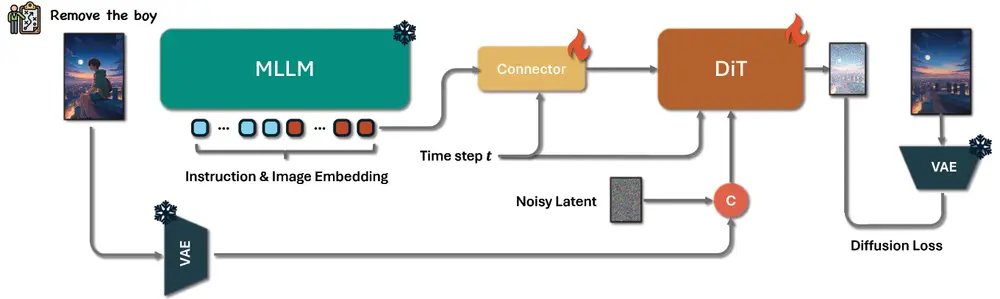
工作原理 (工作原理)
Step1X-Edit 的算法主要包含三个关键组件:多模态大型语言模型 (MLLM)、连接器模块 (connector module) 和 DiT。
MLLM 处理输入: 输入的编辑指令和参考图像首先由 MLLM(例如 Qwen-VL)处理。通过一次前向传播,MLLM 能够捕捉指令和视觉内容之间的语义关系。 提取和精炼嵌入 (Extract and Refine Embeddings): 为了突出与编辑任务相关的语义信息,模型会选择性地舍弃与系统前缀相关的 token 嵌入,仅保留与编辑指令直接对齐的 token 嵌入。这些提取出的嵌入随后被输入到一个轻量级的连接器模块中进行重构,形成更紧凑的文本特征表示。 与 DiT 集成并生成图像 (Integrate with DiT and Generate Image): 精炼后的特征取代了下游 DiT 网络中由文本编码器(如 T5)生成的原始文本嵌入。此外,MLLM 所有输出嵌入的平均值通过线性层投影,生成一个全局视觉指导向量。通过这种方式,图像编辑网络可以利用 MLLM 增强的语义理解能力,实现更准确和上下文感知的编辑操作。 训练机制 (Training Mechanism): 模型采用联合学习设置,连接器和下游 DiT 同时进行优化。训练过程中利用参考图像和目标图像,通过 VAE 编码和 token 拼接机制来增强模型推理对比视觉上下文的能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











