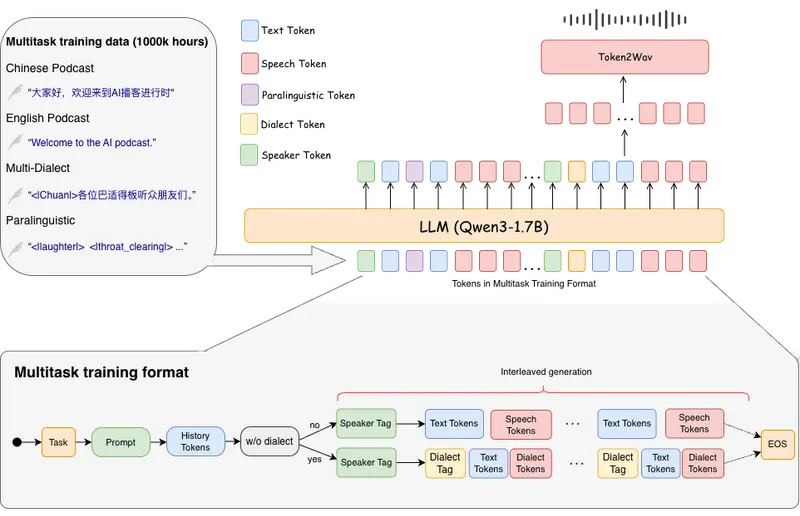
SoulX-Podcast:支持方言与副语言的真实感播客语音合成系统西北工业大学、Soul AI 实验室与上海交通大学联合推出 SoulX-Podcast —— 一个专为长篇、多轮次、多说话者对话场景设计的语音合成系统。它不仅能生成高质量的播客风格对话语音,也在传统单...语音模型# SoulX-Podcast# 播客5个月前01010
小红书开源 FireRedChat:一个完整、可控的全双工语音交互系统在智能助手和客户服务场景中,用户希望与AI的对话像人与人交流一样自然——可以随时插话、打断、继续,而系统能即时响应。要实现这种体验,需要真正的全双工语音交互能力。 然而,现有方案存在明显短板: 端到端...语音模型# FireRedChat# 小红书6个月前04410
NeuTTS Air:可在本地运行的高效语音合成模型长期以来,高质量的文本转语音(TTS)能力主要依赖云端 API——虽然效果好,但存在延迟高、隐私风险、网络依赖等问题。 现在,一种新的选择正在出现:在本地设备上实现自然听感的语音合成。 NeuTTS ...语音模型# NeuTTS Air# 语音合成模型6个月前05650
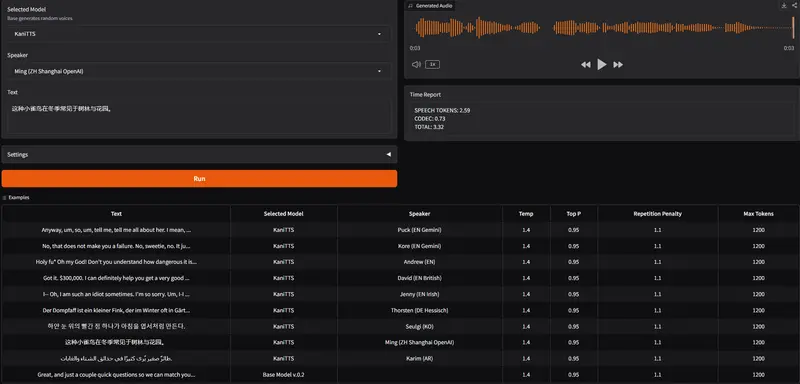
KaniTTS 发布:一种高效且富有表现力的文本到语音模型NineNineSix 团队近日推出 KaniTTS ——一个专为低延迟、高保真语音合成设计的开源文本到语音(TTS)系统。 GitHub:https://github.com/nineninesix...语音模型# KaniTTS6个月前02070
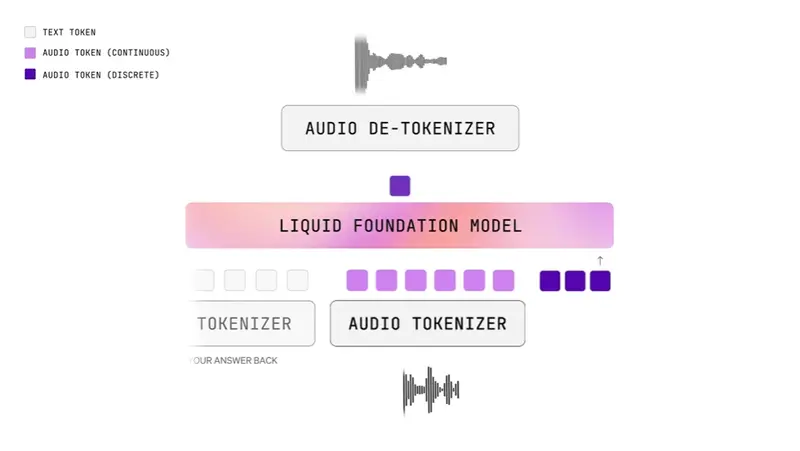
Liquid AI 发布 LFM2-Audio:一个轻量级、端到端的音频-文本基础模型Liquid AI 正式推出 LFM2-Audio-1.5B ——一款专为实时交互设计的端到端多模态基础模型,支持音频与文本的任意输入输出组合。 GitHub:https://github.com/L...语音模型# LFM2-Audio# Liquid AI6个月前01640
Hume AI 发布 Octave 2:更智能、多语言、低延迟的语音合成系统Hume AI 正式推出 Octave 2 ——其下一代文本到语音(TTS)模型的重大升级版本。作为“语音语言模型”(Speech Language Model, SLM)架构的延续,Octave 2...语音模型# EVI 4 mini# Hume AI# Octave 26个月前01120
阿里发布Qwen3-LiveTranslate-Flash :全球首个视、听、说全模态实时同传大模型阿里通义实验室今日推出 Qwen3-LiveTranslate-Flash——一款基于 Qwen3-Omni 基座模型打造的多语言实时音视频同声传译大模型。 Demo:https://huggingf...语音模型# Qwen3-LiveTranslate-Flash# 实时同传大模型6个月前08600
SongPrep:腾讯提出自动化歌曲预处理方案,破解AIGC歌曲生成的数据难题在AIGC的众多分支中,歌曲生成因兼具“音乐旋律”“歌词文本”“结构韵律”的多维度创作需求,一直是技术难点。尽管互联网上有海量歌曲资源,但要将这些原始音频转化为可训练AIGC模型的“结构化数据”,传统...语音模型# SongPrep# 腾讯# 音乐模型7个月前01300
Qwen3-TTS-Flash 发布:支持多音色、多语言与多方言的语音合成模型通义实验室近日推出 Qwen3-TTS-Flash,一款面向多场景应用的高性能文本转语音(TTS)模型。该模型现已通过 Qwen API 开放访问,支持自然、流畅且富有表现力的语音生成。 API:ht...语音模型# Qwen3-TTS-Flash# 语音合成模型7个月前03340
Mini-Omni-Reasoner:将推理能力引入大型语音模型,让语音模型“边说边思考”由南洋理工大学、新加坡国立大学、腾讯、北京工业大学与北京航空航天大学联合研发,Mini-Omni-Reasoner 正式推出——这是一次将推理能力引入大型语音模型(Large Speech Model...语音模型# Mini-Omni-Reasoner# 语音思考模型7个月前03530
小米发布 MiMo-Audio:基于亿级小时预训练的开源音频语言模型小米近日正式推出 MiMo-Audio ——一个统一的生成式音频-语言模型,支持跨模态语音理解与生成任务。该模型通过超过一亿小时的大规模预训练,实现了强大的少样本学习能力,能够在无需微调的情况下,仅凭...语音模型# MiMo-Audio# 小米# 音频语言模型7个月前02440
FireRedTTS-2:面向长对话场景的流式多说话人语音合成系统在播客制作、智能客服和实时对话系统中,自然流畅的多说话人语音合成是一项关键能力。然而,当前主流的对话式TTS(Text-to-Speech)技术普遍存在几个核心问题: 需要预先提供完整对话文本,无法支...语音模型# FireRedTTS-2# 小红书7个月前02250