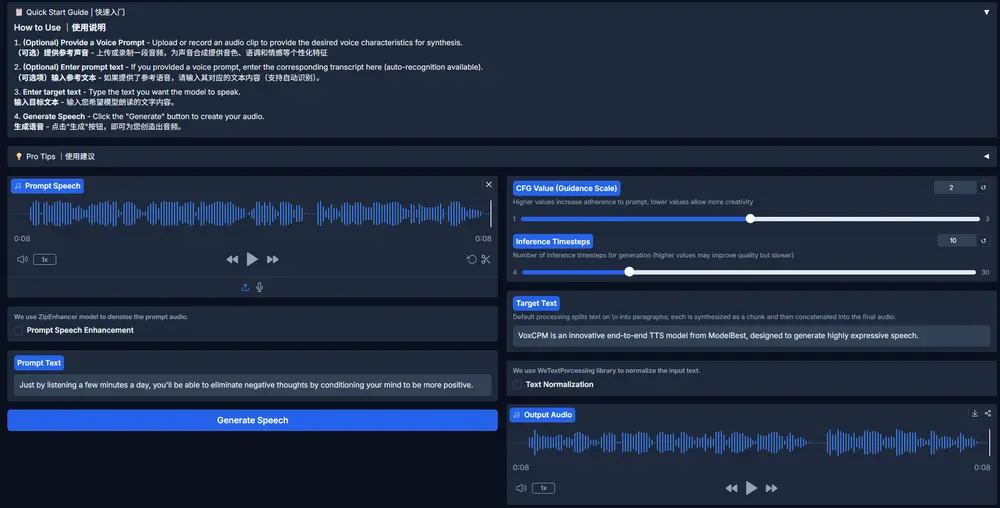
面壁智能发布VoxCPM:无需分词器的TTS,用于上下文感知的语音生成和真实感声音克隆在语音合成领域,大多数主流 TTS(Text-to-Speech)模型依赖于将语音信号离散化为“音素”或“语音标记”——这一过程虽然便于建模,但也带来了固有局限: 声音细节丢失、韵律不自然、跨说话人迁...语音模型# TTS# VoxCPM# 面壁智能7个月前05220
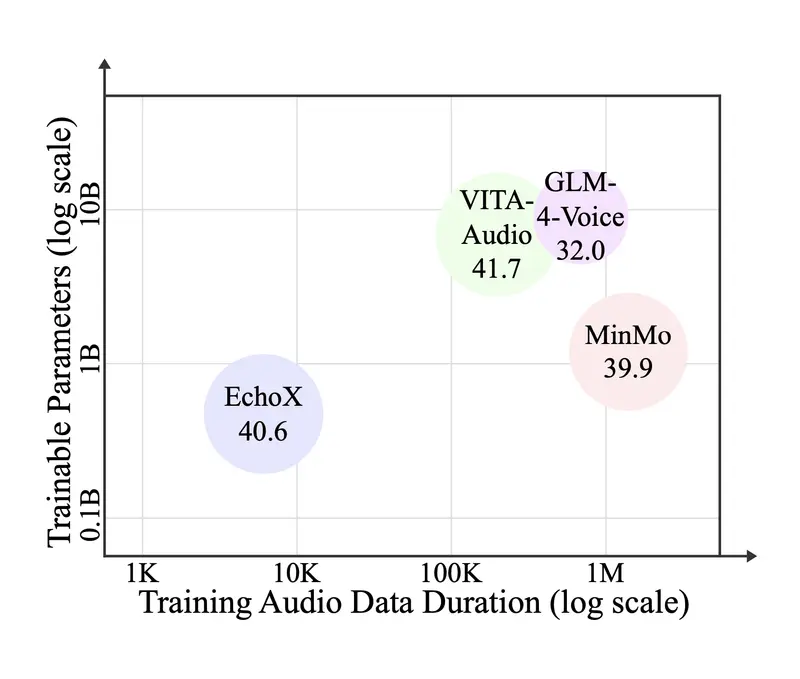
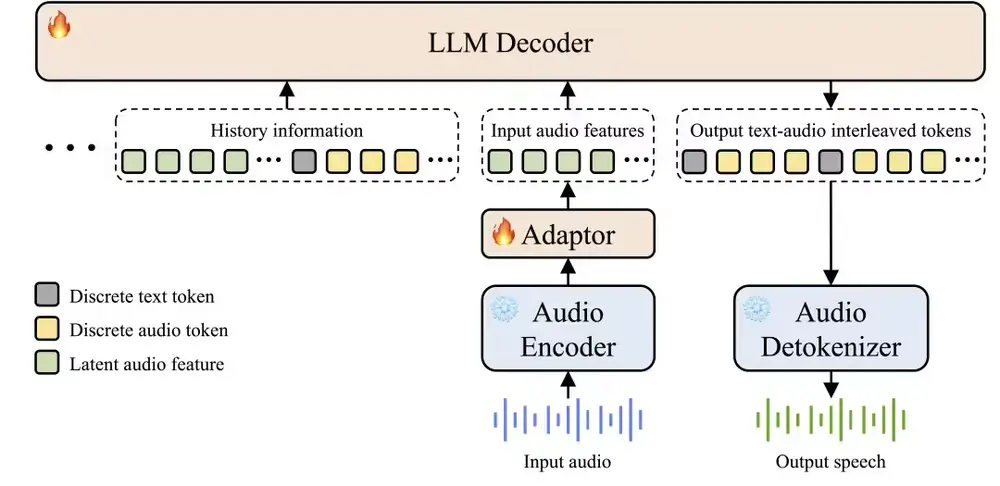
香港中文大学(深圳)提出语音到语音大语言模型EchoX:用“回声训练”弥合语音生成中的语义鸿沟近年来,语音到语音大语言模型(Speech-to-Speech LLMs, SLLMs)成为多模态 AI 的重要方向——用户说一句话,模型直接以语音回应,无需经过“语音→文本→语音”的中间转换。 但这...语音模型# EchoX# 语音到语音大语言模型7个月前01780
Stable Audio 2.5 发布:Stability AI 推出首款企业级音效制作专用音频模型Stability AI 正式推出 Stable Audio 2.5——这是业内首款专为企业级音效制作设计的音频生成模型。该模型聚焦企业在规模化定制高质量音频时的核心需求,通过技术升级与生态合作,助力...语音模型# Stability AI# Stable Audio 2.57个月前01950
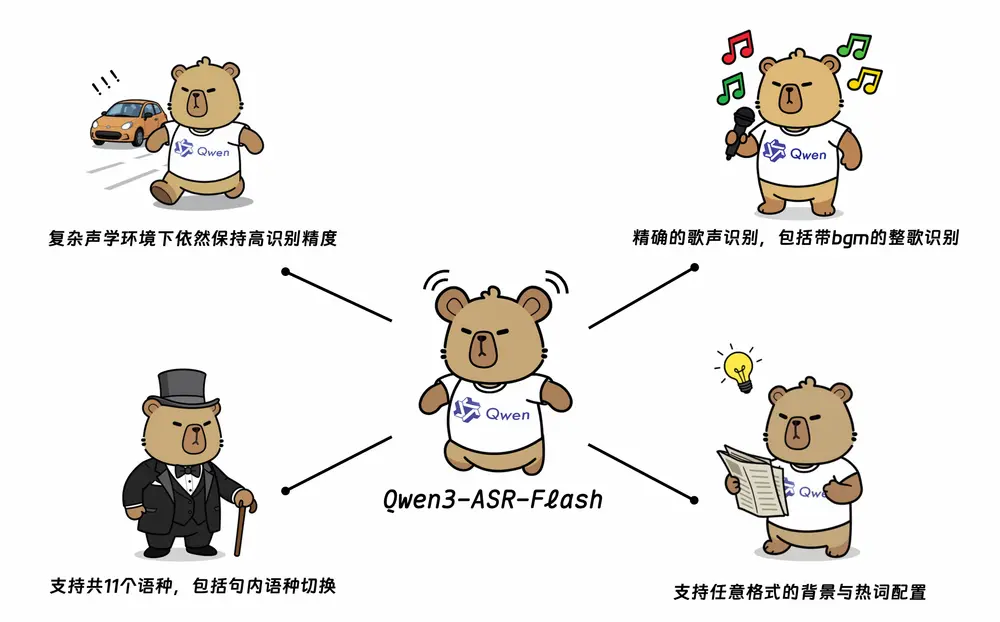
阿里通义实验室发布 Qwen3-ASR-Flash:支持多语种、歌声识别与上下文定制的新一代语音识别服务阿里通义实验室近日正式推出 Qwen3-ASR-Flash,一款基于 Qwen3 大模型基座 构建的高性能语音识别(ASR)服务。该服务融合千万小时级语音数据与海量多模态训练样本,致力于在准确率、鲁棒...语音模型# Qwen3-ASR-Flash7个月前01170
ElevenLabs 发布音效生成模型SFX v2:音效生成更真实,支持无缝循环ElevenLabs 今天推出了其音效生成模型 SFX v2,在音质、功能和使用体验上实现多项重要升级。现在,用户只需输入一段文字提示,即可生成高质量、可循环的环境音效,适用于有声书、播客、视频、冥想...语音模型# ElevenLabs# SFX v2# 音效生成模型7个月前02020
艾伦AI研究所推出全新开源 ASR 模型家族OLMoASR在自动语音识别(ASR)领域,Whisper 一直是开源社区的标杆——强大、鲁棒、支持零样本迁移。但它有一个根本局限:训练数据未公开,模型行为难以分析,也无法完全复现。 现在,艾伦人工智能研究所(AI...语音模型# OLMoASR# 艾伦AI研究所7个月前01430
阶跃星辰发布开源语音大模型Step-Audio 2 mini:多任务性能登顶SOTA,攻克语音AI“智商情商”痛点今日,阶跃星辰正式发布开源端到端语音大模型Step-Audio 2 mini,该模型在音频理解、语音识别、翻译及对话等多个国际基准测试集中均斩获SOTA(state-of-the-art,当前最优)成...语音模型# Step-Audio 2 mini# 阶跃星辰7个月前02600
中科院+腾讯提出AudioStory:LLM+TTA协同,破解长篇叙事音频“不连贯”痛点文本到音频(TTA)技术已能生成高质量短音频片段,但面对“雨中追逐场景”“视频配音旁白”这类需要时间连贯性、情感一致性的长篇叙事需求时,传统模型常出现“声音断层”“氛围割裂”等问题。 GitHub:h...语音模型# AudioStory# TTA7个月前02000
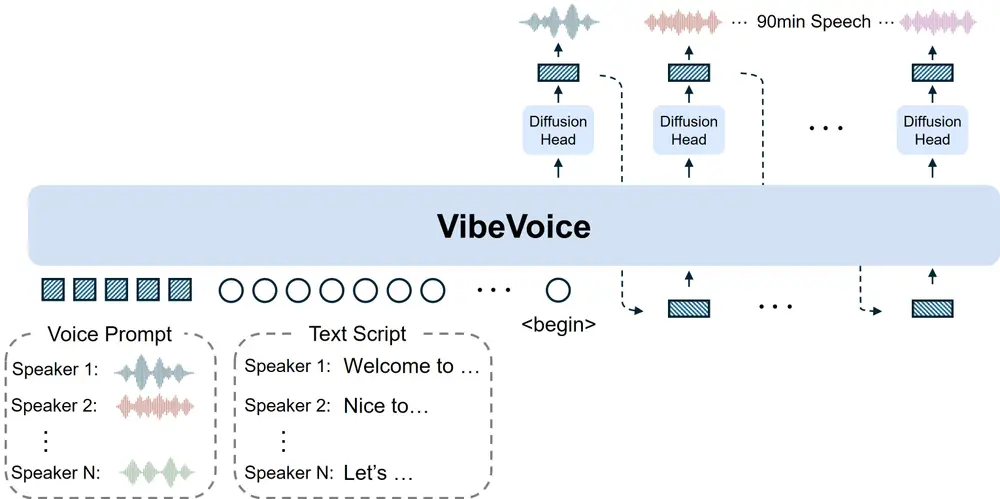
VibeVoice-1.5B:微软开源TTS框架,可生成4人60分钟长对话音频微软近期开源了一款全新文本到语音(TTS)框架——VibeVoice-1.5B,其核心突破在于打破传统TTS系统的局限:能同时生成包含4个不同说话者、最长60分钟的连贯对话音频,且在长序列处理效率、说...语音模型# TTS# VibeVoice-1.5B# 微软8个月前05360
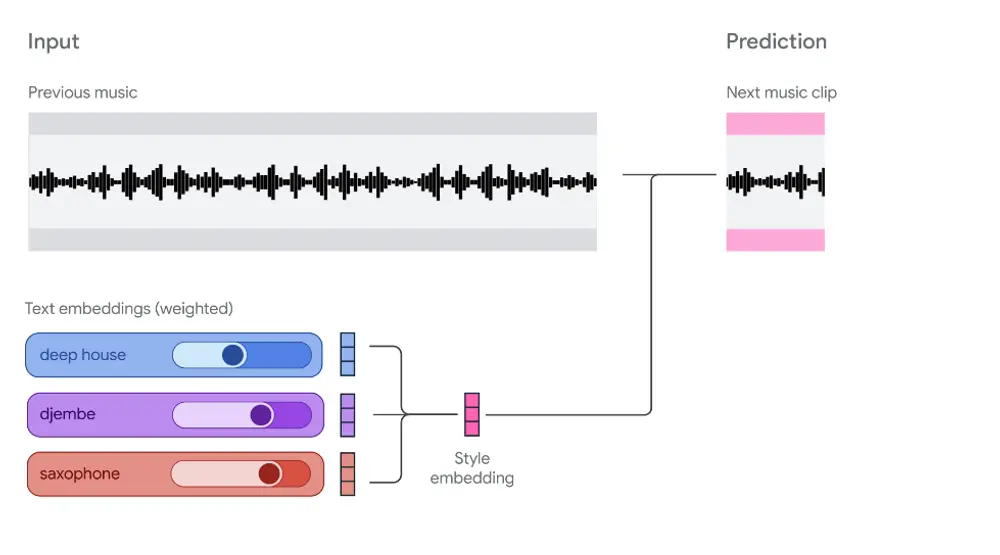
Magenta RealTime:一个可交互、可定制的开源实时音乐生成模型当 AI 生成音乐从“预设播放”走向“实时演奏”,我们正在见证创作方式的一次深刻转变。 传统的音乐生成模型通常以“批处理”模式运行:输入一段提示,等待几秒后输出完整音频。这种模式虽能产出完整作品,却缺...语音模型# Magenta RealTime# 实时音乐生成模型8个月前02030
KittenML推出一个仅 25MB 的开源文本转语音模型Kitten TTSKittenML推出一款名为 Kitten TTS 的新型文本转语音(TTS)模型,它以极小体积、无需 GPU 和高质量语音合成能力为特点,专为边缘设备和轻量级部署场景设计。 GitHub:https...语音模型# Kitten TTS# 文本转语音模型8个月前05910
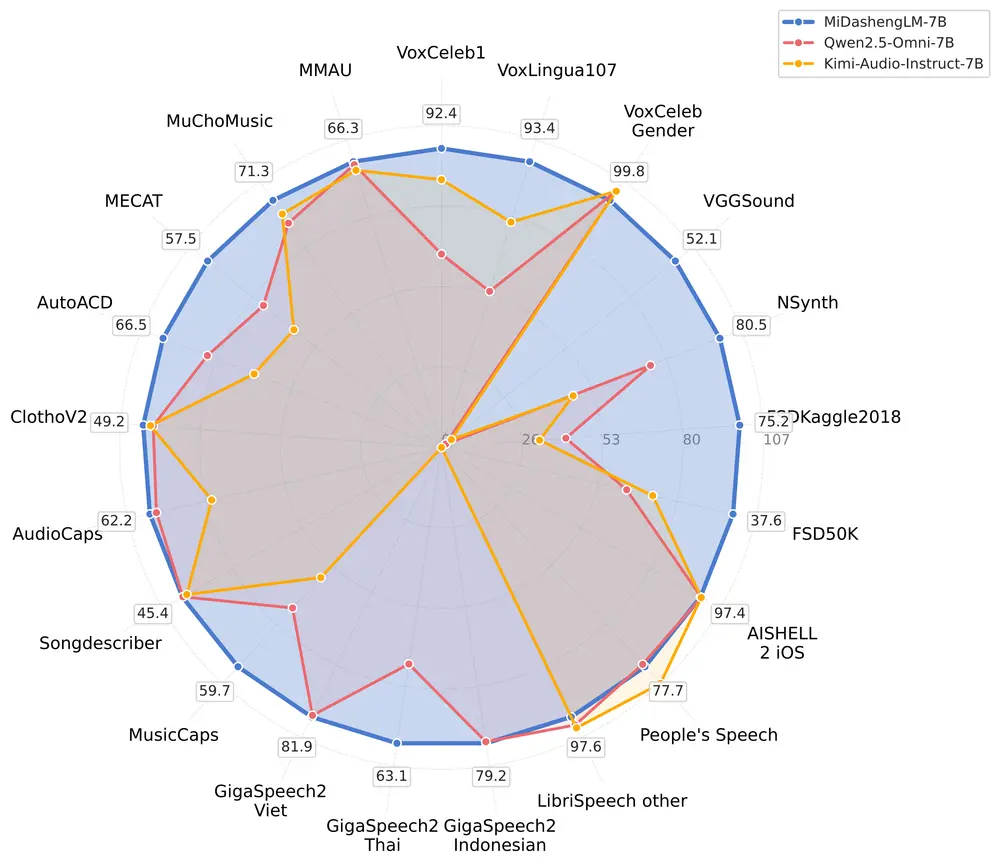
小米自研声音理解大模型 MiDashengLM-7B 正式开源小米正式发布并全量开源其自研声音理解大模型 —— MiDashengLM-7B。该模型在性能与效率上实现双重突破,标志着小米在多模态AI领域,尤其是声音理解方向的又一次重要进展。 GitHub 主页...语音模型# MiDashengLM-7B# 声音理解大模型# 小米8个月前03030