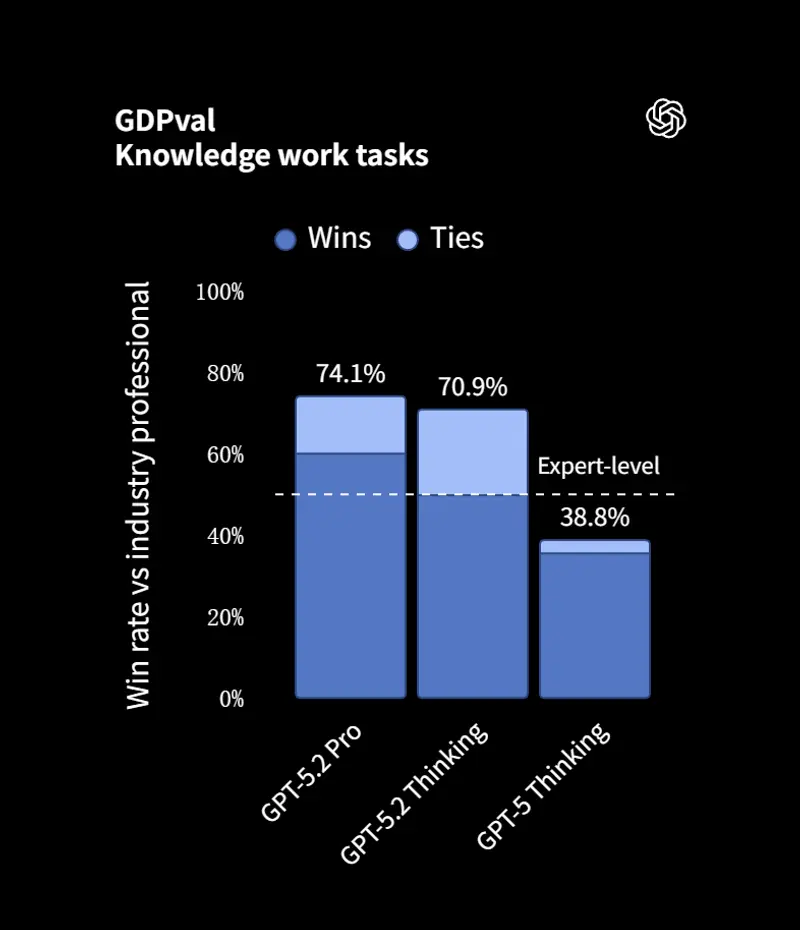
OpenAI正式发布GPT-5.2 :GDPval 超人类专家,编码/长上下文/视觉能力全面跃升OpenAI 再度刷新大模型天花板——GPT-5.2 正式发布。这款专为专业知识工作和长期运行智能体打造的前沿模型,在编码、长上下文推理、视觉理解、工具调用等核心能力上实现跨越式提升,甚至在覆盖 44...大语言模型早报# GPT-5.2# OpenAI2个月前0500
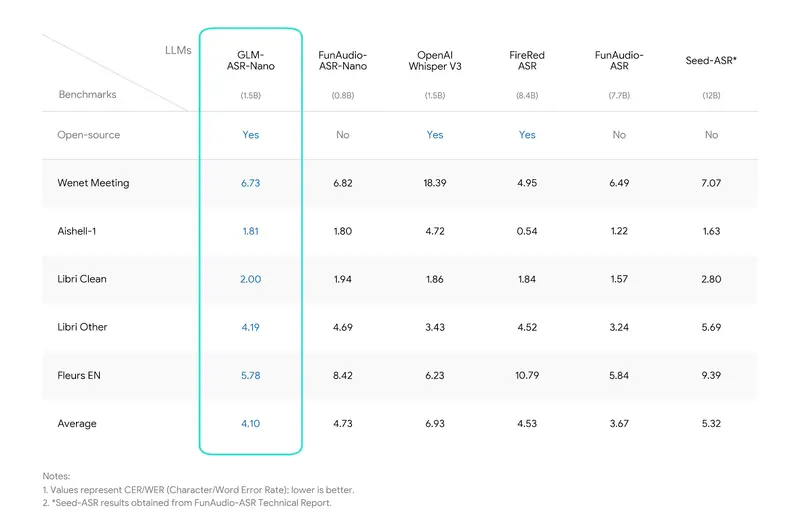
智谱AI语音识别模型GLM-ASR双版本登场:云端版精准识别多场景,Nano版开源免费,笔记本/手机均可部署智谱AI全新发布 GLM-ASR 系列语音识别模型,包含云端部署的 GLM-ASR-2512 与端侧轻量化的 GLM-ASR-Nano-2512 两个版本。其中 Nano 版以 1.5B 紧凑参数规模...语音模型# GLM-ASR-2512# GLM-ASR-Nano-2512# 智谱AI2个月前0310
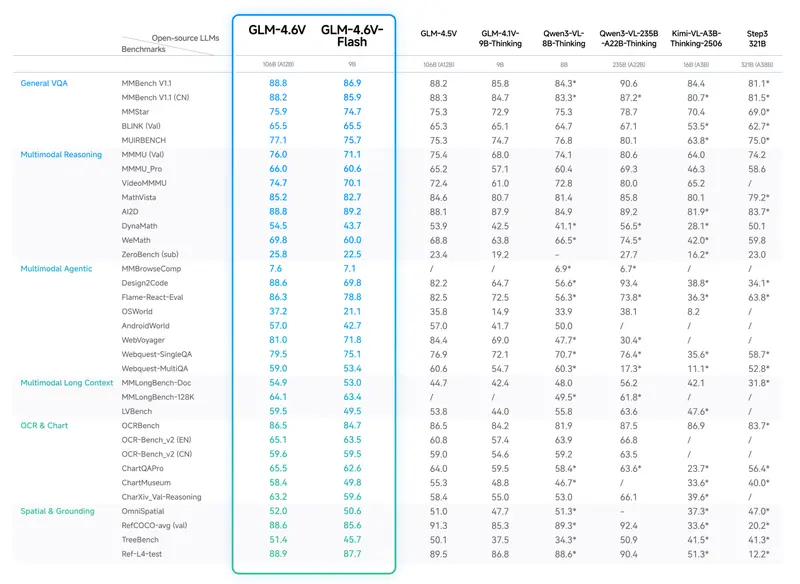
智谱AI开源GLM-4.6V:128K上下文视觉语言模型,原生工具调用打通感知与执行链路智谱AI正式推出并开源 GLM-4.6V 系列多模态大语言模型,包含面向云端与高性能集群的 GLM-4.6V (106B) 基础模型,以及针对本地部署和低延迟场景优化的 GLM-4.6V-Flash ...多模态模型# GLM-4.6V# 智谱AI2个月前0250
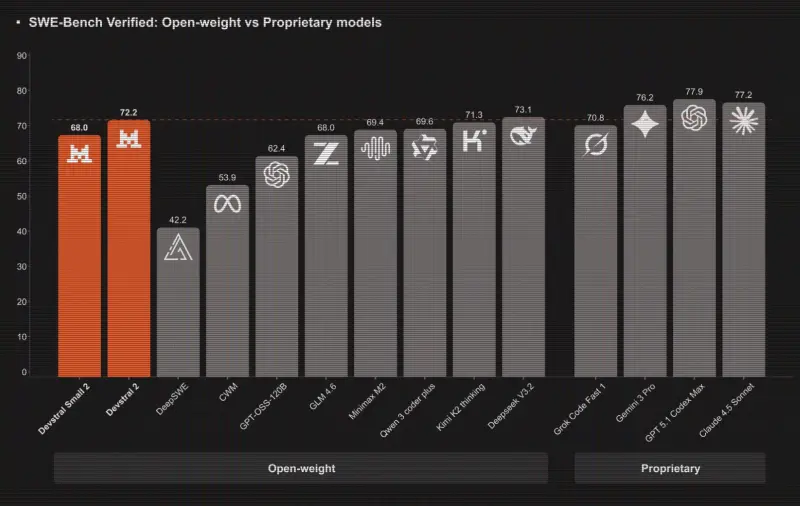
Mistral AI 发布 Devstral 2 编程模型+Vibe CLI:1230亿参数适配智能体开发,终端原生编程更高效Mistral AI 推出两大核心产品——新一代软件工程智能体编程模型家族 Devstral 2,以及开源命令行编程助手 Mistral Vibe CLI。前者以高参数、长上下文和高性价比成为开源编程...大语言模型# Devstral 2# Mistral AI# 编程模型2个月前0330
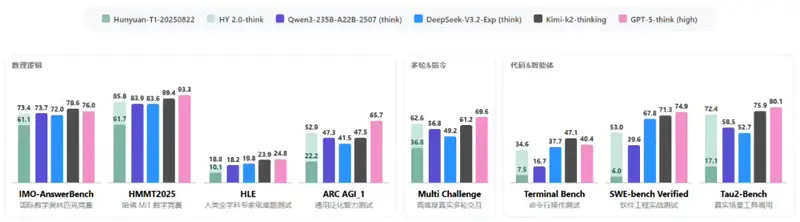
腾讯发布混元 2.0 大模型:406B MoE 架构,256K 上下文,推理效率国内领先腾讯正式发布自研大模型 混元 2.0(Tencent HY 2.0),包含 HY 2.0 Think(推理优化版)与 HY 2.0 Instruct(指令对齐版)两个版本。该模型采用 混合专家(MoE...大语言模型# 混元 2.0 大模型# 腾讯2个月前0320
微软发布轻量级实时TTS模型VibeVoice-Realtime:300ms响应的流式长文本TTS模型实时文本转语音(TTS)技术在智能助手、实时播报、大模型交互等场景中有着极高的需求,但传统模型往往面临“延迟高”“长文本生成不稳定”“流式输入支持差”等痛点。 微软推出了一款轻量级实时TTS模型——V...语音模型# VibeVoice-Realtime# 微软2个月前0450
巨人网络AI实验室推出YingVideo-MV:音乐驱动的多阶段视频生成框架,让 AI 会“演”一首歌巨人网络AI实验室推出 YingVideo-MV,这是一个用于音乐驱动的多阶段视频生成框架,能够从音频信号中自动生成高质量的音乐表演视频。YingVideo-MV 集成了音频语义分析、可解释的镜头规划...视频模型# YingVideo-MV2个月前0140
扩散模型加速框架Glance:仅用 1 张图 + 1 GPU 小时,将扩散模型加速至 8 步武汉大学、新加坡国立大学、中南大学、电子科技大学和微软的研究人员推出一个用于加速扩散模型(Diffusion Models)的轻量级框架 Glance,通过“慢-快”(Slow-Fast)的阶段感知...图像模型# Glance# 加速框架2个月前0500
亚马逊推出全新Nova模型系列及开创性服务:Nova Forge与Nova Act核心要点 Nova 2 模型系列在推理、多模态处理、对话式AI、代码生成及智能体任务方面提供业界领先的性价比。 Nova Forge 服务允许企业通过其独特的“开放训练”方法,在训练早期融入专有数据...大语言模型# NOVA# Nova Act# Nova Forge2个月前0240
STARFlow-V:苹果推出标准化流视频生成模型,挑战扩散模型主流地位苹果最新发布的 STARFlow-V 为视频生成领域带来了全新技术路径——作为一款基于标准化流(Normalizing Flows)的端到端模型,它打破了当前扩散模型主导的格局,凭借全局-局部架构、因...视频模型# STARFlow-V# 流视频生成模型# 苹果2个月前0600
阶跃星辰开源Step-Audio-R1:首个支持测试时计算扩展的音频大语言模型,“越想越准”比肩Gemini 3阶跃星辰开源的 Step-Audio-R1 打破了传统音频模型的性能瓶颈,成为首个支持“测试时计算扩展”的音频大语言模型。它通过创新的模态落地推理蒸馏技术,让模型直接基于声学特征进行链式思考,而非依赖...语音模型# Step-Audio-R1# 阶跃星辰2个月前0400
Mistral AI正式发布Mistral 3系列模型:开源多模态模型家族,覆盖从边缘到企业级场景Mistral AI 正式推出新一代模型系列 Mistral 3,此次发布不仅包含适配边缘场景的 Ministral 3 系列小型密集模型,更带来了性能顶尖的稀疏专家混合模型 Mistral Larg...多模态模型# Mistral 3# Mistral AI# Mistral Large 32个月前0570