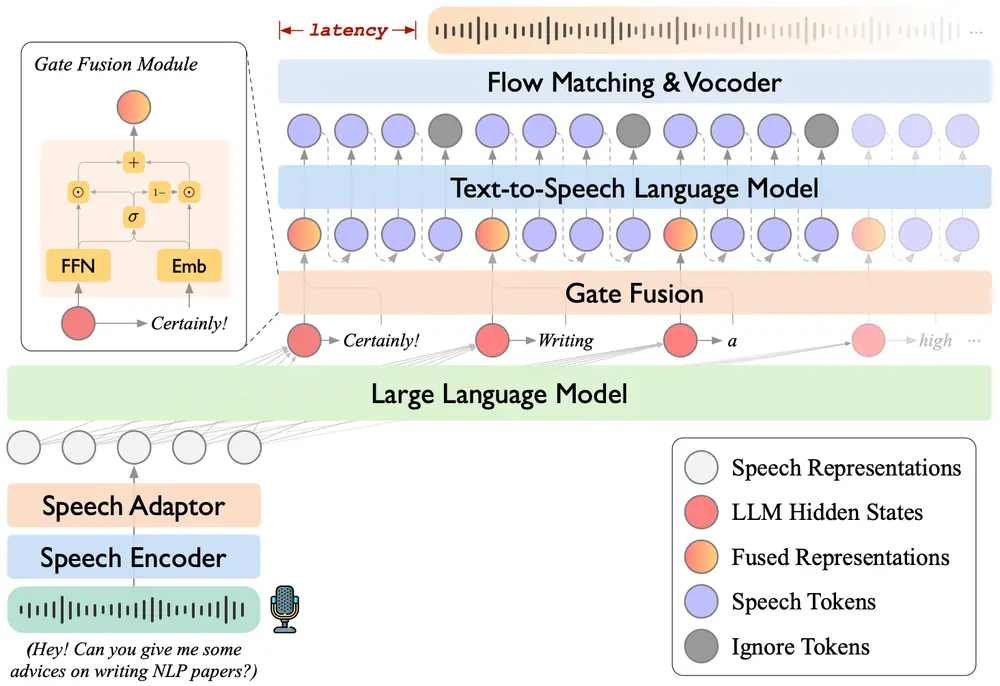
新型语音语言模型 LLaMA-Omni 2:实现高质量的实时语音交互中国科学院计算技术研究所、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出新型语音语言模型 LLaMA-Omni 2 ,旨在实现高质量的实时语音交互。LLaMA-Omni 2 基于 Qw...语音模型# LLaMA-Omni 2# 语音语言模型11个月前02780
新型语音语言基础模型Voila :实现自然、实时、自主的语音交互Maitrix.org、加州大学圣地亚哥分校和MBZUAI的研究人员推出新型语音语言基础模型Voila ,旨在实现自然、实时、自主的语音交互。Voila 通过端到端的架构设计,突破了传统语音交互系统...语音模型# Voila# 语音语言基础模型11个月前04970
字节跳动推出新型图像编辑方法 SuperEdit :通过改进监督信号来提升基于指令的图像编辑性能字节跳动和佛罗里达中央大学计算机视觉研究中心的研究人员推出新型图像编辑方法 SuperEdit ,通过改进监督信号来提升基于指令的图像编辑性能。 项目主页:https://liming-ai.gith...图像模型# SuperEdit# 图像编辑# 字节跳动11个月前02960
基于 FLUX.1-schnell的开源、无审查的生成模型ChromaChroma 是一个基于 FLUX.1-schnell 的 8.9 亿参数生成模型,完全采用 Apache 2.0 许可证,为开发者和研究者提供一个自由、开放、无审查的工具。无论是用于艺术创作、科学研...Flux衍生# Chroma# FLUX.1 [schnell]11个月前01,0030
基于两阶段框架的唇部同步方法KeySync:能够生成高分辨率、时间连贯且与音频对齐的视频,同时有效减少表情泄漏并处理面部遮挡唇部同步(Lip Synchronization)是指将视频中的唇部动作与新的输入音频对齐,使其在视觉上看起来自然且与音频同步。尽管这一领域与音频驱动的面部动画(Audio-driven Facial...视频模型# KeySync# 唇形同步# 唇部同步11个月前04610
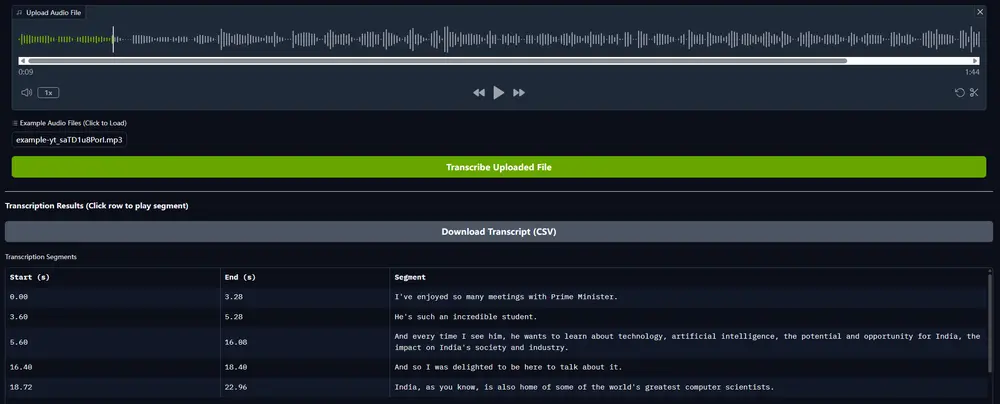
英伟达推出自动语音识别模型Parakeet-TDT-0.6B-v2:专为高质量英语语音转录设计英伟达推出的 Parakeet-TDT-0.6B-v2 是一款拥有 6 亿参数的自动语音识别(ASR)模型,专为高质量英语语音转录设计。该模型支持标点符号、大写和精准的时间戳预测,能够处理长达 24 ...语音模型# Parakeet-TDT-0.6B-v2# 自动语音识别模型自动语音识别模型# 英伟达11个月前05100
图像修复模型PixelHacker:基于潜在类别引导并结合扩散模型,显著提升图像修复质量图像修复(Image Inpainting)是计算机视觉领域的重要研究方向,旨在通过生成合理的图像内容填补缺失或损坏的部分。然而,现有方法在处理复杂结构(如纹理、形状和空间关系)以及语义一致性(如颜色...图像模型# PixelHacker# 图像修复模型11个月前04590
Watermark-Detection-SigLIP2:高效检测图像水印的视觉语言模型在数字内容管理中,水印检测是一项关键任务。无论是内容审核、数据集清理,还是版权保护,快速准确地识别图像中的水印都能显著提升工作效率。Watermark-Detection-SigLIP2 是一款基于谷...多模态模型# Watermark-Detection-SigLIP2# 水印检测11个月前05940
浙江大学与哈佛大学联合推出高效图像编辑框架In-Context Edit:用自然语言指令轻松实现图像修改浙江大学和哈佛大学的研究人员联合推出了ICEdit(In-Context Edit),这是一个高效且强大的基于指令的图像编辑框架。 与传统方法相比,ICEdit 仅需 1% 的可训练参数(2 亿)和 ...图像模型# FLUX# ICEdit# In-Context Edit11个月前06580
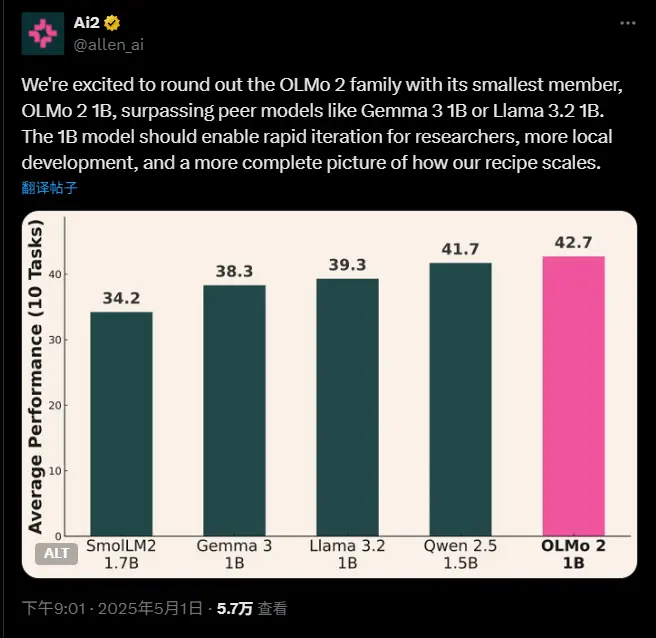
艾伦AI研究所发布10 亿参数的小模型Olmo 2 1B艾伦AI研究所(AI2)于周四发布了 Olmo 2 1B,这是一个拥有 10 亿参数的 AI 模型。AI2 宣称,该模型在多项基准测试中击败了谷歌、Meta 和阿里巴巴的同规模模型。尽管参数数量相对较...大语言模型# Olmo 2 1B# 艾伦AI研究所11个月前02440
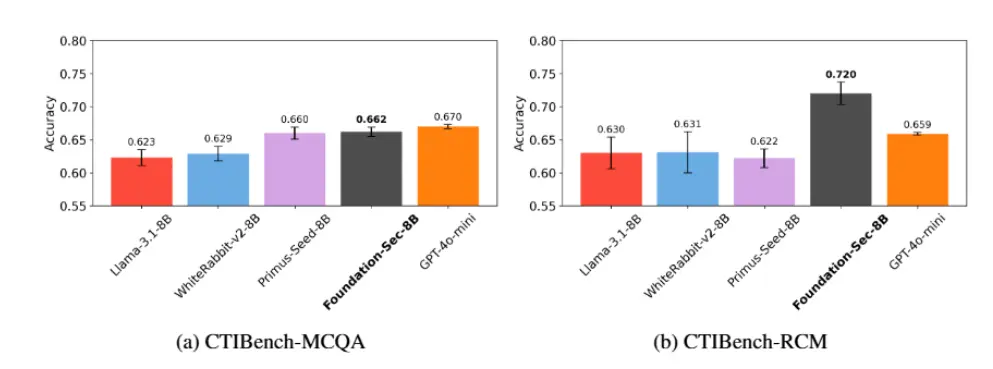
思科发布专为网络安全打造的开源模型 Foundation-sec-8b思科宣布其在AI领域的重大进展——推出首个由全新成立的Foundation AI团队开发的大语言模型(LLM):Llama-3.1-FoundationAI-SecurityLLM-base-8B(简...大语言模型# Foundation-sec-8b# 思科11个月前05760
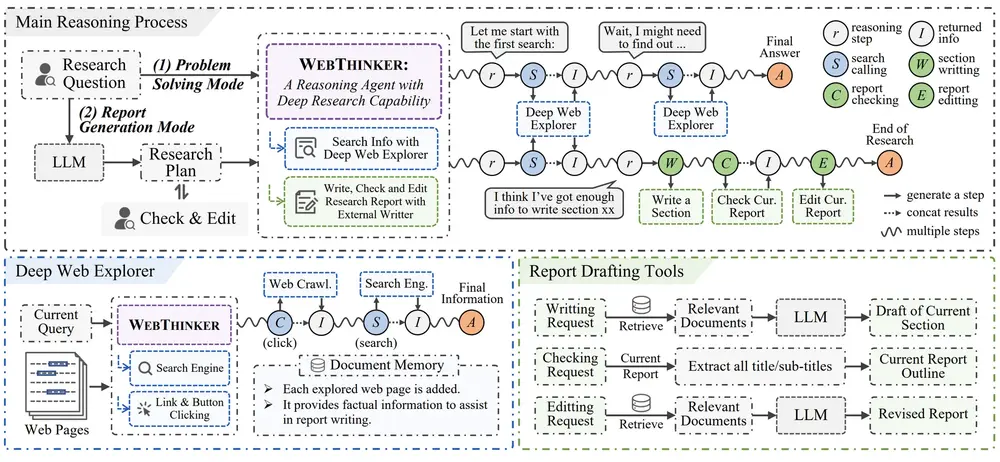
深度研究代理WebThinker:为大型推理模型提供深度研究能力中国人民大学、智源研究院和华为的研究人员推出一个深度研究代理WebThinker,旨在为大型推理模型(Large Reasoning Models, LRMs)提供深度研究能力。WebThinker ...大语言模型# WebThinker# 推理模型# 深度研究代理12个月前02460