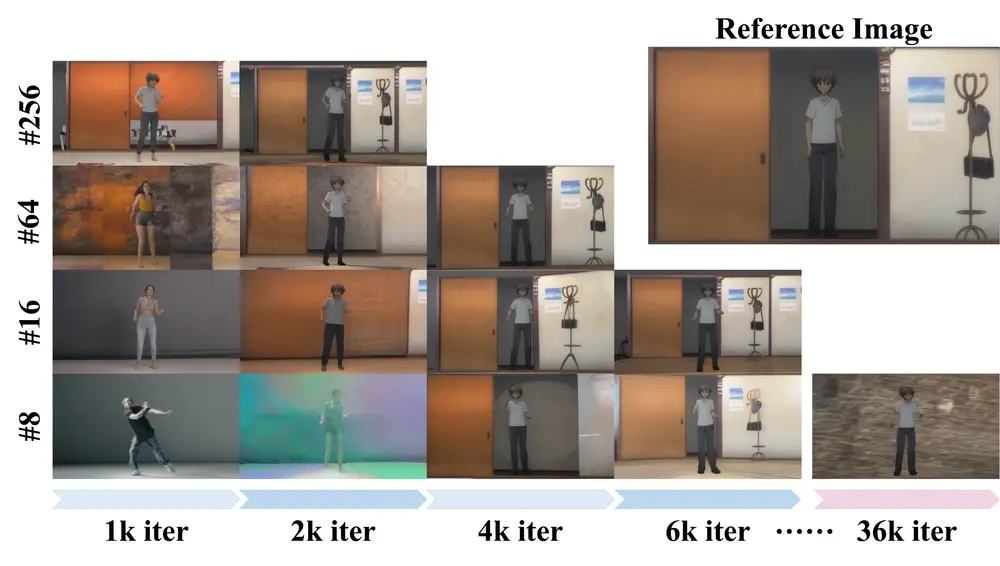
可控角色动画生成框架RealisDance-DiT:在处理稀有姿态、风格化角色、角色与物体的交互、复杂光照和动态场景等挑战性问题时表现出色阿里巴巴达摩院、浙江大学、湖畔实验室、南方科技大学和深圳大学的研究人员推出可控角色动画生成框架RealisDance-DiT,其在处理稀有姿态、风格化角色、角色与物体的交互、复杂光照和动态场景等挑战性...视频模型# RealisDance-DiT# Wan 2.1# 动画生成11个月前05250
开源版GPT-4o!字节跳动开源新一代多模态模型 BAGEL:多模态理解、图像生成、图像编辑,还能“思考”字节跳动发布了一款名为 BAGEL 的开源多模态基础模型,该模型拥有 70 亿活跃参数(总规模为 140 亿),在大规模交错多模态数据上进行训练。BAGEL 不仅在标准多模态理解排行榜中超越了当前主流...图像模型# BAGEL# GPT-4o# 多模态模型11个月前09300
字节跳动推出多模态文档图像解析模型Dolphin在复杂文档图像理解和结构化提取任务中,如何准确识别并组织交织的文本段落、公式、表格和图像,一直是业界的技术难点。 GitHub:https://github.com/bytedance/Dolphin...多模态模型# Dolphin# 多模态模型# 字节跳动9个月前04050
基于扩散模型的微调协议Marigold:用于各种图像分析任务,例如单目深度估计、表面法线预测和内在图像分解苏黎世联邦理工学院的研究人员推出一个基于扩散模型(diffusion-based models)的微调协议Marigold,用于各种图像分析任务,例如单目深度估计、表面法线预测和内在图像分解。Mari...图像模型# Marigold# 扩散模型11个月前04620
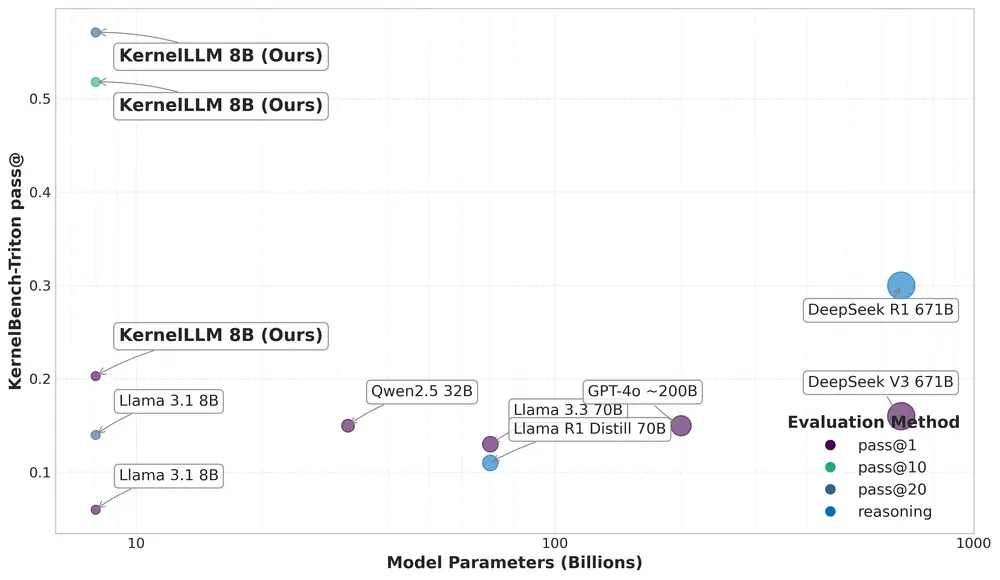
Meta推出基于 Llama 3.1 Instruct的大语言模型KernelLLM:专注于使用 Triton 编写高效GPU内核的任务Meta推出了一款名为 KernelLLM 的大语言模型,该模型基于 Llama 3.1 Instruct,专注于使用 Triton 编写高效GPU内核的任务。KernelLLM的核心目标是通过自动化...大语言模型# KernelLLM# Llama 3.1 Instruct# Meta11个月前01410
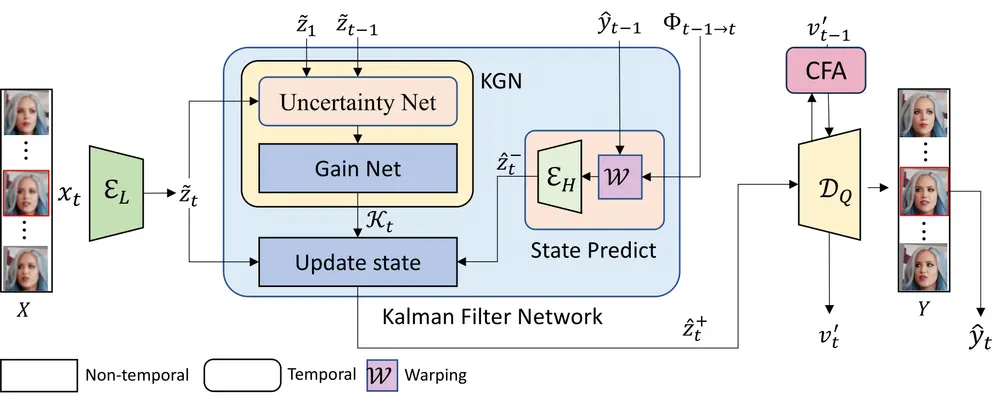
视频人脸超分辨率的新型框架KEEP:解决视频中人脸图像的超分辨率问题,同时保持时间一致性视频人脸超分辨率(VFSR)的目标是从低分辨率(LR)或严重退化的视频中重建出高分辨率(HR)的人脸图像。尽管人脸图像超分辨率(FSR)领域已经取得了显著进展,但视频人脸超分辨率仍然是一个相对较少被研...视频模型# KEEP# 视频人脸超分辨率11个月前01940
B站Index团队开源动漫视频生成模型 AniSora:一键生成多种风格的动漫视频片段哔哩哔哩(B站)Index团队开源了一款名为 AniSora 的动漫视频生成模型。作为目前最强大的开源动漫视频生成工具,AniSora 能够一键生成多种风格的动漫视频片段,包括番剧剧集、国创动画、漫画...视频模型# AniSora# B站# 动漫视频生成模型11个月前05280
Falcon-Edge:一系列强大、通用、可微调的1.58位语言模型Falcon 团队正式发布了 Falcon-Edge 系列模型——一组基于 BitNet 架构设计的三值格式语言模型。这些模型不仅具备高性能,还支持灵活的微调能力,为边缘设备上的高效部署提供了全新可能...大语言模型# BitNet# Falcon-Edge11个月前04150
新型统一多模态模型家族 BLIP3-o:同时支持图像理解和图像生成任务Salesforce、马里兰大学、弗吉尼亚理工大学、纽约大学、华盛顿大学和加州大学戴维斯分校的研究人员推出新型统一多模态模型家族 BLIP3-o ,同时支持图像理解和图像生成任务。多模态模型是指能够处...多模态模型# BLIP3-o# 多模态模型11个月前02530
A-M-team推出32B密集语言模型AM-Thinking-v1:专注增强推理能力A-M-team推出了AM-Thinking-v1,一款基于Qwen 2.5-32B-Base构建的32B密集语言模型,专注于提升推理能力。在推理基准测试中,AM-Thinking-v1表现出色,可媲...大语言模型# AM-Thinking-v1# 推理模型11个月前05050
阿里通义实验室 Wan 团队正式释出Wan2.1-VACE模型:支持视频生成与编辑的模型阿里通义实验室Wan 团队正式释出了Wan2.1-VACE模型,这是一款支持视频生成与编辑的模型,单一模型可同时支持文生视频、图像参考视频生成、视频重绘、视频局部编辑、视频背景延展以及视频时长延展等全...视频模型11个月前02620
Stability AI发布可在智能手机运行的音频生成模型Stable Audio Open SmallAI 初创公司 Stability AI 发布了 Stable Audio Open Small,这是一款专为移动设备设计的音频生成模型。据公司宣称,这是目前市场上最快的音频生成模型,并且效率高到可以...语音模型# Stability AI# Stable Audio Open Small11个月前02240