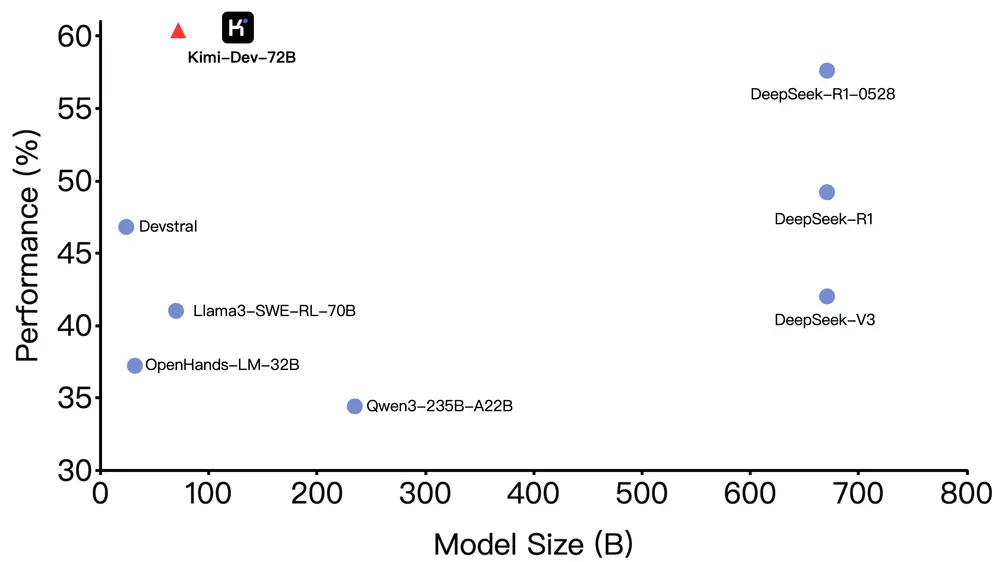
月之暗面推出Kimi-Dev-72B:为软件工程任务打造的新一代开源编码大模型月之暗面推出一款全新的开源编码大语言模型 Kimi-Dev-72B,专为软件工程任务设计。该模型基于 Qwen2.5-72B 微调而来,在 SWE-bench Verified 测试中取得了 60.4...大语言模型# Kimi-Dev-72B# 月之暗面10个月前03970
清华、腾讯等联合推出基于语言模型的高质量歌曲生成框架 LeVo随着大语言模型(LLMs)和音频语言模型的快速发展,AI 在音乐生成领域的能力显著提升,特别是在 歌词到歌曲生成 的方向上取得了突破性进展。 然而,现有方法仍面临两大核心挑战: 歌曲结构复杂,难以同时...语音模型# LeVo# SongGeneration# 音乐生成10个月前02630
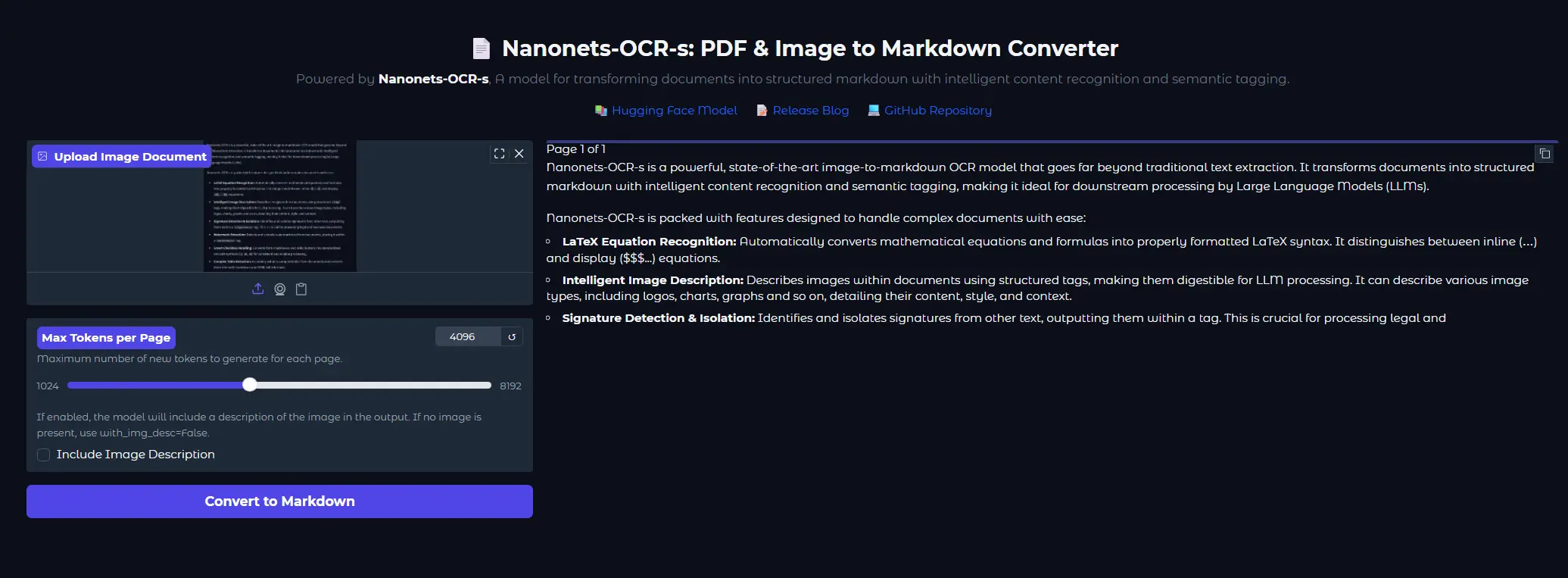
Nanonets 推出 Nanonets-OCR-s:首个面向 LLM 的结构化 OCR 模型近日,Nanonets 宣布推出一款全新的 OCR 模型 Nanonets-OCR-s ——这是一款专为大语言模型(LLMs)设计的图像转 Markdown 工具,具备强大的文档理解与结构化输出能力...多模态模型# Nanonets-OCR-s# OCR 模型10个月前03130
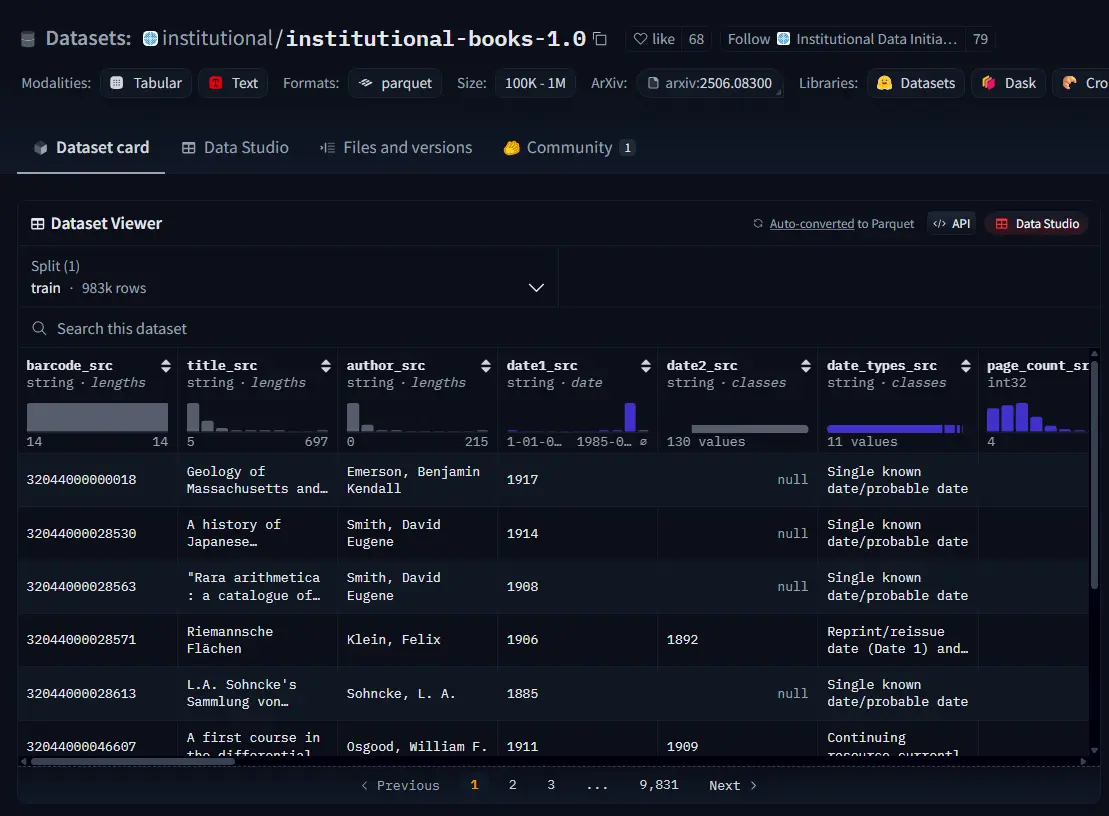
微软与 OpenAI 支持,哈佛法学院发起:首个大规模公共 AI 图书数据集正式开源上周,由微软与 OpenAI 联合资助、起源于哈佛大学法学院图书馆研究计划的 机构资料计划(Institutional Data Initiative,简称 IDI)宣布开源其首个大型 AI 数据集...大语言模型# OpenAI# 哈佛法学院# 微软10个月前02690
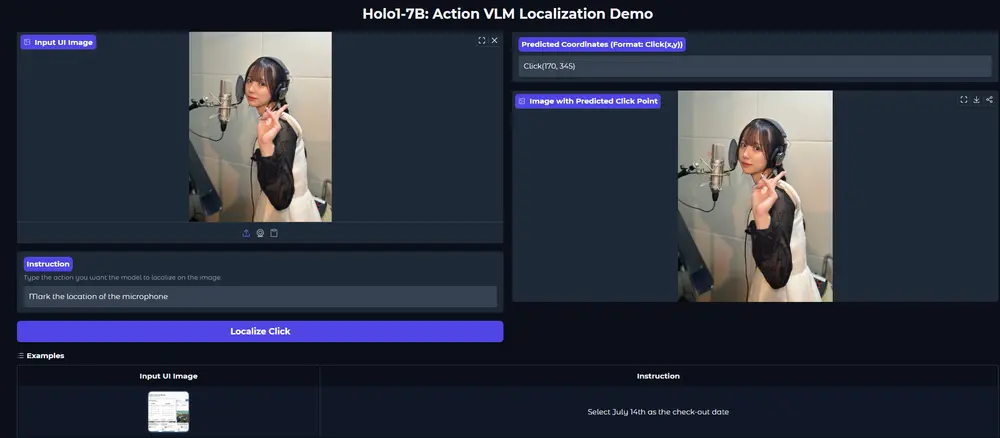
Holo1:HCompany开源高性能视觉-语言模型,赋能Surfer-H代理实现精准网页交互Holo1 是由 HCompany 开发的一款专为网络代理系统设计的 动作视觉-语言模型(VLM),作为 Surfer-H 网络代理的核心组件之一,它具备像人类用户一样与网页界面交互的能力。 模型:h...多模态模型# Holo1# 视觉-语言模型10个月前03510
字节跳动提出MAGREF:支持多参考图像和文本提示的高质量视频生成框架近年来,随着扩散模型等深度生成技术的发展,视频生成能力取得了显著进步。然而,在涉及多个参考主体的场景中,如何保证各主体之间的视觉一致性、身份一致性和生成稳定性,依然是一个重大挑战。 为了解决这一问题...视频模型# MAGREF# 字节跳动# 视频生成框架10个月前02530
浙大 & vivo 联合发布 MagicTryOn:首个基于扩散 Transformer 的视频虚拟试衣框架在虚拟试衣技术持续发展的背景下,如何在视频中实现自然、真实、连贯的服装模拟,依然是一个极具挑战性的课题。 浙江大学、vivo 和博维智慧科技的研究团队提出了一种全新的视频虚拟试衣(Video Virt...视频模型# MagicTryOn# Wan2.1# 视频虚拟试衣10个月前05590
告别塑料感!腾讯开源新一代 3D 生成大模型混元 3D 2.1在计算机视觉领域顶级会议 CVPR 2025 上,腾讯宣布将旗下 混元 3D 2.1 大模型全面开源,这是目前首个实现全链路开源的工业级 3D 生成大模型,标志着国产 AI 在 3D 内容生成领域的又...3D模型# 混元 3D 2.1# 腾讯10个月前01700
Sparc3D:用于高分辨率三维形状建模的稀疏表示和构建框架南洋理工大学、Math Magic和伦敦帝国理工学院的研究人员推出一个用于高分辨率三维形状建模的稀疏表示和构建框架 Sparc3D,它通过稀疏可变形的 Marching Cubes(Sparcubes...3D模型# Sparc3D10个月前05170
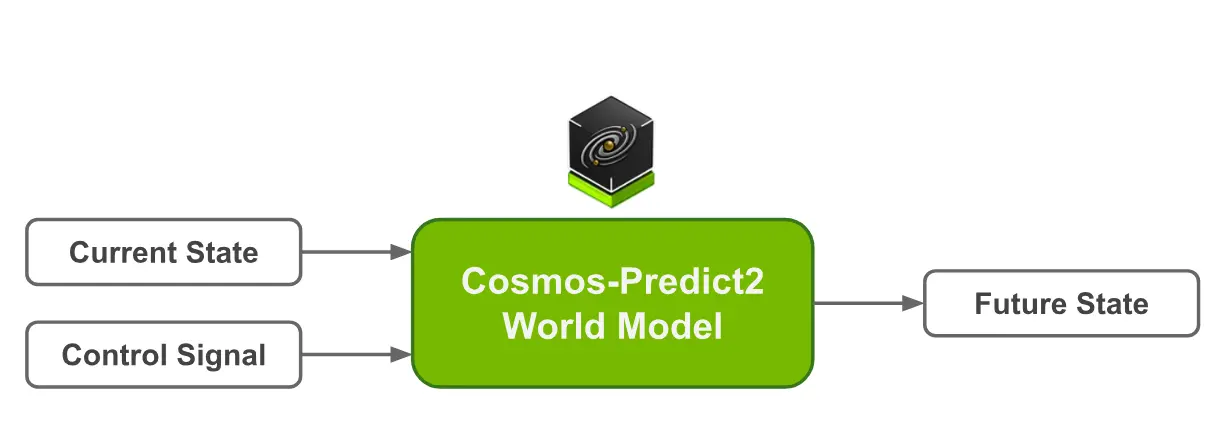
英伟达发布 Cosmos-Predict2:打造物理AI的世界基础模型在物理AI(Physical AI)系统的开发中,模拟真实世界的动态变化至关重要。为此,英伟达推出了 Cosmos-Predict2,作为其 Cosmos 世界模型 的最新演进版本,专为生成具有物理感...多模态模型# Cosmos-Predict2# 世界基础模型# 英伟达10个月前03090
LoRA-Edit:首帧引导+掩膜控制,实现高质量视频编辑的新方法在视频生成与编辑领域,如何在保持整体一致性的同时实现灵活可控的局部修改,一直是一个挑战。近日,来自香港中文大学与商汤研究院的研究团队提出了一种新型视频编辑方法——LoRA-Edit,该方法基于掩膜感知...视频模型# LoRA-Edit# 视频编辑10个月前03150
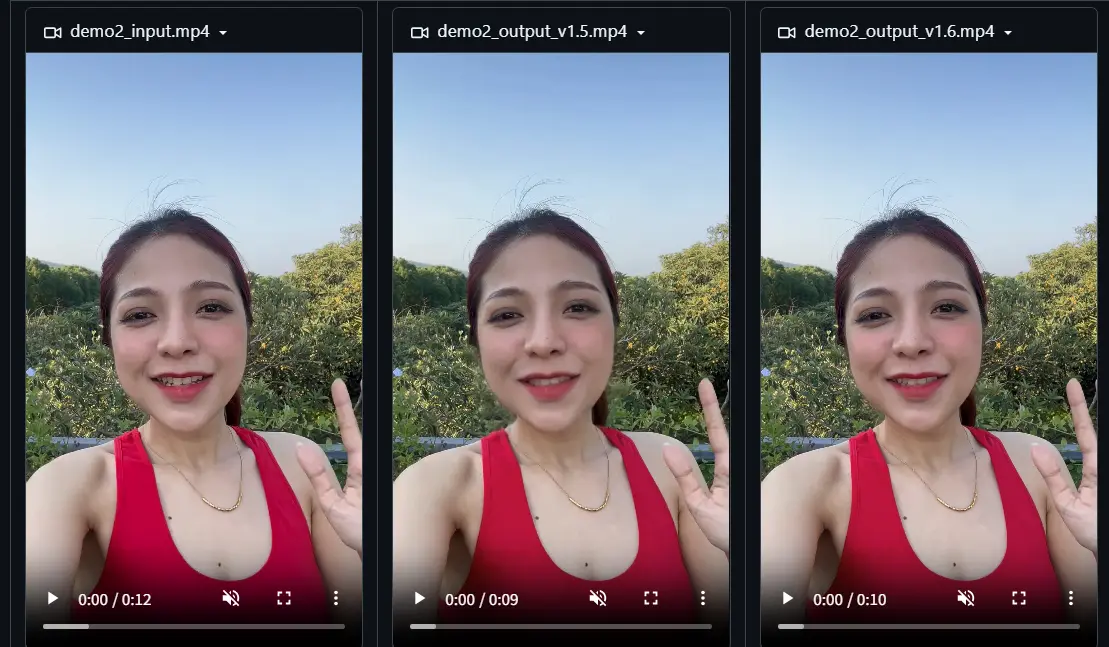
字节跳动发布 LatentSync 1.6:聚焦高分辨率视频生成,解决模糊问题字节跳动发布了其对口型视频生成模型 LatentSync 的新版本 1.6,重点解决了此前版本中生成牙齿和嘴唇区域模糊的问题。 模型:https://huggingface.co/ByteDance...视频模型# LatentSync 1.6# 字节跳动10个月前03330