DeepAgent:一种支持动态工具发现与记忆管理的通用推理代理中国人民大学与小红书联合推出 DeepAgent——一种端到端的深度推理代理框架。它能够在单一、连贯的推理过程中,自主完成思考、工具发现与行动执行,摆脱了传统代理(如 ReAct 框架)中“Reaso...大语言模型# DeepAgent5个月前02270
BRIA 发布 FIBO:用 JSON 精确控制光线、构图与相机参数的文生图模型BRIA 开源发布了其首个文本到图像模型 FIBO —— 一个专为专业图像生成工作流设计的 JSON 原生、结构化提示驱动 的开源模型。与主流强调“想象力”的生成模型不同,FIBO 的核心目标是 可控...图像模型# BRIA# FIBO# 文生图模型5个月前01440
Cognition 发布 SWE-1.5:950 tok/s 高速编码模型,Windsurf 现已可用Cognition 正式推出软件工程专用模型家族新成员——SWE-1.5。作为一款拥有数千亿参数的前沿规模模型,它不仅实现了接近当前最佳水平(SOTA)的编程性能,更在速度上打破现有标准:通过与 Ce...大语言模型# Cognition# SWE-1.5# 编程模型5个月前01730
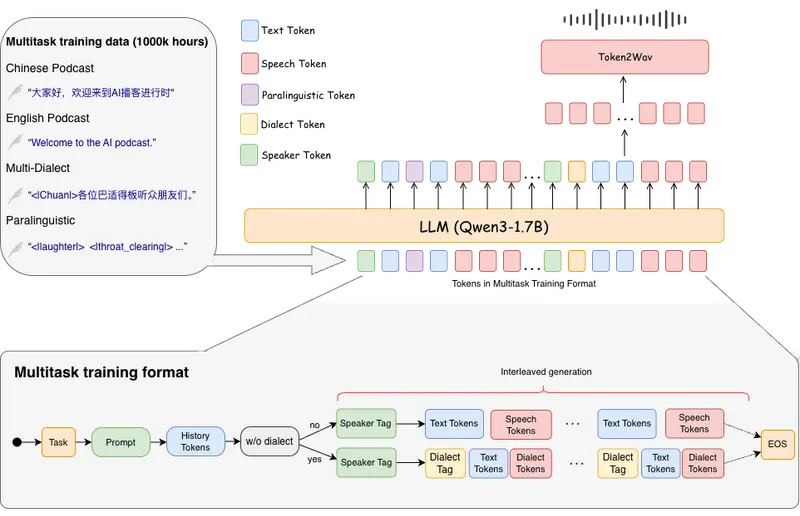
SoulX-Podcast:支持方言与副语言的真实感播客语音合成系统西北工业大学、Soul AI 实验室与上海交通大学联合推出 SoulX-Podcast —— 一个专为长篇、多轮次、多说话者对话场景设计的语音合成系统。它不仅能生成高质量的播客风格对话语音,也在传统单...语音模型# SoulX-Podcast# 播客5个月前01030
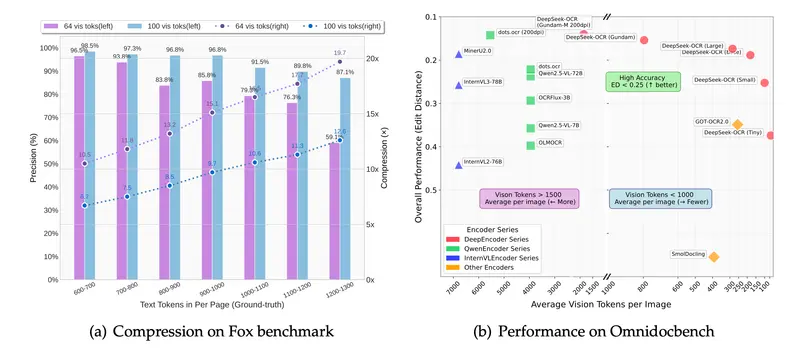
DeepSeek 开源DeepSeek-OCR :用视觉模态压缩文本,3B 小模型撬动长上下文新思路DeepSeek 开源了 DeepSeek-OCR,一个仅 30 亿参数的视觉语言模型(VLM),却在 OCR 与文本压缩领域展现出令人瞩目的创新力。其核心并非追求更大参数量,而是提出一种“光学压缩...多模态模型# DeepSeek# DeepSeek-OCR5个月前01830
快手开源 KAT-Dev-72B-Exp:72B 参数代码模型,SWE-Bench 准确率达 74.6%快手 Kwaipilot 团队近日正式开源 KAT-Dev-72B-Exp ——一个专为软件工程任务设计的 720 亿参数开源大模型。该模型在权威代码修复基准 SWE-Bench Verified 上...大语言模型# KAT-Dev-72B-Exp# 快手6个月前0560
Nanonets开源OCR2系列模型:图像转结构化Markdown+视觉问答双核心Nanonets 正式发布并开源了 OCR2 系列模型,包含 Nanonets-OCR2-Plus、Nanonets-OCR2-3B 与 Nanonets-OCR2-1.5B-exp 三个版本。作为一...多模态模型# Nanonets-OCR2# Qwen2-VL6个月前02470
自动化学术推广系统AutoPR:让学术推广自动化,精准触达目标受众学术研究的价值不仅在于成果本身,更在于被广泛知晓与合理应用。如今,同行评审研究数量持续激增,学者们愈发依赖社交平台发现前沿成果,而作者们也需投入大量精力推广研究,以维持学术可见度与引用率。 项目主页...大语言模型# AutoPR6个月前0670
阿里巴巴 Qwen 推出紧凑型多模态模型 Qwen3-VL 4B/8B,支持 FP8 低显存部署阿里巴巴通义千问(Qwen)团队于 2025 年 10 月 15 日正式发布 Qwen3-VL 4B 与 8B 两款稠密视觉语言模型,每款均提供 指令版(Instruction) 与 思维版(Reas...多模态模型# Qwen3-VL 4B# Qwen3-VL 8B# 多模态模型6个月前03550
Anthropic发布Claude Haiku 4.5:三分之一成本+两倍速度,编码性能追平Sonnet 4Anthropic正式推出轻量级模型Claude Haiku的最新版本——Claude Haiku 4.5。这款模型的核心亮点的是,在保持与Claude Sonnet 4相当编码性能的同时,将成本压缩...大语言模型# Anthropic# Claude Haiku 4.56个月前01570
谷歌升级 AI 视频生成模型Veo 3.1:支持光照编辑、音频生成与视频扩展谷歌正式发布视频生成模型 Veo 3.1 ,并同步更新其面向创作者的 AI 工具 Flow。新版本在视觉真实感、音频支持和编辑能力上均有显著提升,目标是让 AI 生成的视频更接近专业影视水准。 目前...视频模型# Veo 3.1# 谷歌6个月前0590
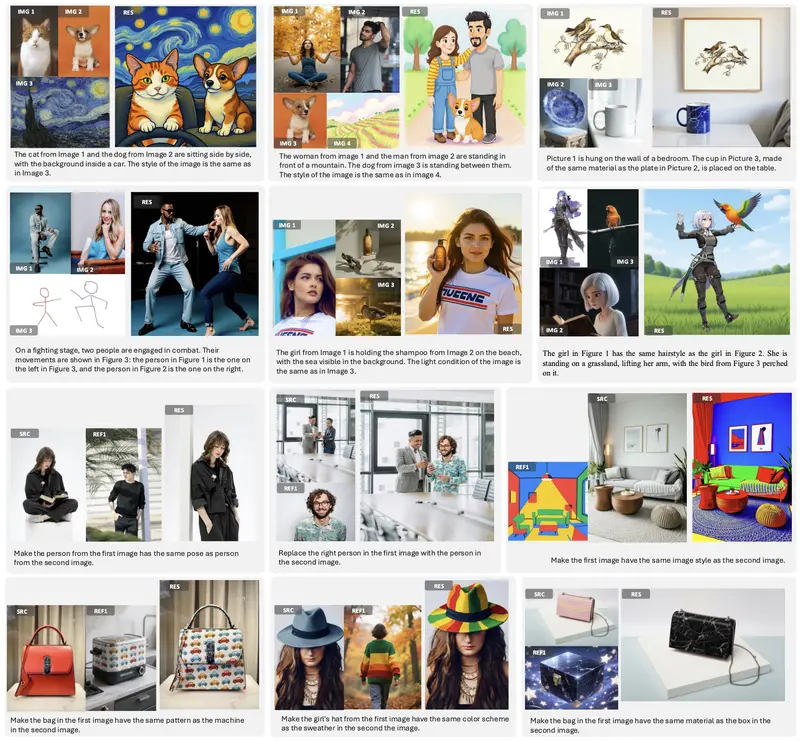
DreamOmni2:支持图文指令的统一图像生成与编辑模型香港中文大学、香港科技大学与字节跳动联合推出开源模型 DreamOmni2,旨在突破当前 AI 图像编辑与生成的两大瓶颈:纯文本指令表达力有限,以及现有模型难以处理抽象概念(如风格、纹理、妆容等)。 ...图像模型# DreamOmni2# 图像生成6个月前01860