阿里开源 Wan2.2-S2V-14B:输入一张图 + 一段音频,生成电影级数字人视频阿里Wan团队正式开源音频驱动视频生成模型Wan2.2-S2V-14B。这款模型打破了传统视频生成对复杂输入的依赖——用户仅需提供一张静态图像与一条音频,即可生成面部表情自然、口型精准同步、肢体动作流...视频模型# Wan2.2-S2V-14B# 数字人# 阿里5个月前04910
阿里推出 Qwen3 系列大模型:开源 8 款模型,性能飞跃,多语言支持,推理能力显著提升阿里 QWEN 团队在今天推出 Qwen3,这是 Qwen 系列大言模型的最新力作。Qwen3 以其卓越的性能和广泛的应用潜力,正在成为开源AI领域的新焦点。 性能突破:超越行业标杆 Qwen3 的旗...大语言模型# QWEN 团队# 阿里巴巴9个月前04900
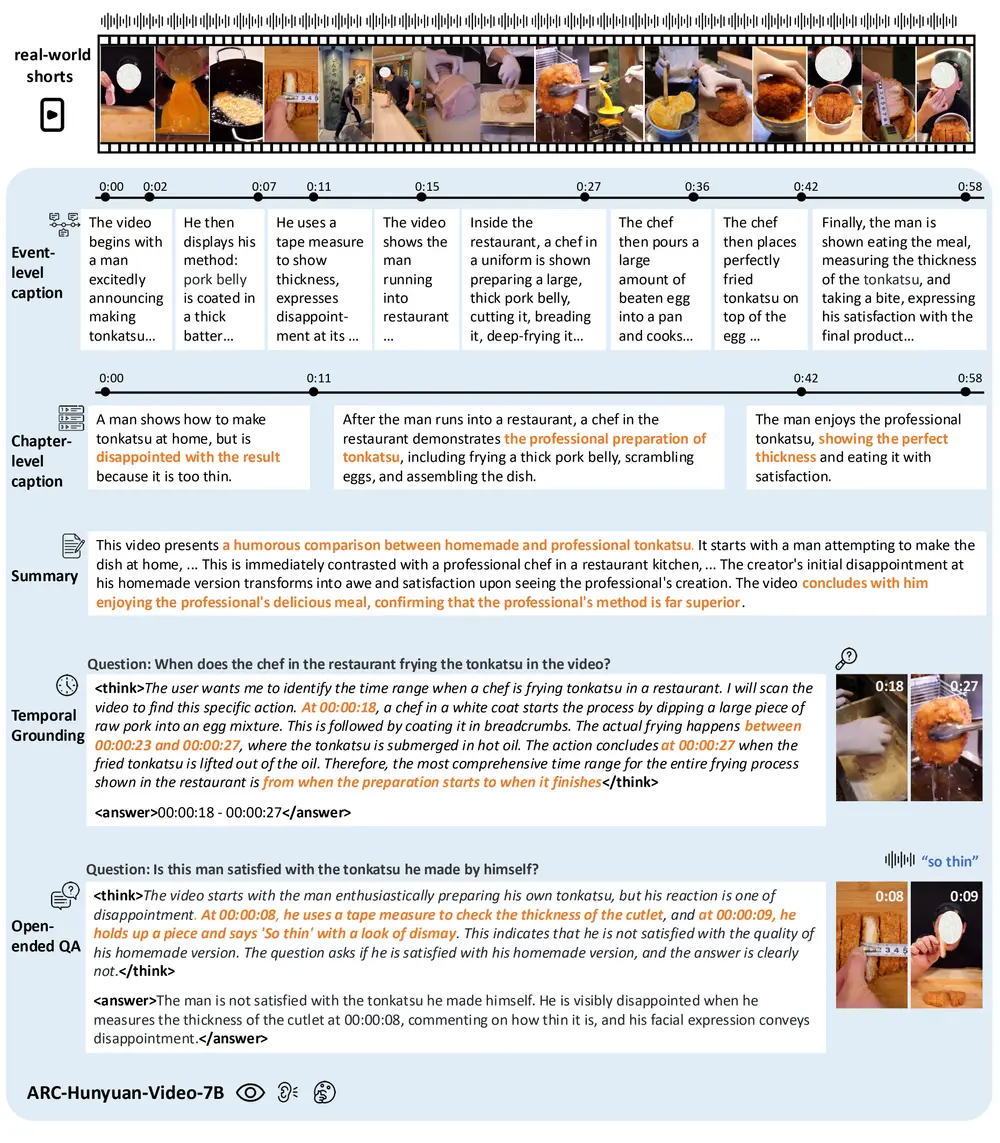
腾讯ARC实验室发布 ARC-Hunyuan-Video-7B:专为短视频理解而生的多模态模型在微信视频号、TikTok 等平台上,每天有数亿条用户生成的短视频被上传。这些视频内容多样、节奏快、信息密度高,往往融合了画面、语音、音效、文字甚至情绪表达。如何让AI真正“理解”这些视频,而不仅仅是...多模态模型# ARC-Hunyuan-Video-7B# 多模态模型# 腾讯ARC实验室6个月前04890
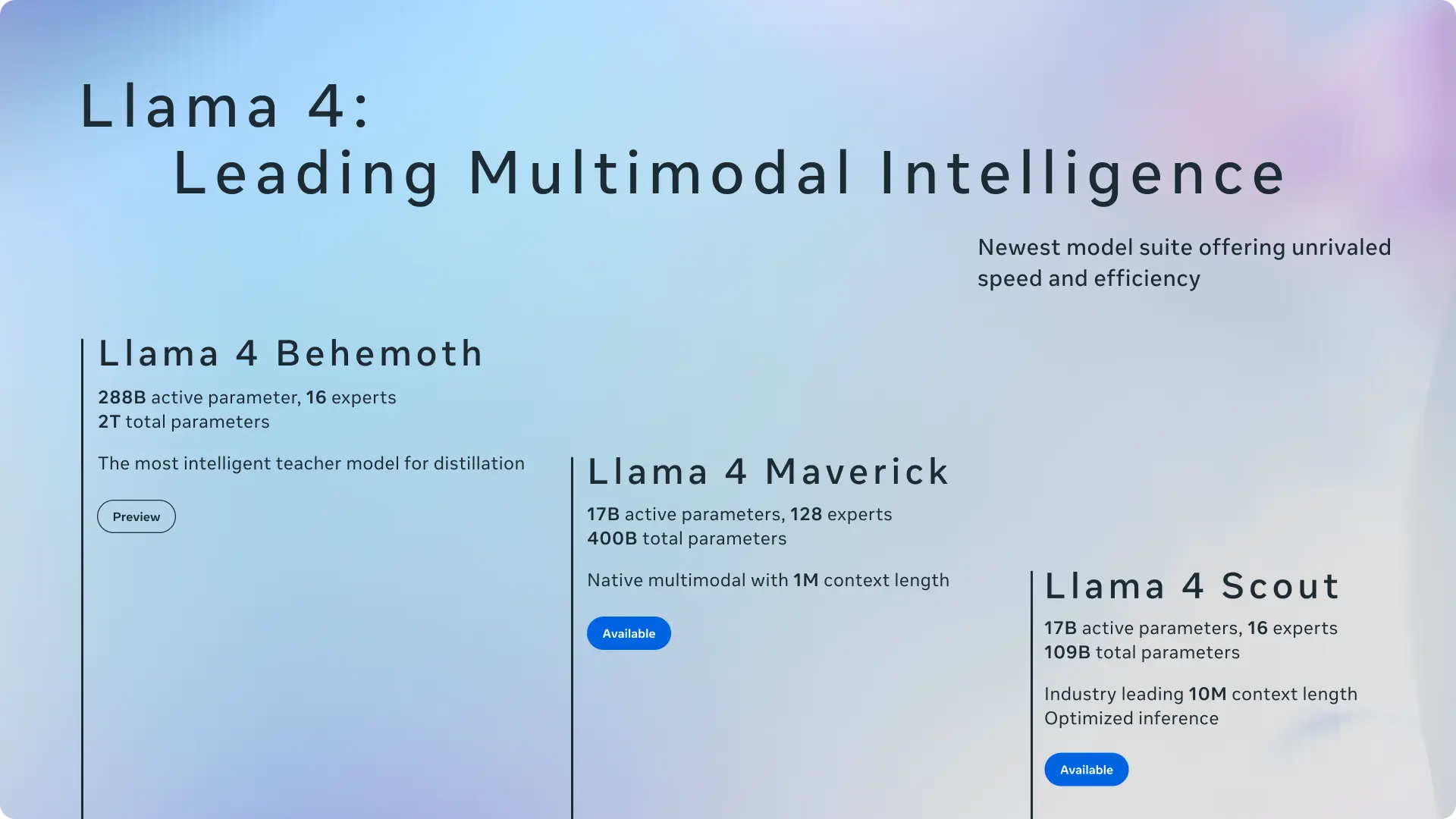
Meta发布Llama 4系列多模态模型:首次采用MoE架构,最高1000万上下文长度2025年4月6日星期日,Meta正式推出了其最新的AI模型系列——Llama 4。这款新模型不仅支持网络版Meta AI助手,还为WhatsApp、Messenger和Instagram等平台提供了...大语言模型# Llama 4# Meta# MoE架构10个月前04890
新型文生图架构Diffusion-RWKV:基于RWKV模型,为改进图像生成任务而设计昆仑万维推出新型文生图架构Diffusion-RWKV,它是为了改进图像生成任务而设计的。这个架构是基于RWKV模型,这是一种在自然语言处理(NLP)领域中使用的模型,但经过了特别的修改,使其更适合处...图像模型# Diffusion-RWKV# RWKV模型# 文生图架构12个月前04890
3D资产生成模型3DTopia-XL:根据文本或视觉输入生成高质量的3D模型南洋理工大学S-Lab、北京大学、上海人工智能实验室和香港中文大学的研究人员推出3D资产生成模型3DTopia-XL,它能够根据文本或视觉输入生成高质量的3D模型。这个模型特别擅长处理具有复杂几何形状...3D模型# 3DTopia-XL# 3D模型12个月前04870
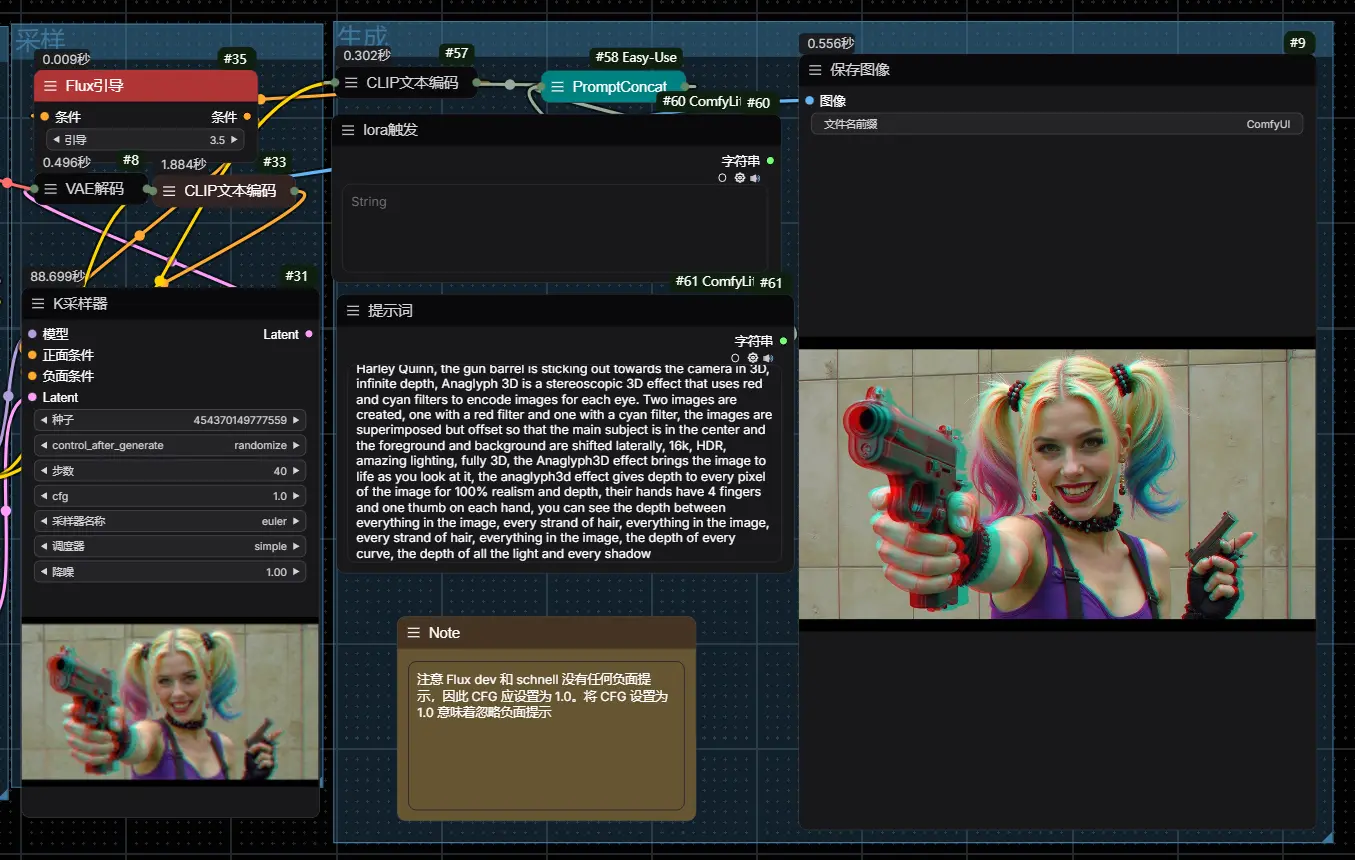
Anaglyph3D:生成3D图像的Flux Lora,不过需要你戴上红蓝 3D 眼镜观看Anaglyph3D是一款能够让你生成3D图像的Flux Lora,不过需要你戴上红蓝 3D 眼镜观看,才能看到图像展现出的效果,红蓝3D眼睛很便宜,只需要几块钱就可以在网上买到。 模型地址:http...Flux衍生# Anaglyph3D# Flux LoRa12个月前04850
阿里Qwen团队发布Qwen3-Next-80B-A3B:用混合注意力 + 高稀疏MoE 实现极致性价比在大模型进入“长上下文”与“超大规模参数”竞争的新阶段,如何平衡性能、训练成本与推理效率,成为决定落地能力的关键。 为此,阿里通义千问(Qwen)项目组正式推出 Qwen3-Next ——一个全新设计...大语言模型# Qwen3-Next# Qwen3-Next-80B-A3B5个月前04840
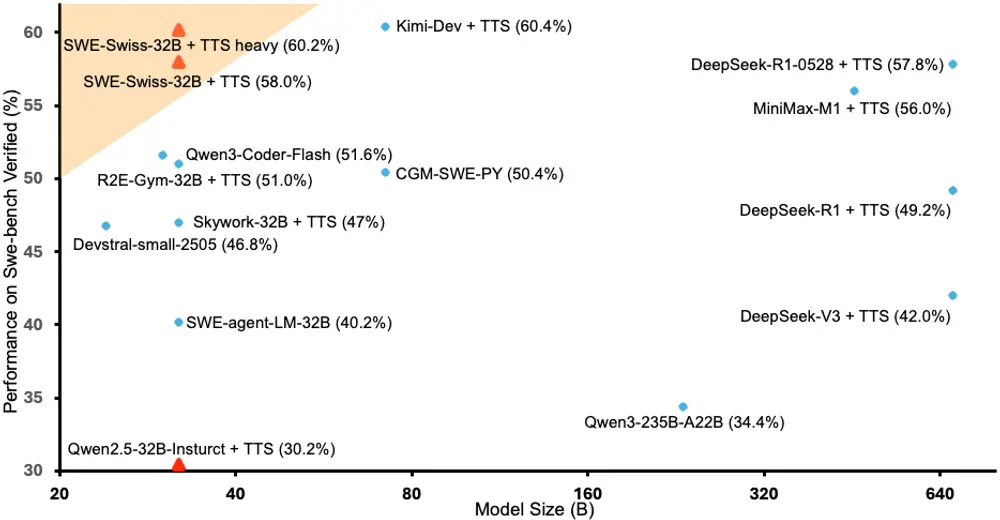
SWE-Swiss-32B 发布:一个在软件修复任务上达到顶尖水平的 32B 开源模型由北京大学、字节跳动 SEED 团队与香港大学联合研发的 SWE-Swiss-32B 正式亮相。 该模型在 SWE-bench Verified 基准测试中取得 60.2% 的通过率,不仅在同规模开源...大语言模型# SWE-Swiss# SWE-Swiss-32B6个月前04820
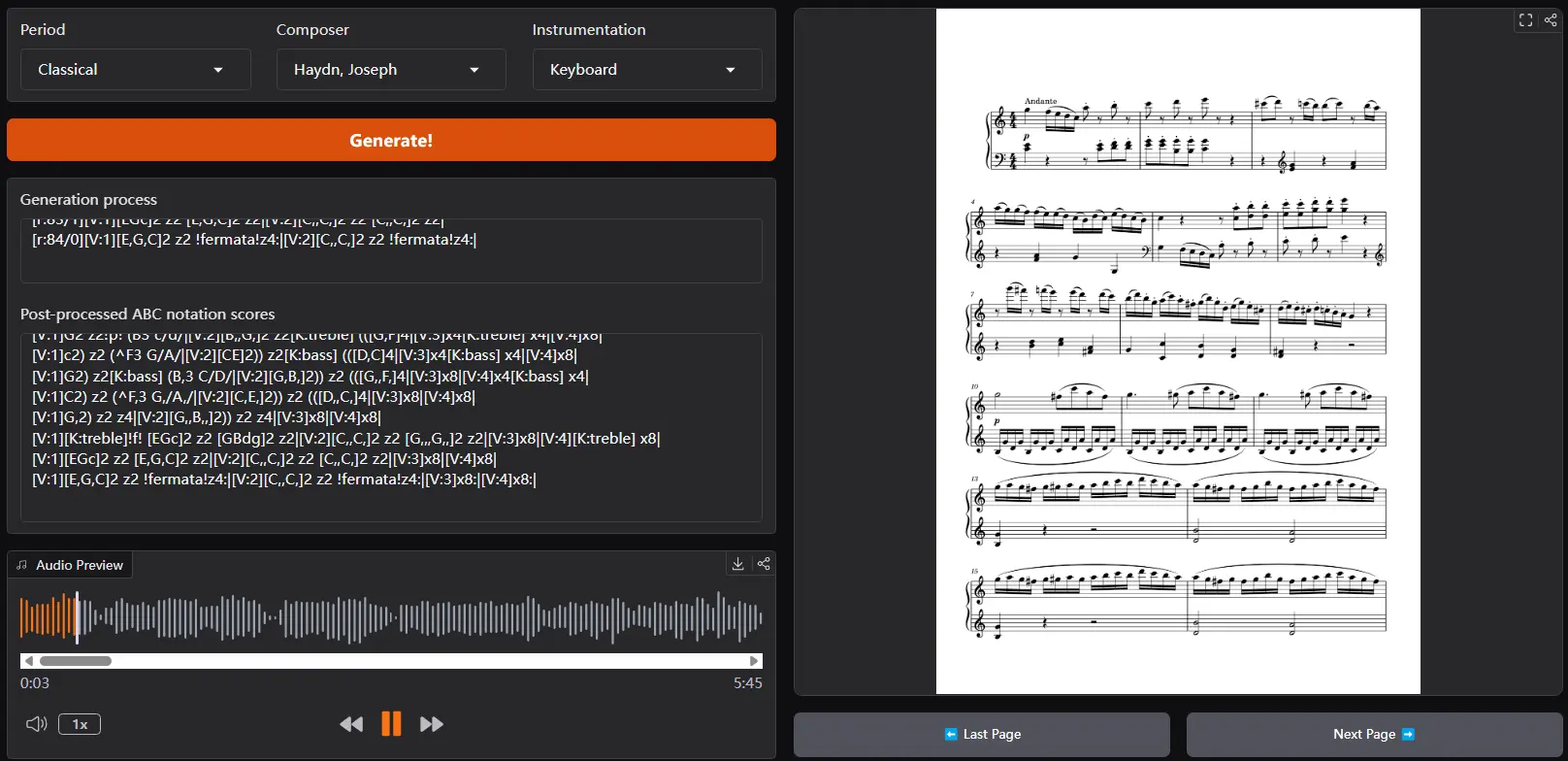
符号音乐生成模型NotaGen:通过借鉴大语言模型(LLM)的训练范式来生成高质量的古典乐谱中央音乐学院、美国罗切斯特大学、北京飞天云动科技、北京航空航天大学和清华大学的研究人员推出符号音乐生成模型NotaGen,通过借鉴大语言模型(LLM)的训练范式来生成高质量的古典乐谱。其在超过 160...语音模型# NotaGen# 古典音乐生成模型11个月前04820
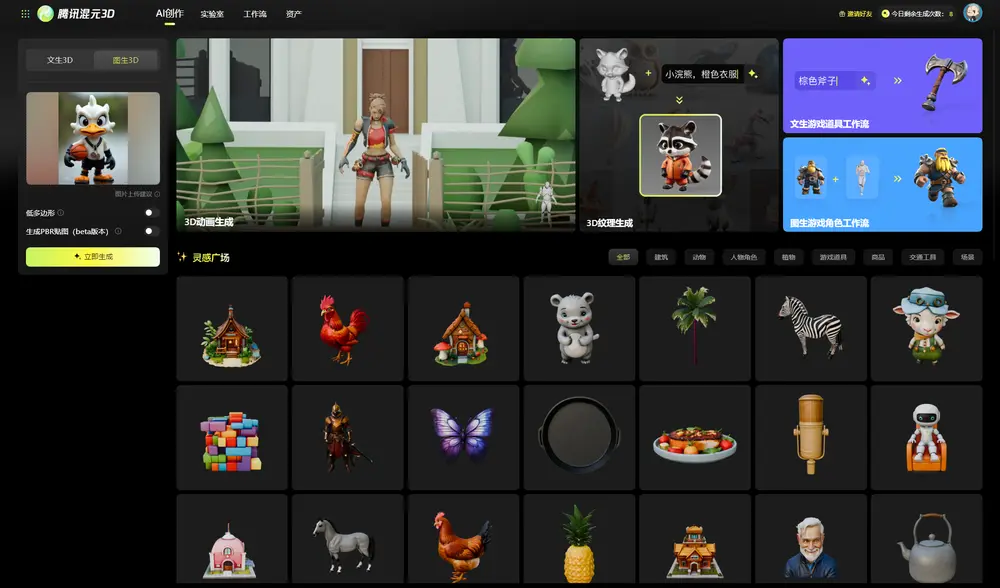
腾讯混元-3D: 首个同时支持 文生和图生的3D开源模型腾讯正式官宣开源上线混元 3D 生成大模型 2.0,腾讯混元还同步上线混元 3D AI 创作引擎,号称是“业界首个一站式 3D 内容 AI 创作平台”。该技术宣称一句话、一张图,甚至画个草图都能生成一...3D模型# 3D开源模型# 混元-3D# 腾讯12个月前04820
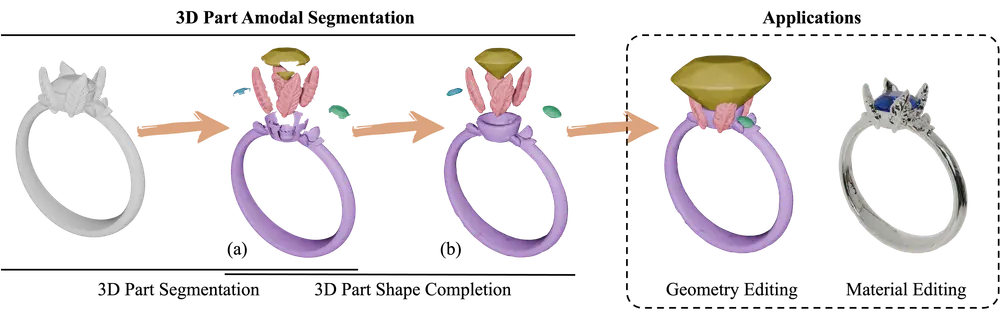
新型3D部件非模态分割模型HoloPart:将3D形状分解为完整的、语义上有意义的部件香港大学和VAST的研究人员推出新型3D部件非模态分割模型HoloPart 。该模型旨在将3D形状分解为完整的、语义上有意义的部件,即使这些部件被部分或完全遮挡。这一任务被称为 3D部件非模态分割,是...3D模型# 3D部件非模态分割模型# HoloPart9个月前04810