Code2Video:基于代码智能体的教育视频生成框架尽管当前文生视频模型在短片段合成上取得进展,但在生成结构严谨、知识准确、视觉连贯的教育视频方面仍面临挑战。这类内容不仅要求语义正确,还需具备清晰的空间布局、逻辑动画过渡和教学节奏控制。 为此,新加坡国...视频模型# Code2Video# 教育视频生成6个月前03350
StreamDiffusionV2:支持多显卡的实时视频生成系统由加州大学伯克利分校、麻省理工学院、斯坦福大学、德克萨斯大学奥斯汀分校与 First Intelligence 联合研发的 StreamDiffusionV2 正式开源。这是一个面向交互式直播场景的实...视频模型# StreamDiffusionV26个月前02710
SLA:清华与伯克利联合提出可训练稀疏线性注意力,加速DiT视频生成在高分辨率、长时序视频生成任务中,扩散变换器(Diffusion Transformer, DiT)已成为主流架构。然而,其核心组件——自注意力机制——面临着一个根本性瓶颈:计算复杂度随序列长度呈平方...视频模型# SLA# 可训练混合注意力机制6个月前01790
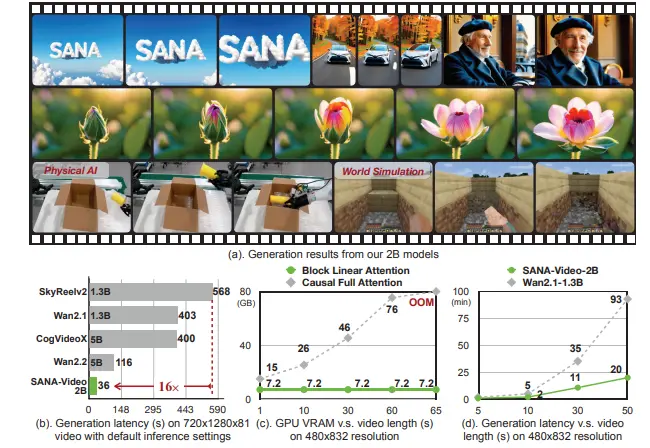
线性注意力 + 恒定内存 KV 缓存!SANA-Video:高效生成分钟级高清视频的新一代文生视频模型在文本到视频(T2V)生成领域,高分辨率、长时长与低延迟三者往往难以兼得。现有大模型虽能生成高质量视频,但动辄数千秒的推理时间与高昂的训练成本严重限制了其落地应用。 为此,由英伟达、香港大学、麻省理工...视频模型# SANA-Video# 文生视频模型6个月前06760
Wan-Alpha:支持透明通道的高质量文生视频模型在视频编辑、虚拟合成、游戏特效和社交媒体创作中,带有透明背景(Alpha 通道)的视频素材具有不可替代的价值——它们可以无缝叠加到任意场景中,无需后期抠像或遮罩处理。 然而,当前主流的文生视频(Tex...视频模型# Wan-Alpha# 文生视频模型6个月前03140
通义万相 Wan2.5-Preview 正式发布:原生支持音画同步的多模态视觉生成引擎阿里通义实验室Wan项目组正式推出 Wan2.5-Preview——一个在架构层面实现革新、真正实现“音视频协同生成”的新一代视觉大模型。 它不是简单的功能叠加,而是通过原生多模态统一架构,将文本、图...视频模型# Wan2.5-Preview6个月前01430
Lynx:字节跳动提出的单图驱动个性化视频生成方案,实现高保真身份保留在内容创作、虚拟社交等场景中,“基于单张图像生成个性化视频”是重要需求——比如用一张自拍生成动态表情视频,或让历史人物照片“动起来”讲述故事。但这类任务长期面临核心挑战:如何在保证视频自然流畅的同时...视频模型# Lynx# 个性化视频生成# 字节跳动7个月前02760
字节跳动提出OmniInsert:无需遮罩,任意对象都能自然插入视频在影视后期、广告制作乃至虚拟内容创作中,“将一个新角色或物体自然地加入已有视频”是一项高频需求。传统方法依赖精确的遮罩标注、关键帧追踪和复杂的合成流程,成本高、耗时长。 近期,基于扩散模型的技术为这一...视频模型# OmniInsert# 字节跳动# 视频编辑7个月前01600
DecartAI推出 Lucy Edit Dev:全球首个开源、支持自由文本提示的指令引导视频编辑模型DecartAI推出 Lucy Edit Dev ——全球首个开源、支持自由文本提示的指令引导视频编辑模型。它允许用户仅通过自然语言描述,即可完成复杂的视频修改任务,如更换服装、替换角色、插入物体或更...视频模型# Lucy Edit Dev# 视频编辑模型7个月前04020
Wan-Animate:阿里通义实验室推出的统一人物动画与替换框架阿里巴巴通义实验室 HumanAIGC 团队近日将推出 Wan-Animate —— 一个基于 Wan 系列模型构建的统一人物动画与角色替换框架。 项目主页:https://humanaigc.git...视频模型# Wan-Animate# 阿里通义实验室7个月前02530
清华大学 & 字节跳动联合推出 HuMo:一个以人为中心的多模态视频生成框架一段文字描述 + 一张人物照片 + 一段语音音频,能否生成一个口型同步、动作自然、形象一致的高质量人物视频? 现在,可以了。 清华大学与字节跳动智能创作团队合作推出 HuMo(Human-Centri...视频模型# HuMo# 字节跳动7个月前0990
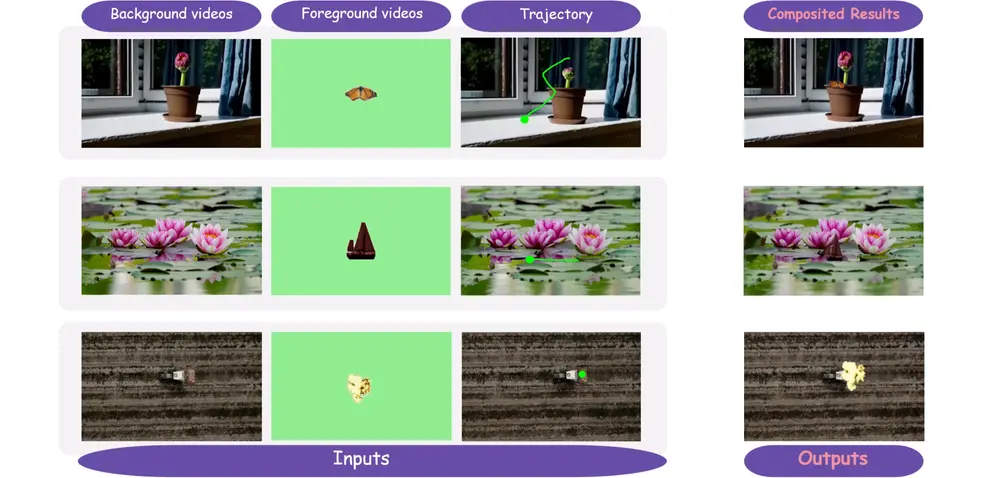
新型视频合成方法GenCompositor:实现轨迹可控的视频级前景融合由北京大学经济与管理学院、腾讯PCG ARC实验室、大湾区大学与香港中文大学联合提出的新型视频合成方法 GenCompositor,为视频创作中的“前景-背景融合”问题提供了一种自动化解决方案。该方法...视频模型# GenCompositor# 视频合成7个月前01100