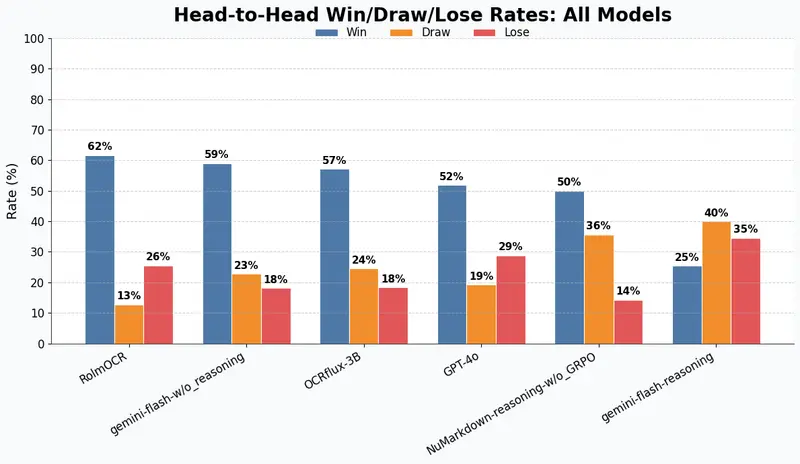
NuMarkdown-8B-Thinking 发布:首个具备推理能力的 OCR 视觉语言模型NuMind 正式推出 NuMarkdown-8B-Thinking —— 据称是首个专为文档理解设计、具备显式推理能力的视觉语言模型(VLM)。该模型专注于将扫描文档或图像中的复杂版式内容,精准转换...多模态模型# NuMarkdown-8B-Thinking# OCR 视觉语言模型7个月前02900
小红书 hi lab 开源首个视觉-语言模型:dots.vlm1小红书 hi lab 团队正式发布 dots.vlm1 ——这是“dots”模型家族中的首款视觉-语言模型(VLM),标志着其在多模态理解方向上的重要突破。 GitHub:https://github...多模态模型# dots.vlm1# 小红书7个月前03540
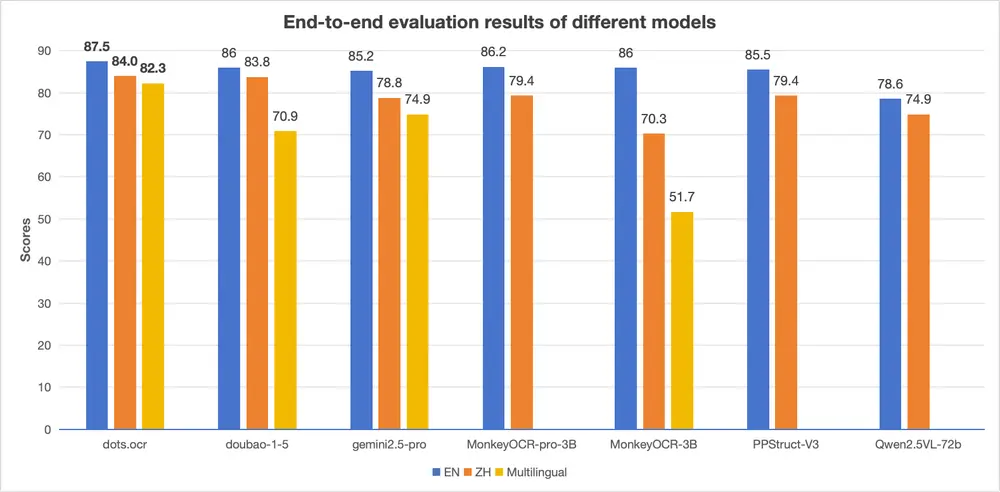
小红书 hi lab 推出 dots.ocr:一个更高效、更统一的文档解析方案小红书 hi lab 团队近期发布了一款名为 dots.ocr 的多语言文档解析模型。它不是传统OCR工具的简单升级,而是一次架构层面的重构——将布局检测与内容识别统一在一个视觉-语言模型(VLM)中...多模态模型# dots.ocr# 小红书7个月前01,1200
昆仑万维天工项目组推出多模态模型Skywork UniPic:能够统一处理图像理解、文本到图像生成和图像编辑等多种任务昆仑万维天工项目组推出多模态模型Skywork UniPic,它是一个参数量为15亿的自回归模型,能够统一处理图像理解、文本到图像生成和图像编辑等多种任务,而无需针对每个任务单独适配或连接模块。 Gi...多模态模型# Skywork UniPic# 多模态模型7个月前03560
面壁智能发布高效多模态模型 MiniCPM-V 4.0:4B 模型,超越 GPT-4.1-mini面壁智能正式推出 MiniCPM-V 4.0 —— MiniCPM-V 系列中最新的高效多模态模型,参数总量仅 4.1B,却在图像理解能力上实现显著突破。 GitHub:https://github...多模态模型# MiniCPM-V 4.0# 面壁智能7个月前01820
Cohere 推出 Command A Vision:专为企业打造的高效多模态 AI今天,AI 不再只是“读文字”的工具。越来越多的企业需要系统能“看懂”图像——从产品手册、工程图纸到财务报表、现场照片。 为此,Cohere 正式发布 Command A Vision —— 一款专为...多模态模型# Cohere# Command A Vision7个月前01200
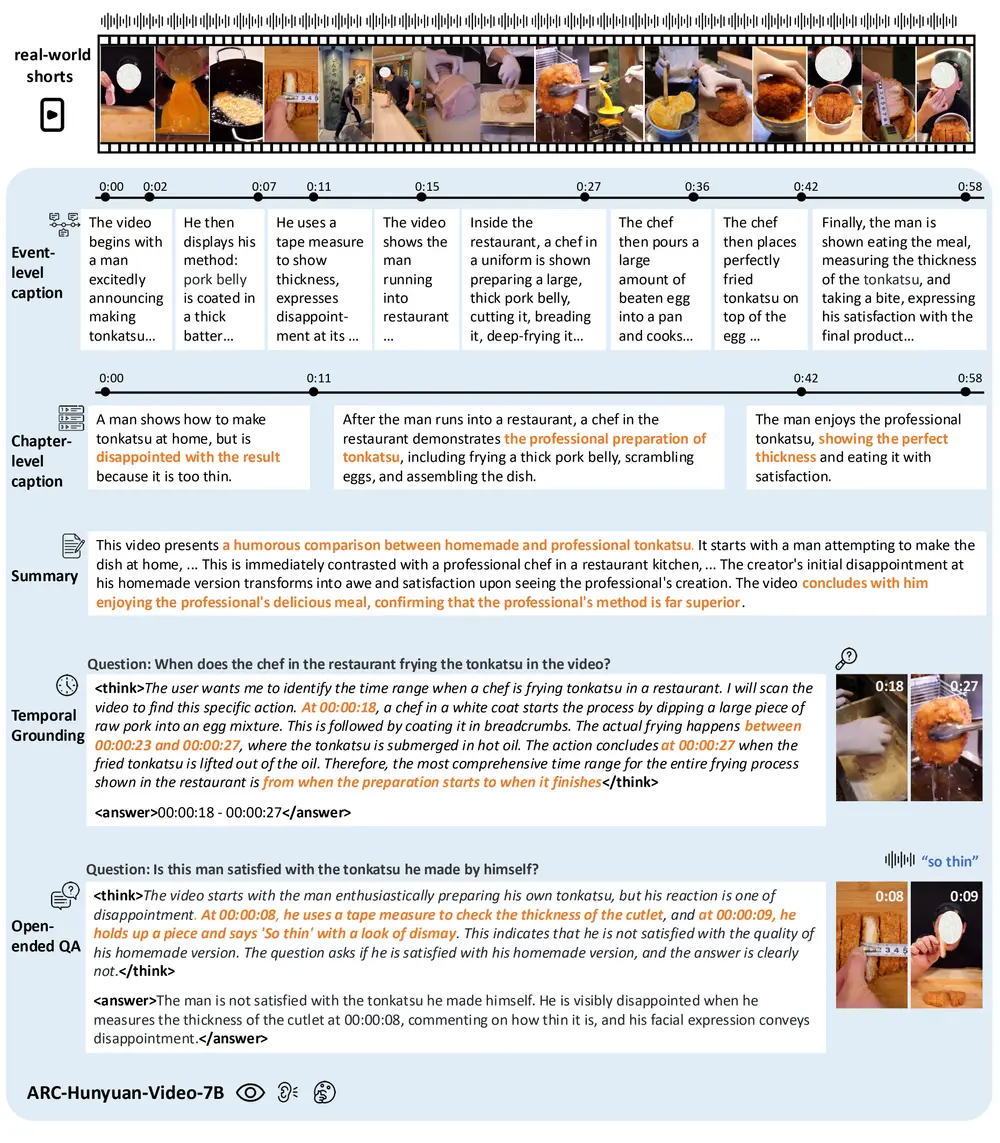
腾讯ARC实验室发布 ARC-Hunyuan-Video-7B:专为短视频理解而生的多模态模型在微信视频号、TikTok 等平台上,每天有数亿条用户生成的短视频被上传。这些视频内容多样、节奏快、信息密度高,往往融合了画面、语音、音效、文字甚至情绪表达。如何让AI真正“理解”这些视频,而不仅仅是...多模态模型# ARC-Hunyuan-Video-7B# 多模态模型# 腾讯ARC实验室8个月前05210
上海AI实验室发布书生 Intern-S1:专为科研打造的多模态AI助手上海AI实验室正式推出 Intern-S1 —— 一款具备强大科学理解能力的开源多模态推理模型。它不仅在通用任务上表现卓越,更在化学、生物、数学、物理等多个科学领域达到最先进的性能水平,部分指标甚至超...多模态模型# Intern-S1# 上海AI实验室# 书生7个月前03200
蚂蚁集团发布Ming-lite-omni v1.5:全模态能力的全面升级由 蚂蚁集团旗下的 百灵大模型(Ling)团队研发的全模态大模型 Ming-lite-omni v1.5 正式发布。作为对初代模型的全面升级,v1.5 版本在图像、文本、视频、语音等多种模态的理解与生...多模态模型# Ming-lite-omni v1.5# 蚂蚁集团8个月前03160
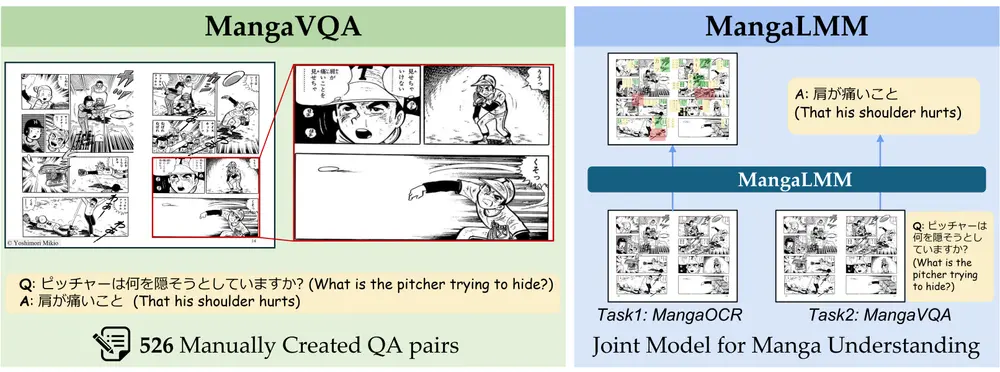
东京大学推出基准测试MangaVQA和多模态漫画理解模型MangaLMM东京大学的研究人员推出一个名为 MangaVQA 的基准测试和一个名为 MangaLMM 的专门模型,用于多模态漫画理解。漫画(Manga)是一种将图像和文本以复杂方式结合的叙事形式,理解漫画需要同时...多模态模型# MangaLMM# MangaVQA# 东京大学8个月前01550
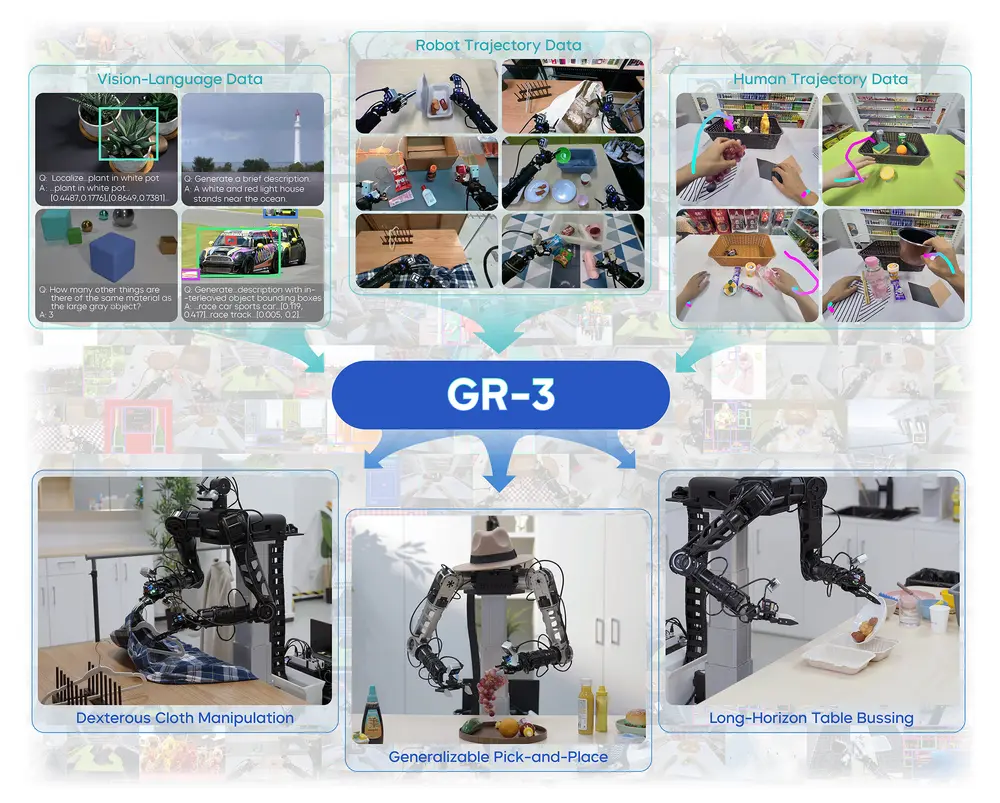
字节跳动Seed团队发布新一代机器人操作大模型Seed GR-3字节跳动Seed团队近日推出一款面向复杂操作任务的大规模机器人模型——Seed GR-3(Generalist Robot Model-3)。该模型具备良好的泛化能力,支持长序列任务执行与多模态指令理...多模态模型# Seed GR-3# 字节跳动8个月前01900
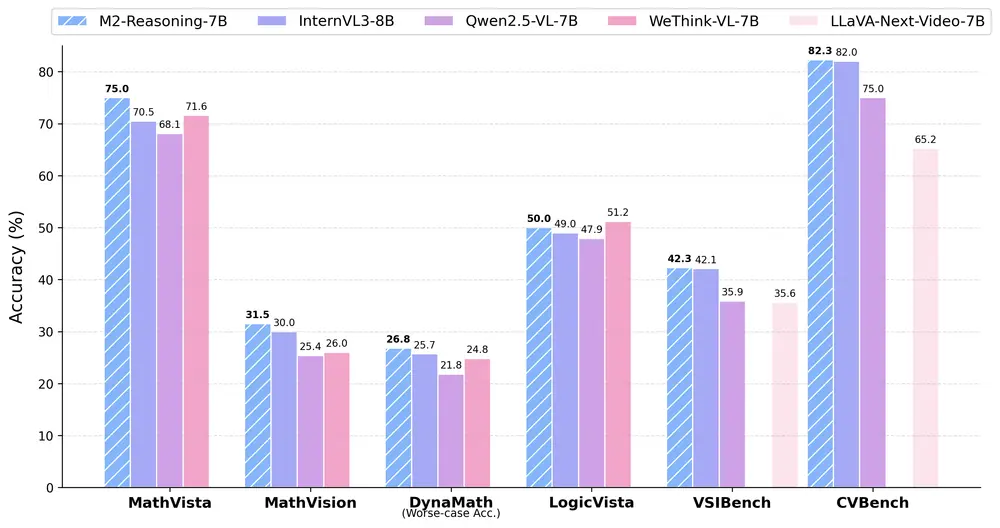
蚂蚁集团发布 M2-Reasoning-7B:通用与空间推理能力领先的多模态大模型蚂蚁集团 inclusionAI 项目组 正式发布 M2-Reasoning-7B,一个在通用推理与空间推理领域表现卓越的多模态大语言模型(MLLM)。该模型基于 70 亿参数架构,通过创新的数据生成...多模态模型# M2-Reasoning-7B# 多模态大模型# 蚂蚁集团8个月前01920