STARFlow-V:苹果推出标准化流视频生成模型,挑战扩散模型主流地位苹果最新发布的 STARFlow-V 为视频生成领域带来了全新技术路径——作为一款基于标准化流(Normalizing Flows)的端到端模型,它打破了当前扩散模型主导的格局,凭借全局-局部架构、因...视频模型# STARFlow-V# 流视频生成模型# 苹果4个月前01040
SteadyDancer:用 I2V 范式解决首帧失真,生成身份一致的高保真人像动画人体图像动画技术迎来颠覆性突破!南京大学、腾讯与上海AI实验室联合推出的SteadyDancer框架,通过彻底摒弃传统参考图到视频(R2V)范式,转向图像到视频(I2V)全新思路,从根源上解决了长期困...视频模型# SteadyDancer4个月前01330
腾讯开源HunyuanVideo-1.5:83亿参数实现顶级画质,14G显存消费级显卡即可运行在视频生成模型多追求大参数堆料的当下,腾讯混元项目组推出的HunyuanVideo-1.5走出了一条“小而精”的差异化路线。这款仅搭载83亿参数的轻量级视频生成模型,不仅实现了开源领域顶尖的视觉质量与...视频模型# HunyuanVideo-1.5# 腾讯4个月前01330
Kandinsky 5.0 全系列开源:190亿参数视频Pro+轻量版,支持中俄双语+5-10秒HD生成来自俄罗斯的AI企业Sber AI,正式推出新一代扩散模型家族 Kandinsky 5.0,以“全场景覆盖+开源开放”为核心亮点,涵盖视频生成(T2V/I2V)、图像生成(T2I)、图像编辑三大核心能...图像模型视频模型# Kandinsky 5.04个月前01900
美团 LongCat 团队发布 LongCat-Video:高效长视频生成的开源新标杆美团LongCat团队推出 LongCat-Video,这是一个基础视频生成模型,拥有 13.6B 参数,在文本到视频、图像到视频以及视频续接生成任务中表现出色。它特别擅长高效且高质量的长视频生成,标...视频模型# LongCat# LongCat-Video# 美团5个月前0350
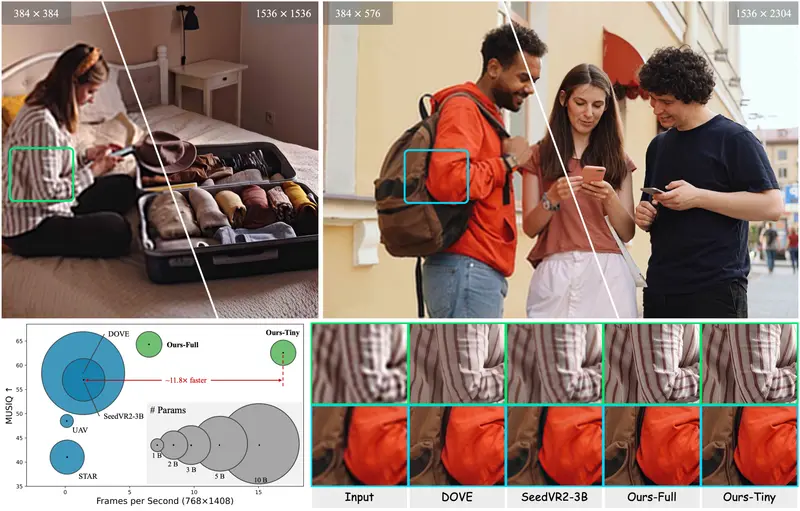
FlashVSR:首个实时扩散视频超分框架,17 FPS 处理 1408p 视频视频超分辨率(Video Super-Resolution, VSR)的目标是将低分辨率视频高质量地重建为高分辨率版本。近年来,扩散模型在图像和视频恢复任务中展现出强大能力,但其高延迟、高计算开销和对...视频模型# FlashVSR# 视频超分辨率框架5个月前0410
谷歌升级 AI 视频生成模型Veo 3.1:支持光照编辑、音频生成与视频扩展谷歌正式发布视频生成模型 Veo 3.1 ,并同步更新其面向创作者的 AI 工具 Flow。新版本在视觉真实感、音频支持和编辑能力上均有显著提升,目标是让 AI 生成的视频更接近专业影视水准。 目前...视频模型# Veo 3.1# 谷歌6个月前0590
新加坡国立大学推出 PaperTalker:首个从论文自动生成学术演讲视频的多智能体框架对于研究人员来说,将一篇论文转化为一场高质量的学术演示视频,往往意味着数小时的设计、录制与剪辑——即使最终视频只有5到10分钟。 幻灯片排版、语音同步、字幕对齐、讲解节奏控制……这些重复性工作消耗大量...视频模型# PaperTalker6个月前02940
Code2Video:基于代码智能体的教育视频生成框架尽管当前文生视频模型在短片段合成上取得进展,但在生成结构严谨、知识准确、视觉连贯的教育视频方面仍面临挑战。这类内容不仅要求语义正确,还需具备清晰的空间布局、逻辑动画过渡和教学节奏控制。 为此,新加坡国...视频模型# Code2Video# 教育视频生成6个月前03250
StreamDiffusionV2:支持多显卡的实时视频生成系统由加州大学伯克利分校、麻省理工学院、斯坦福大学、德克萨斯大学奥斯汀分校与 First Intelligence 联合研发的 StreamDiffusionV2 正式开源。这是一个面向交互式直播场景的实...视频模型# StreamDiffusionV26个月前02680
SLA:清华与伯克利联合提出可训练稀疏线性注意力,加速DiT视频生成在高分辨率、长时序视频生成任务中,扩散变换器(Diffusion Transformer, DiT)已成为主流架构。然而,其核心组件——自注意力机制——面临着一个根本性瓶颈:计算复杂度随序列长度呈平方...视频模型# SLA# 可训练混合注意力机制6个月前01750
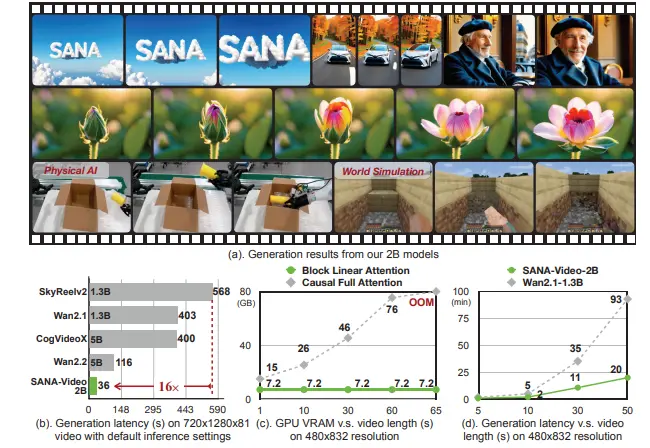
线性注意力 + 恒定内存 KV 缓存!SANA-Video:高效生成分钟级高清视频的新一代文生视频模型在文本到视频(T2V)生成领域,高分辨率、长时长与低延迟三者往往难以兼得。现有大模型虽能生成高质量视频,但动辄数千秒的推理时间与高昂的训练成本严重限制了其落地应用。 为此,由英伟达、香港大学、麻省理工...视频模型# SANA-Video# 文生视频模型6个月前06760