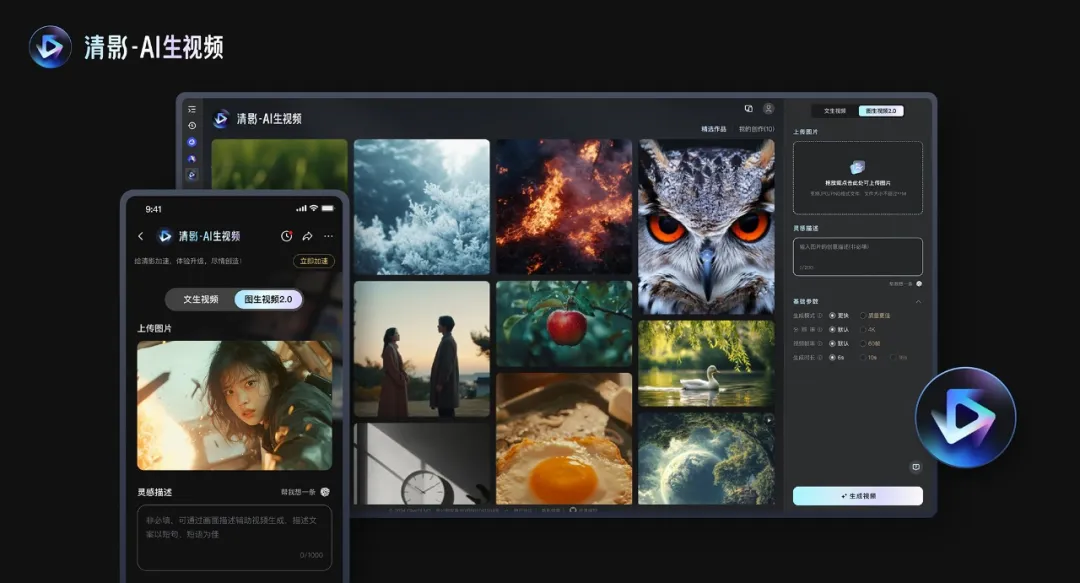
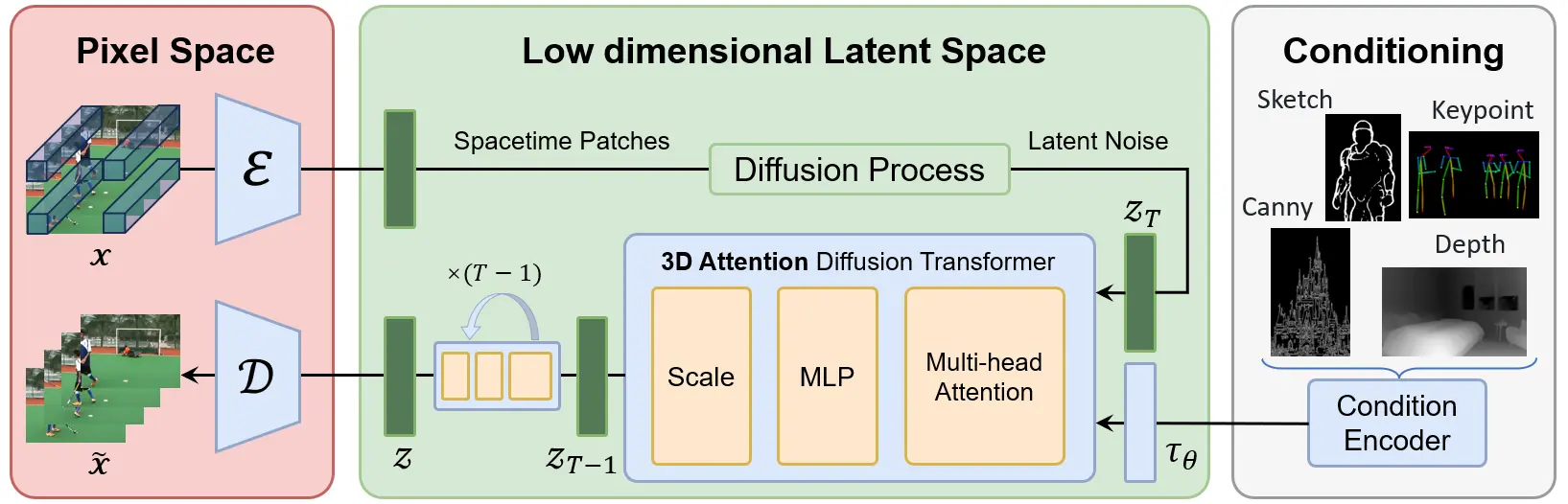
智谱AI推出CogVideoX 开源模型的升级版本CogVideoX1.5-5B智谱技术团队对于旗下开源视频生成模型CogVideoX进行了升级,今天释出了CogVideoX1.5-5B 系列模型,相比于原有模型,CogVideoX v1.5 将包含 5/10 秒、768P、16...视频模型# CogVideoX1.5-5B# 智谱AI# 智谱清影12个月前06690
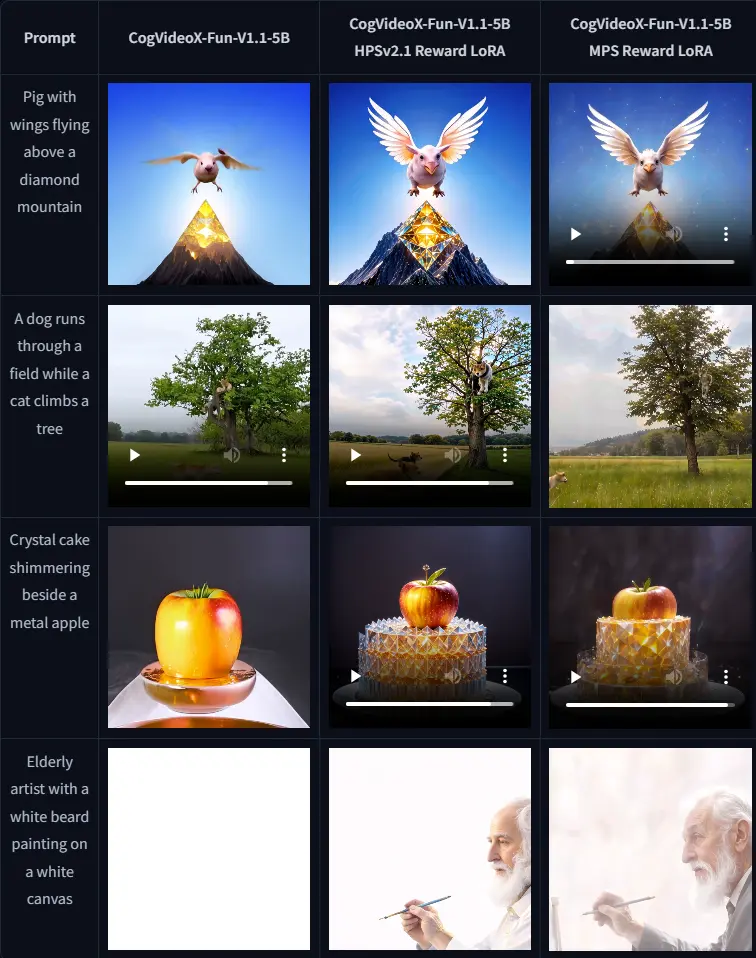
CogVideoX-Fun-V1.1-Reward-LoRAs:通过奖励反向传播技术训练Lora,以优化CogVideoX-Fun-V1.1生成的视频CogVideoX-Fun-V1.1-Reward-LoRAs是通过奖励反向传播技术训练Lora,以优化CogVideoX-Fun-V1.1生成的视频,使其更好地与人类偏好保持一致。 地址:https...视频模型# CogVideoX-Fun-V1.1# CogVideoX-Fun-V1.1-Reward-LoRAs12个月前03490
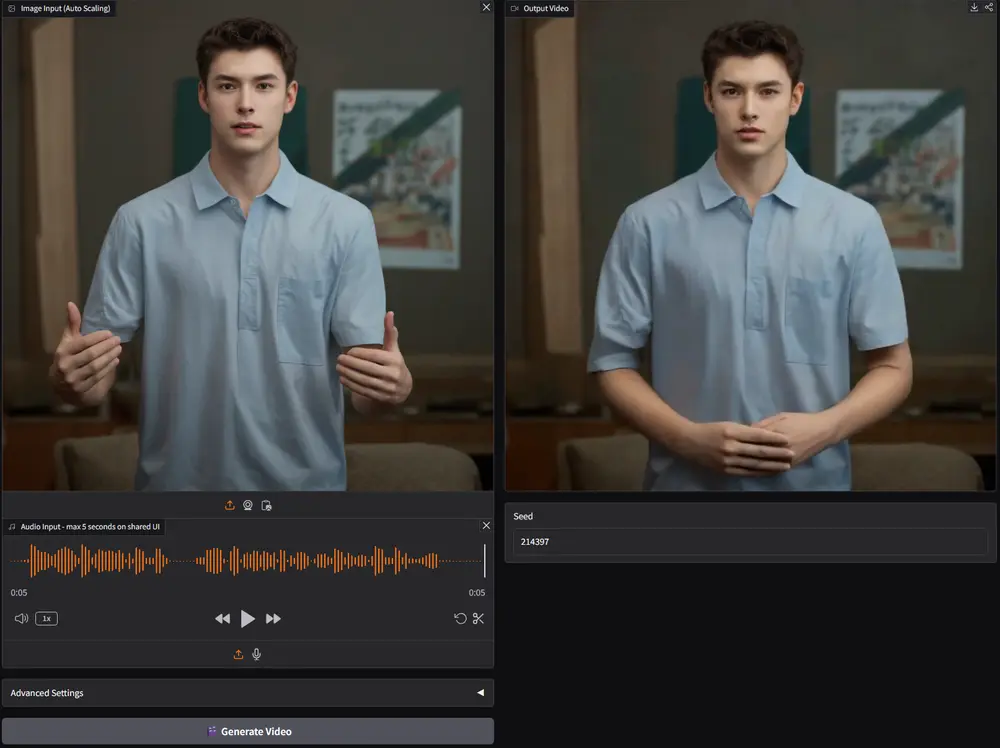
半身人体动画生成框架 EchoMimicV2:利用参考图像、音频剪辑和一系列手部姿势来生成高质量的动画视频随着计算机图形学和人工智能的发展,生成高质量的人类动画变得越来越重要。特别是,当涉及到创建生动、自然的动画时,音频、姿势或运动图等条件的引入大大提升了动画的真实性和表现力。然而,这些增强的方法也带来了...视频模型# EchoMimicV2# 动画生成12个月前04740
Rhymes AI开源图生视频模型Allegro-TI2V:根据用户提供的提示和图像生成视频Rhymes AI之前开源了视频生成模型Allegro,近期它们又推出了Allegro-TI2V。作为原始Allegro模型的迭代,Allegro-TI2V提供了前所未有的能力,将文本描述和图像转化为...视频模型# Allegro-TI2V# Rhymes AI12个月前02970
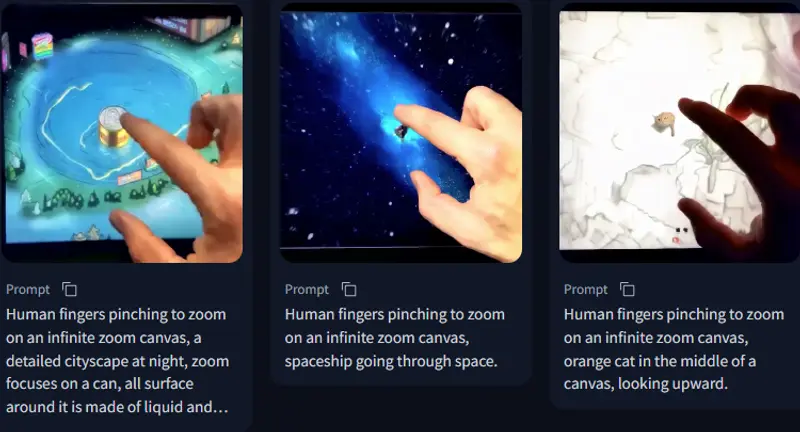
InfiniteZoom-Mochi:基于视频生成模型Mochi的LoRA,专注于无限缩放艺术风格InfiniteZoom-Mochi是一个视频生成模型Mochi的LoRA,专注于无限缩放艺术风格。无限缩放艺术风格是一种独特的视觉效果,通过不断放大图像的某个部分,创造出一种无限深入的感觉。应用此L...视频模型# InfiniteZoom-Mochi# 无限缩放12个月前02590
腾讯发布开源视频生成模型—混元文生视频模型HunyuanVideo腾讯在今天正式开源了其最新的视频生成模型—混元文生视频模型HunyuanVideo。这款模型不仅在视频生成能力上与业界领先的闭源模型相匹敌,甚至在某些方面表现更为出色。作为一款综合性的框架,Hunyu...视频模型# HunyuanVideo# 混元文生视频模型# 腾讯12个月前04230
开源视频生成项目Open-Sora Plan:基于多种用户输入生成高分辨率、长时长的理想视频由北大-兔展AIGC联合实验室共同发起的Open-Sora Plan,目标是复现OpenAI的Sora模型。这是一个开源的大型视频生成模型项目,旨在基于多种用户输入生成高分辨率、长时长的理想视频。该项...视频模型# Open-Sora Plan12个月前02760
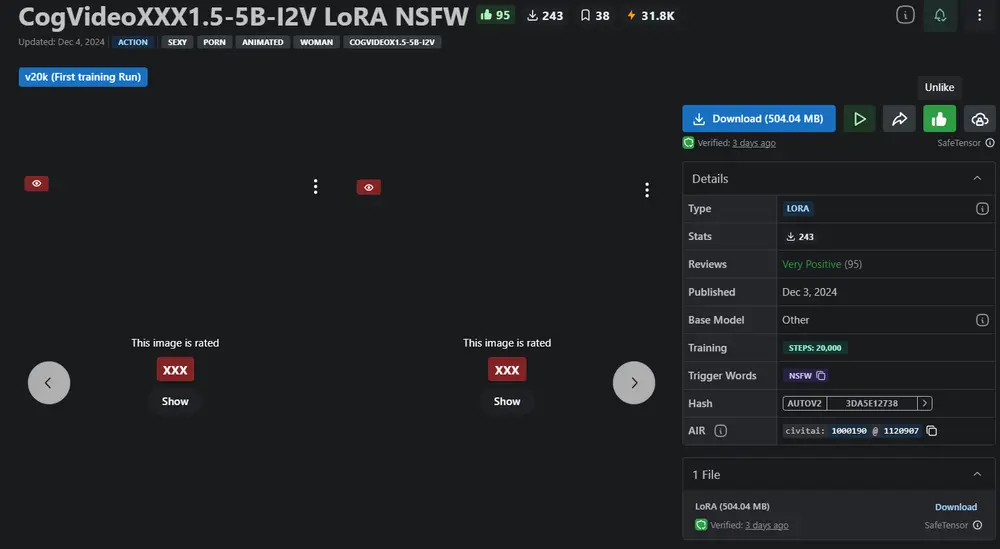
CogVideoXXX1.5-5B-I2V LoRA NSFW :基于 CogVideoX1.5-5B 的LoRA模型,专门针对NSFW内容进行了训练CogVideoXXX1.5-5B-I2V LoRA NSFW 是一个基于 CogVideoX1.5-5B 的LoRA模型,专门针对NSFW内容进行了训练。该模型在处理NSFW内容时表现出色,但也具备...视频模型# CogVideoX1.5-5B# LoRA模型12个月前03190
LIFT:利用人类反馈进行文生视频模型对齐的新型微调方法文本到视频(T2V)生成模型近年来取得了显著进展,能够生成高质量的合成视频。然而,这些模型在将合成视频与人类偏好(例如,准确反映文本描述)对齐方面仍然存在不足。复旦大学、上海人工智能科学院和阿德莱德大...视频模型# LIFT# 微调# 文生视频模型12个月前03550
人体图像动画生成DisPose:从参考图像和驱动视频中生成视频,同时保持人物外观的一致性,并允许对动画进行精确控制可控的人体图像动画旨在使用驱动视频从参考图像生成视频。为了确保运动对齐,最近的工作尝试引入额外的密集条件(例如,深度图),但这些方法在参考角色的体型与驱动视频中的体型显著不同时,可能会损害生成视频的质...视频模型# DisPose# 人体图像动画生成12个月前03280
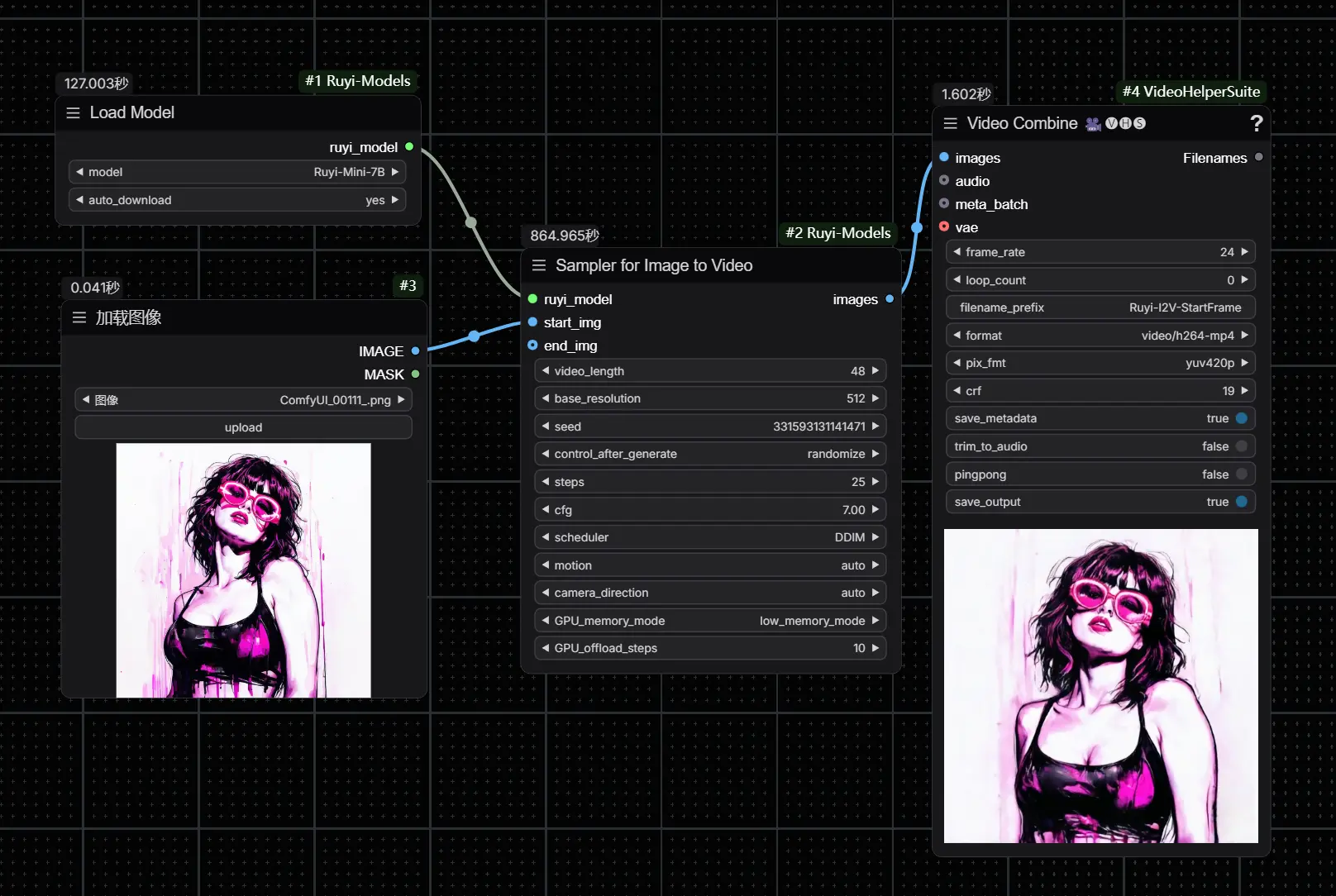
图森未来发布图生视频大模型“Ruyi”,能够在消费级显卡上运行图森未来今日正式发布了其首款“图生视频”大模型——Ruyi,目前Ruyi-Mini-7B版本已经正式释出。这款模型专为生成高质量的影视级视频而设计,能够在消费级显卡(如 RTX 3090 或 RTX ...插件视频模型# Ruyi# 图森未来# 图生视频大模型12个月前04020
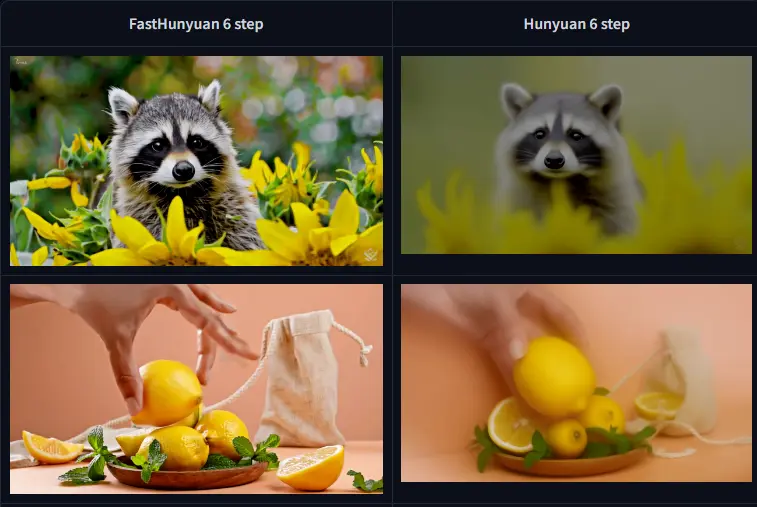
加速DiT架构视频生成模型的开源技术栈FastVideo:已推出FastHunyuan和FastMochi 两款模型,生成速度提升8倍加州大学圣地亚哥分校 Hao AI 实验室推出的一个开源技术栈FastVideo ,旨在显著加速最先进的(SoTA)开源DiT架构视频生成模型的推理速度。它通过引入 一致性蒸馏(Consistency...视频模型# FastHunyuan# FastMochi# FastVideo12个月前03990