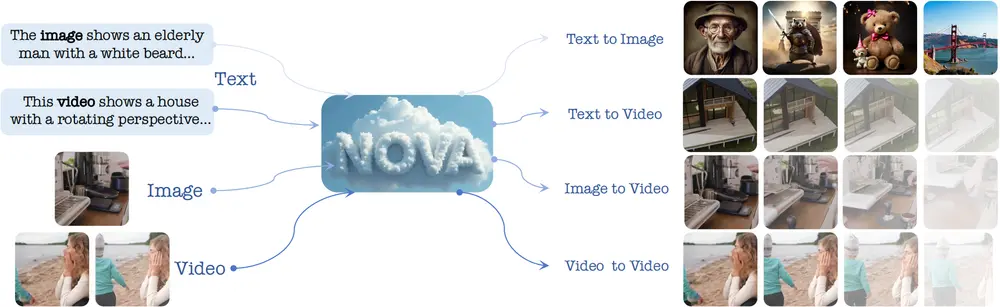
新型自回归视频生成模型NOVA:能够在无需向量量化的情况下,高效地生成视频北京邮电大学、中国科学院计算技术研究所、大连理工大学和北京智源研究院的研究人员提出了一种名为 NOVA 的新型自回归视频生成模型。该模型能够在无需向量量化的情况下,通过重新表述视频生成问题,实现了在时...视频模型# NOVA# 自回归视频生成模型12个月前03250
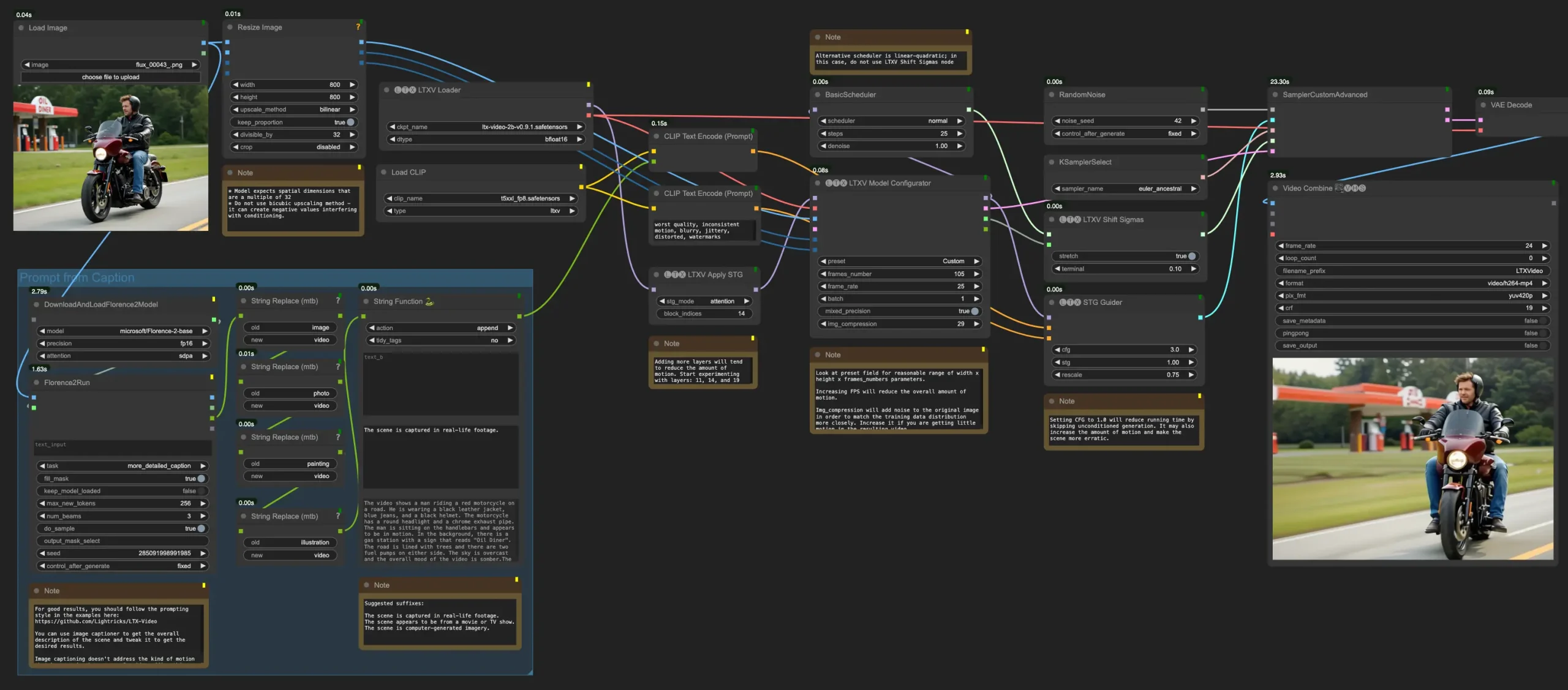
LTX-Video推出0.9.1版本,引入全新VAE解码器,原生支持STG/PAG之前介绍过的《Lightricks推出开源视频生成模型LTX Video》,今天LTX-Video迎来了它的首次重要更新——0.9.1版本。作为生成式AI视频模型的最新迭代,LTX-Video 0.9...视频模型# LTX-Video 0.9.112个月前03790
ltx-video-0.9-vae-finetune:基于 LTX Video 0.9 VAE 进行的微调VAE模型ltx-video-0.9-vae-finetune 是由开发者 spacepxl 基于 LTX Video 0.9 VAE 进行的微调VAE模型,旨在解决该模型中常见的棋盘伪影问题。通过专注于解码器...视频模型# ltx-video-0.9-vae-finetune# VAE模型12个月前03250
腾讯发布一种在 MM-DiT 架构下无需额外训练的多提示长视频生成方法DiTCtrl随着视频生成模型的发展,基于DiT架构如 Sora 和 MM-DiT 在单提示视频生成任务中取得了显著进展。然而,这些模型在处理多个顺序提示时面临诸多挑战,难以生成连贯且自然过渡的场景。具体来说: 严...视频模型# DiTCtrl12个月前03160
Adobe推出TransPixar:通过文本和图像生成透明背景的视频香港科技大学(广州)和 Adobe 研究的研究人员推出一种先进的文本到视频生成方法 TransPixar,特别专注于生成包含透明度通道(Alpha Channel)的RGBA视频,也就是能够通过文...视频模型# TransPixar12个月前02790
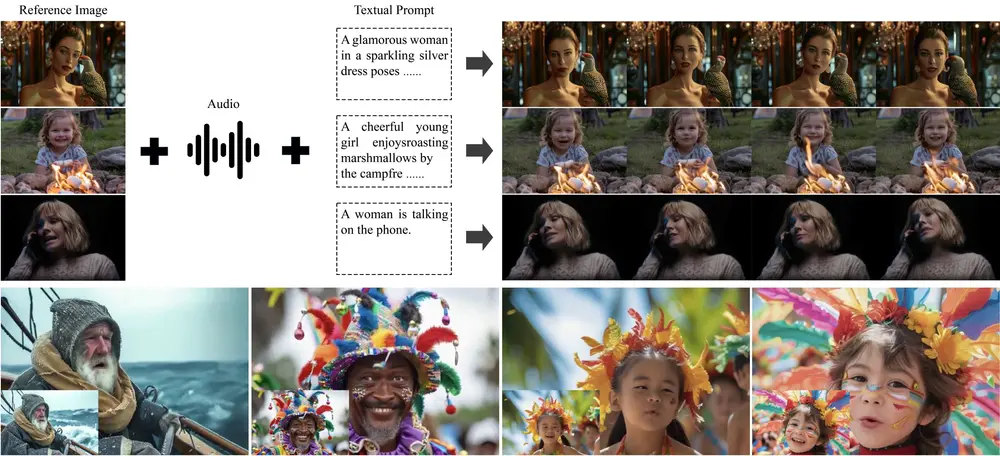
肖像图像动画Hallo系列再次更新!Hallo3框架引入Cogvidex模型,生成的肖像动画动作更自然、画面更逼真复旦大学、百度的研究人员对再次对Hallo 进行了更新,提出了 Hallo3框架,在通过预训练的基于变换器的视频生成模型(Cogvidex),解决现有肖像图像动画技术在处理非正面视角、渲染肖像周围动态...视频模型# Cogvidex模型# Hallo312个月前02880
时间延时视频生成模型MagicTime:学习现实世界中的物理知识,并能够生成展示这些知识的时间延时视频来自北京大学深圳研究生院、罗彻斯特大学、新加坡国立大学、广东工业大学和加州大学圣克鲁斯分校的研究人员推出新型时间延时视频生成模型MagicTime,这个模型的目标是学习现实世界中的物理知识,并能够生成...视频模型# MagicTime# 时间延时视频生成模型12个月前05570
字节跳动推出AnimateDiff-Lightning模型:根据文本描述生成视频,还可以视频转视频字节跳动推出了AnimateDiff-Lightning模型,能够更快地根据文本描述生成视频,比起原来的AnimateDiff模型,速度提升十倍以上。 模型地址:https://huggingface...视频模型# AnimateDiff-Lightning# 字节跳动12个月前06380
OpenAI视频模型Sora技术报告:构建虚拟世界的模拟器Sora我们专注于研究如何在大规模视频数据上训练生成模型。具体来说,我们针对不同时长、分辨率和宽高比的视频及图像,联合训练了基于文本条件的扩散模型。为了实现这一目标,我们运用了一种能够处理视频和图像潜在编码时...视频模型# OpenAI# Sora# 技术报告12个月前05720
Stable Video DiffusionStability AI于北京时间2023年11月22日推出AI视频生成模型 Stable Video Diffusion,Stable Video Diffusion 由两个模型组成的 ——SVD ...视频模型# AI视频生成# Stable Video Diffusion# SVD12个月前08830