Code2Video:基于代码智能体的教育视频生成框架尽管当前文生视频模型在短片段合成上取得进展,但在生成结构严谨、知识准确、视觉连贯的教育视频方面仍面临挑战。这类内容不仅要求语义正确,还需具备清晰的空间布局、逻辑动画过渡和教学节奏控制。 为此,新加坡国...视频模型# Code2Video# 教育视频生成4个月前02170
浙大 × 阿里巴巴推出 OmniAvatar:首个支持音频驱动全身动画的可控虚拟人视频生成模型在数字人、虚拟主播、AI 视频创作等领域,仅靠语音生成逼真且动作自然的虚拟形象视频,一直是生成式 AI 的关键挑战之一。 现有音频驱动视频生成方法大多聚焦于面部动画,尤其是唇部同步,而对身体动作、姿态...视频模型# OmniAvatar# 虚拟人6个月前02170
EchoMimicV3:用一个13亿参数模型,统一处理音频、文本、图像驱动的人体动画你是否想象过这样的场景? 输入一段语音,AI 自动生成人物说话的视频,唇形精准对齐,表情自然生动; 给一张静态肖像,加上一句“他开始微笑并挥手”,画面立刻动起来; 结合提示词和参考图,生成一段人物动作...视频模型# EchoMimicV3# 人体动画6个月前02120
Lynx:字节跳动提出的单图驱动个性化视频生成方案,实现高保真身份保留在内容创作、虚拟社交等场景中,“基于单张图像生成个性化视频”是重要需求——比如用一张自拍生成动态表情视频,或让历史人物照片“动起来”讲述故事。但这类任务长期面临核心挑战:如何在保证视频自然流畅的同时...视频模型# Lynx# 个性化视频生成# 字节跳动4个月前02060
阶跃星辰开源图生视频模型 Step-Video-TI2V:30B参数,运动幅度和镜头运动可控在2025年2月,阶跃星辰开源了两款Step系列多模态大模型——Step-Video-T2V视频生成模型和Step-Audio语音模型。现在,阶跃星辰进一步扩展其开源贡献,推出了基于30B参数Step...视频模型# Step-Video-TI2V# 图生视频模型# 阶跃星辰11个月前02040
交互式世界生成模型 Yume:通过输入图像、文本或视频来创建一个动态、逼真且可交互的世界由上海市人工智能实验室、复旦大学与上海创新研究院联合研发的新型生成模型 Yume 正式亮相。该模型旨在突破传统生成式 AI 的静态局限,构建一个可探索、可控制、高保真且动态演化的虚拟世界。 项目主页...视频模型# Yume# 交互式世界生成模型6个月前02000
StreamDiffusionV2:支持多显卡的实时视频生成系统由加州大学伯克利分校、麻省理工学院、斯坦福大学、德克萨斯大学奥斯汀分校与 First Intelligence 联合研发的 StreamDiffusionV2 正式开源。这是一个面向交互式直播场景的实...视频模型# StreamDiffusionV24个月前01980
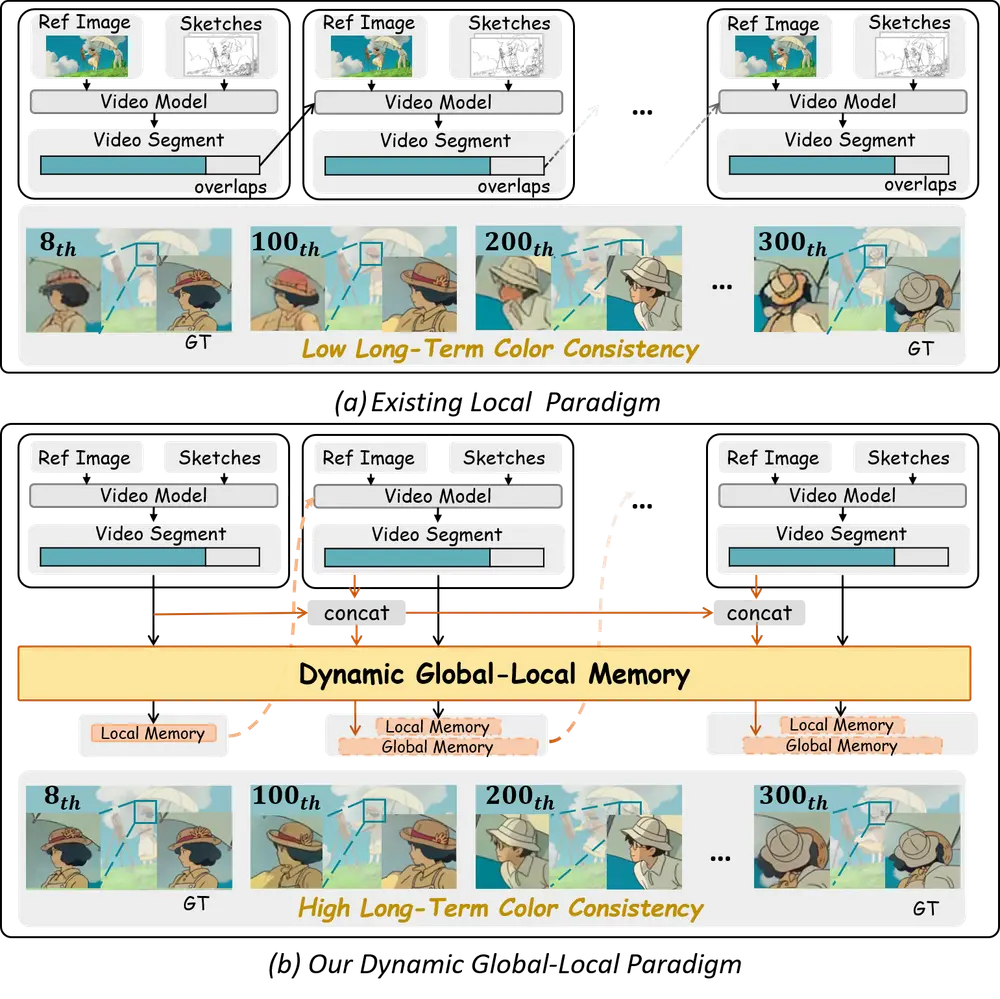
中科大 & 港科大联合推出 LongAnimation :实现长动画自动上色的新框架来自中国科学技术大学与香港科技大学的研究团队联合提出了一种名为 LongAnimation 的新型动画着色框架。该框架旨在实现长动画序列的自动化着色,并在整个动画过程中保持长期的颜色一致性。 项目主页...视频模型# LongAnimation# 动画自动上色7个月前01950
基于 Mochi 微调的开源视频模型Pusa:低成本、高性能的开源视频生成模型Pusa 是基于 Mochi 微调的开源视频模型,不仅开源了整个微调过程,还以极低的训练成本(仅 100 美元)实现了多种视频生成任务的无缝支持。 GitHub:https://github.com...视频模型# Pusa# 视频生成模型10个月前01940
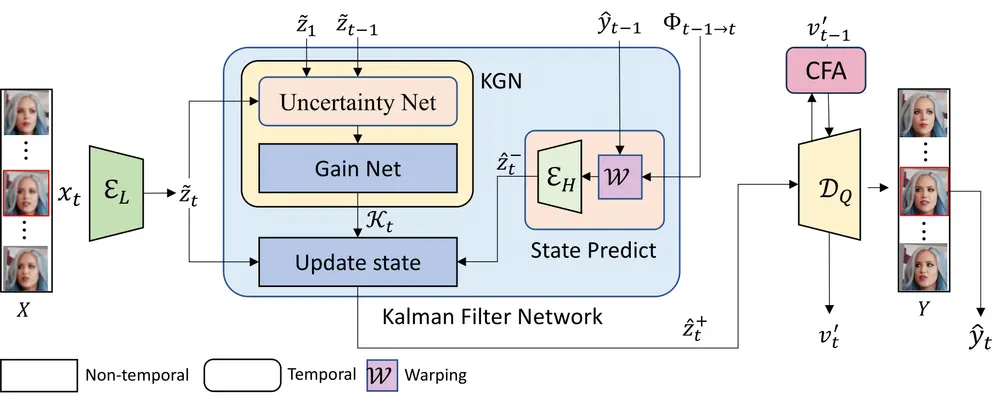
视频人脸超分辨率的新型框架KEEP:解决视频中人脸图像的超分辨率问题,同时保持时间一致性视频人脸超分辨率(VFSR)的目标是从低分辨率(LR)或严重退化的视频中重建出高分辨率(HR)的人脸图像。尽管人脸图像超分辨率(FSR)领域已经取得了显著进展,但视频人脸超分辨率仍然是一个相对较少被研...视频模型# KEEP# 视频人脸超分辨率9个月前01860
Pusa Wan2.2 V1.0:将开创性的 Pusa 范式扩展到先进的 Wan2.2-T2V-A14B 架构Pusa Wan2.2 V1.0 将开创性的 Pusa 范式扩展到先进的 Wan2.2-T2V-A14B 架构,该架构采用 MoE DiT 设计,包含独立的噪声和高噪声模型。这种架构提供了增强的质量控...视频模型# Pusa Wan2.2 V1.0# Wan2.2-T2V-A14B5个月前01840
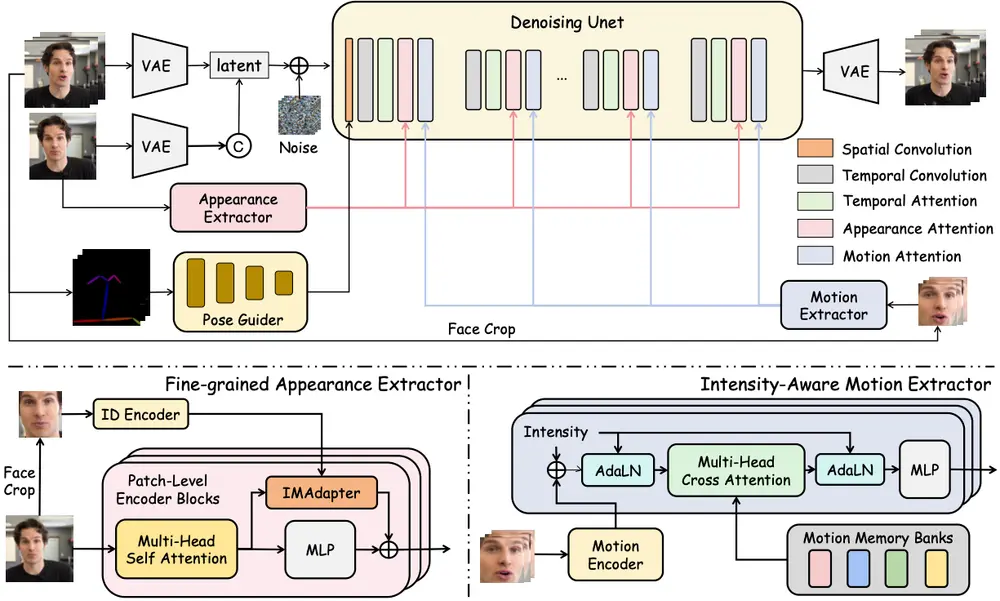
腾讯混元项目组推出数字人头像生成模型 HunyuanPortrait :用于高度可控且逼真的肖像动画生成腾讯混元项目组推出基于扩散模型的条件控制方法 HunyuanPortrait ,用于高度可控且逼真的肖像动画生成。该方法通过隐式表示来控制肖像动画,能够利用单张肖像图像作为外观参考和视频片段作为驱动模...视频模型# HunyuanPortrait# 腾讯混元8个月前01840