Zyphra开源支持高保真语音克隆的实时文本转语音(TTS)模型 Zonos-v0.1 测试版Zyphra 最近发布了 Zonos-v0.1 测试版,这是一款支持高保真语音克隆的实时文本转语音(TTS)模型。作为开源项目的一部分,Zonos-v0.1 包含两个强大的 TTS 模型:一个 16 ...语音模型# TTS模型# Zonos-v0.112个月前02420
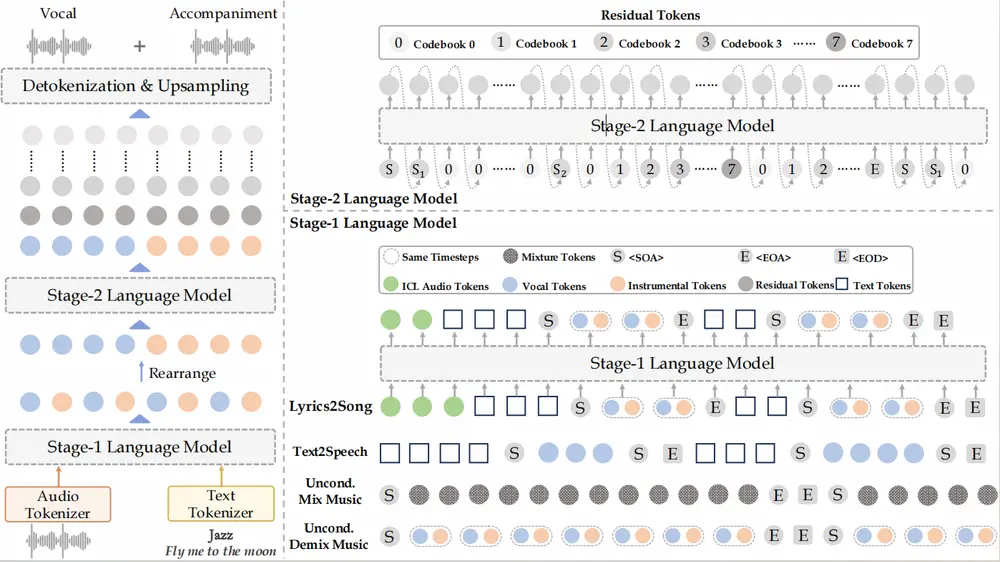
香港科技大学推出歌词生成音乐模型YuE香港科技大学的研究团队近期在探索从给定歌词生成完整歌曲音频的领域取得了重要进展,这一过程被称为“歌词到歌曲”(lyrics2song)。尽管基于文本条件的音乐生成模型在创作非人声音乐短片段方面已经展现...语音模型# AI音乐# YuE12个月前02670
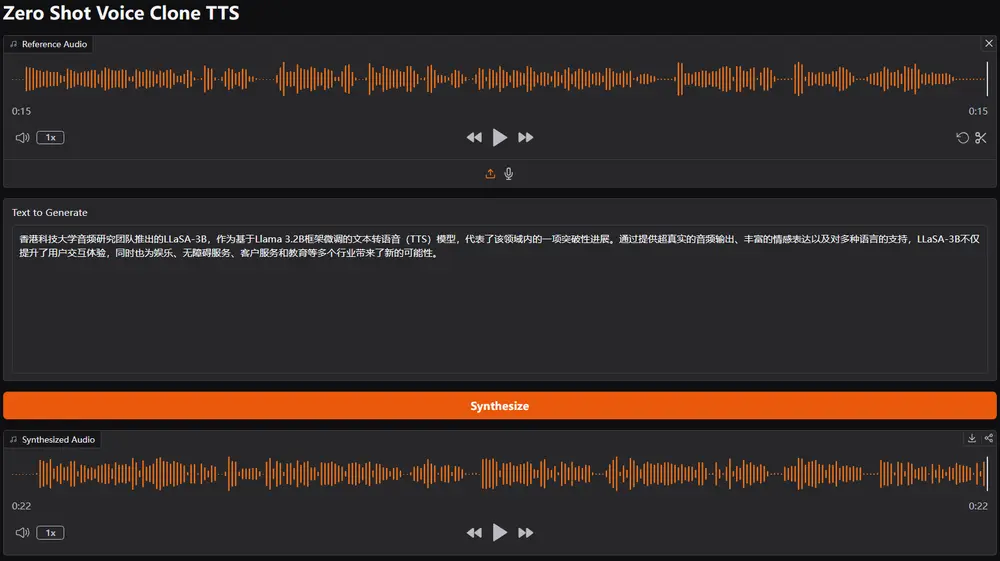
Llasa:基于LLaMA语言模型的先进文本转语音(TTS)系统文本转语音(TTS)技术正成为人机交互领域的重要工具。随着娱乐、无障碍服务、客户服务和教育等行业对语音合成的需求不断增加,市场对逼真、情感丰富且支持多种语言的语音合成技术的需求也在迅速增长。然而,传统...语音模型# Llasa# TTS12个月前06420
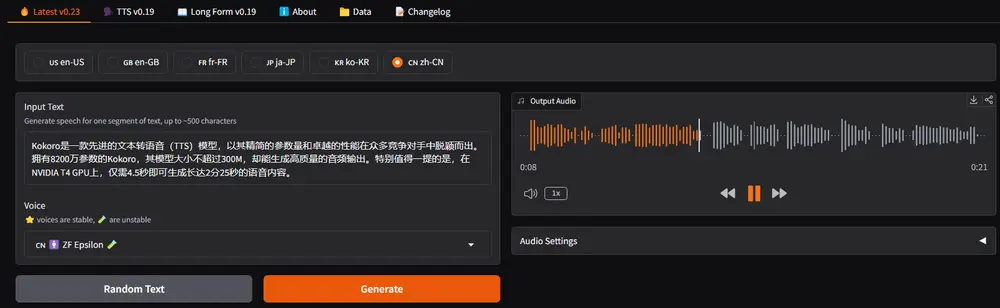
文本转语音模型Kokoro-82M:8200万参数,支持多语言和多声音选项Kokoro是一款先进的文本转语音(TTS)模型,以其精简的参数量和卓越的性能在众多竞争对手中脱颖而出。拥有8200万参数的Kokoro,其模型大小不超过300M,却能生成高质量的音频输出。特别值得一...语音模型# Kokoro-82M# TTS12个月前03,5080
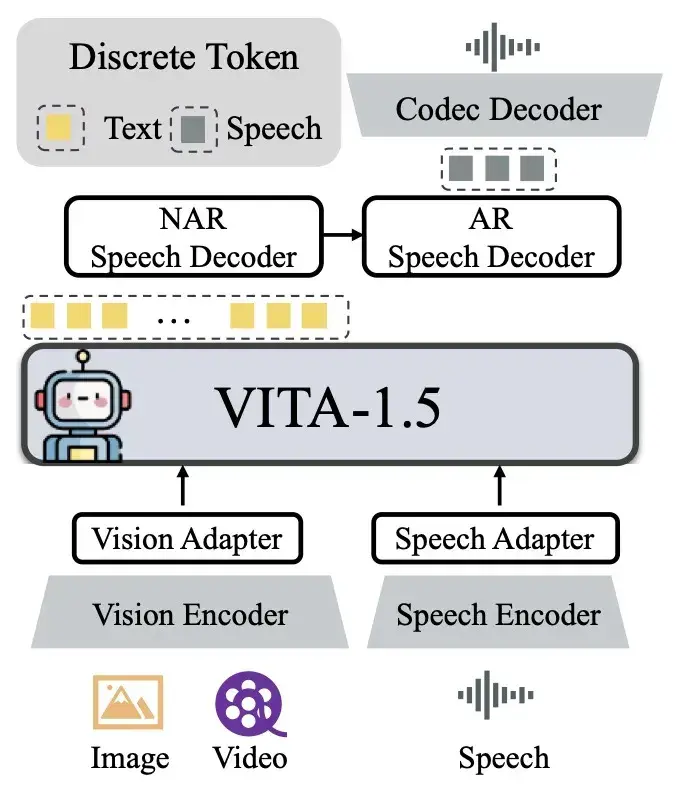
开源多模态视频语音大模型VITA-1.5: 基于Qwen2.5模型,实现接近实时的视觉和语音交互能力随着多模态大语言模型(MLLMs)的发展,如何有效地整合视觉、语言和语音成为了人工智能领域面临的一个重要挑战。VITA-1.5 是由南京大学(NJU)、腾讯优图实验室(Tencent Youtu La...语音模型# Qwen2.5模型# VITA-1.512个月前03360
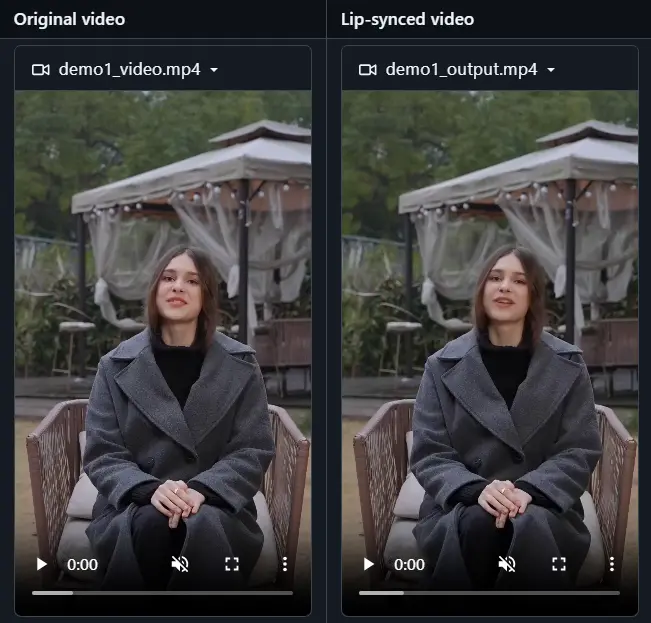
端到端唇音同步框架LatentSync:可以分析新的音频信号,并生成与音频同步的口型字节跳动与北京交通大学的研究团队共同提出了一种名为LatentSync的新方法,旨在解决唇音同步的问题。这一框架利用了Stable Diffusion的强大能力,通过一个端到端的流程直接建模复杂的音视...语音模型# LatentSync# 唇音同步12个月前03880
文本到音频生成模型TANGOFLUX:从文本描述中快速、忠实地生成高质量的音频内容随着人工智能技术的发展,文本到音频(TTA)生成模型正在逐渐改变我们与数字内容互动的方式。然而,创建高质量且自然的音频输出仍然是一个复杂的技术挑战,尤其是在对齐模型以产生符合人类期望的音频方面。新加坡...语音模型# TANGOFLUX# 文本到音频生成模型6个月前03480
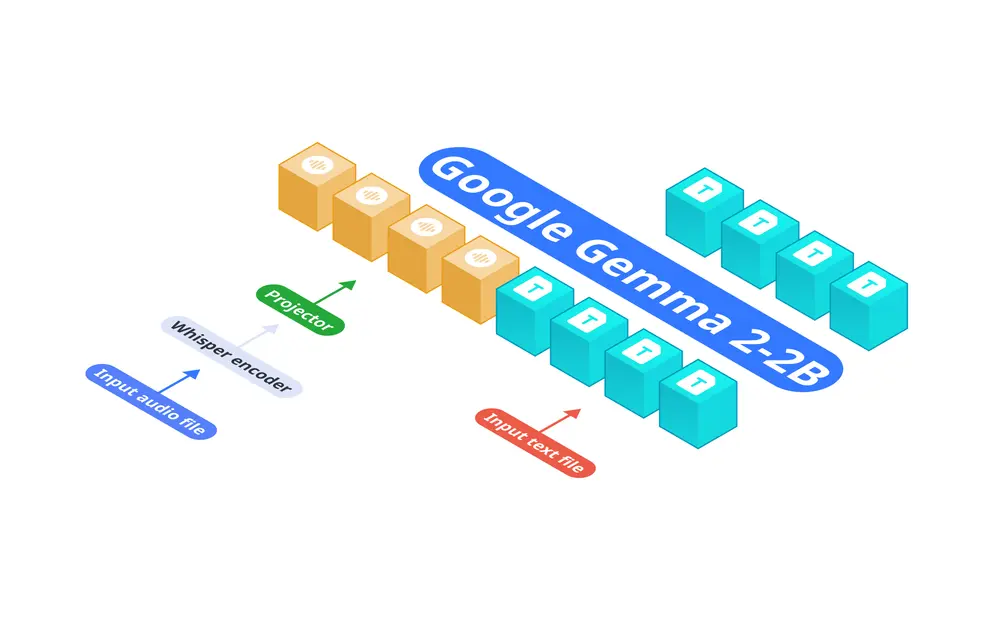
Nexa AI 推出一款专为边缘部署设计的音频语言模型 OmniAudio-2.6B音频语言模型(ALMs)在各种应用中发挥着关键作用,包括实时转录、翻译、语音控制系统和辅助技术。然而,许多现有解决方案面临高延迟、大量计算需求以及依赖云端处理等限制。这些问题对边缘部署提出了挑战,因为...语音模型# OmniAudio-2.6B12个月前02780
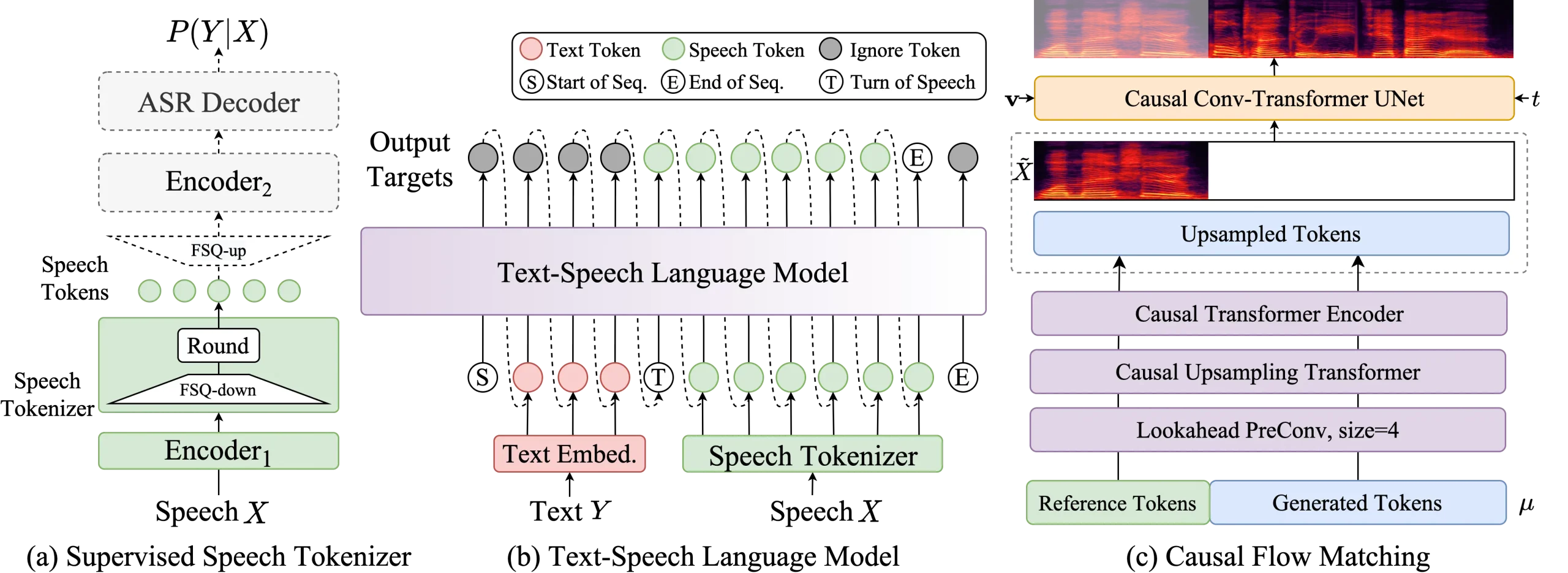
通义语音团队推出语音生成模型CosyVoice 2:提升了多语言语音合成的质量、响应速度和实时性能阿里巴巴旗下通义实验室语音团队在之前提出的 CosyVoice 基础上,推出了全新的 CosyVoice 2。该模型通过一系列优化和创新,显著提升了多语言语音合成的质量、响应速度和实时性能。CosyV...语音模型# CosyVoice 2# 语音生成模型12个月前02860
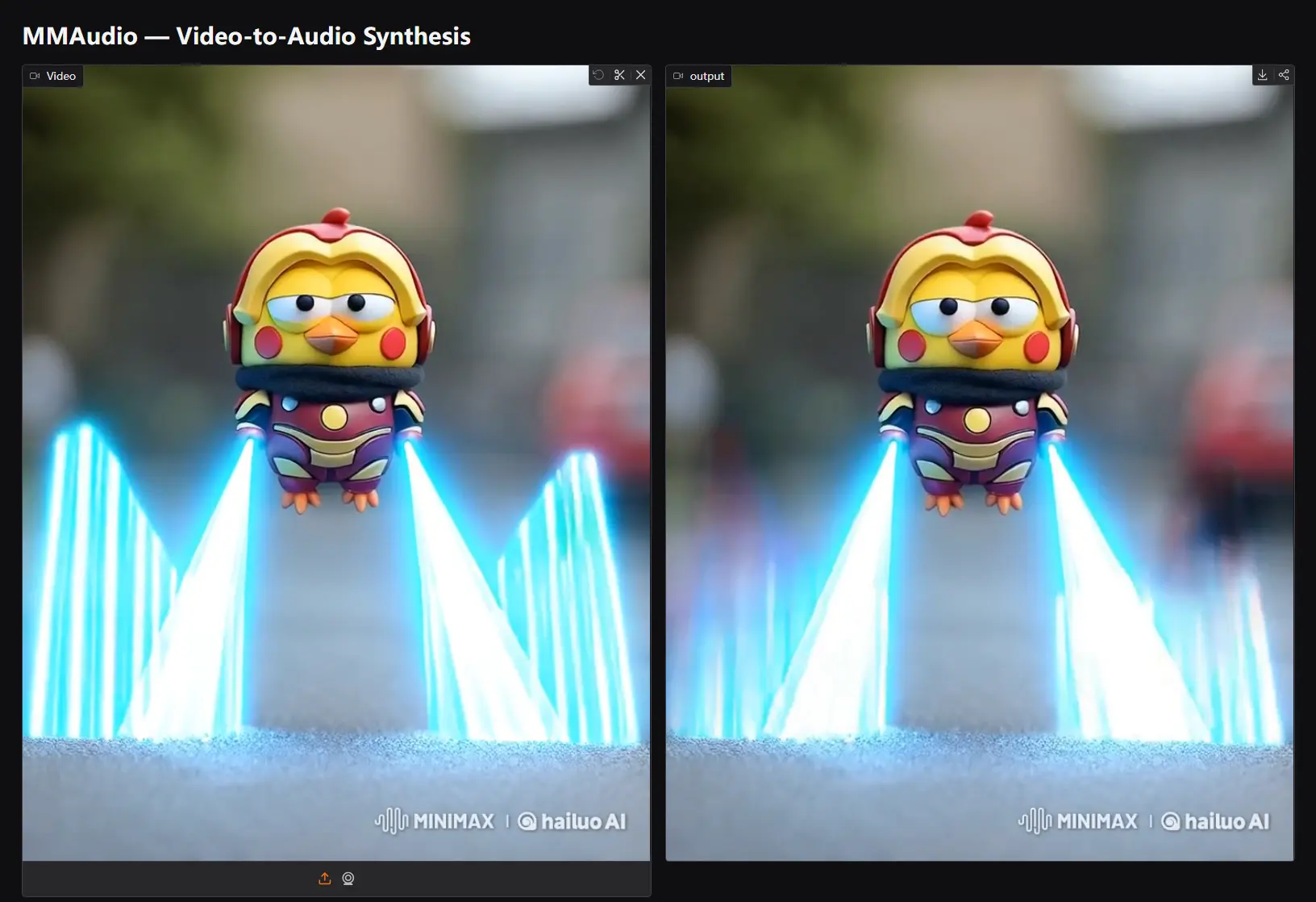
MMAudio:基于多模态联合训练的同步音频生成系统近年来,多模态生成模型在图像、视频和文本等领域取得了显著进展,但将视觉和文本信息与音频生成结合的任务仍然具有挑战性。传统的音频生成方法通常依赖于单一模态(如仅基于文本或仅基于视频),难以实现高质量的音...语音模型# MMAudio# 音频生成12个月前03020
阿里巴巴语音实验室发布开源语音处理框架 ClearerVoice-Studio:支持语音增强、分离和目标说话人提取在当今的音频环境中,清晰沟通面临诸多挑战。背景噪音、重叠对话以及音频和视频信号的混合等因素常常破坏了沟通的清晰度和理解力。这些问题不仅影响个人通话,还波及专业会议和内容制作等场景。尽管音频技术有所进步...语音模型# ClearerVoice-Studio# 阿里巴巴12个月前03200
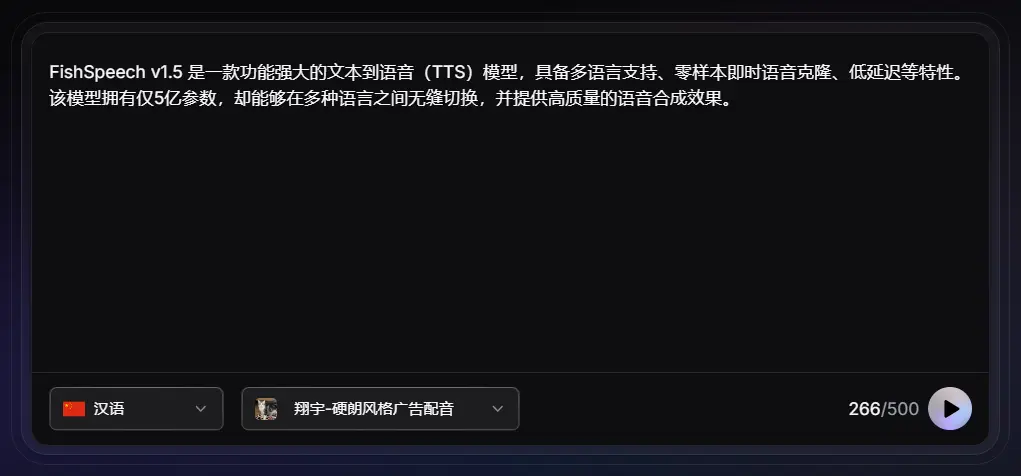
TTS模型FishSpeech推出v1.5 版本:具备多语言支持、零样本即时语音克隆、低延迟等特性FishSpeech v1.5 是一款功能强大的文本到语音(TTS)模型,具备多语言支持、零样本即时语音克隆、低延迟等特性。该模型拥有仅5亿参数,却能够在多种语言之间无缝切换,并提供高质量的语音合成效...语音模型# FishSpeech v1.5# TTS模型12个月前04790