字节跳动与浙大联合发布轻量高效TTS模型MegaTTS3字节跳动和浙江大学的研究人员推出的一款轻量级TTS模型:MegaTTS3,0.45B,高质量语音克隆,支持中英文以及中英文混合,支持口音强度控制,后面会支持更细粒度的发音和时长调整。 GitHub:h...语音模型# MegaTTS3# TTS模型# 字节跳动10个月前04670
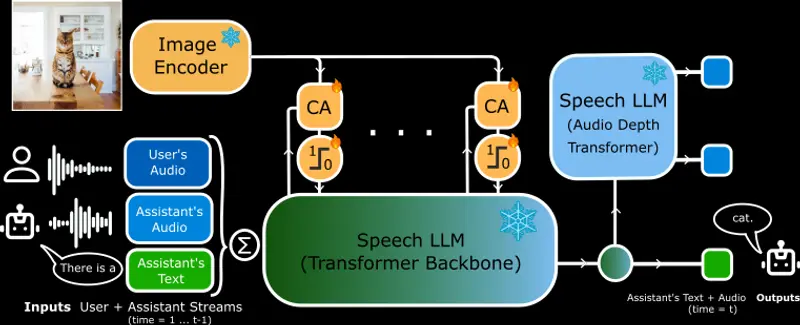
Kyutai发布首个开源实时语音模型MoshiVis,开启视觉与语音交互新时代在AI领域,将实时语音交互与视觉内容相结合一直是一个极具挑战性的课题。传统系统通常依赖于多个独立组件来实现语音活动检测、语音识别、文本对话和文本转语音合成,这种分段式的方法不仅容易引入延迟,还难以捕捉...语音模型# MoshiVis# 语音模型10个月前02030
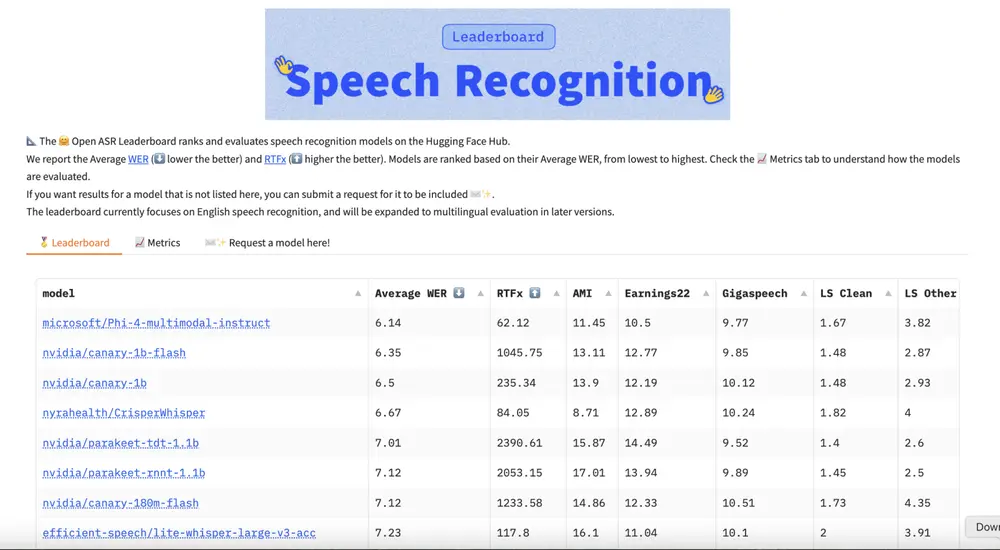
英伟达开源多语言语音识别和翻译模型:Canary 1B Flash 和 Canary 180M Flash在促进全球交流的进程中,多语言语音识别和翻译技术扮演着至关重要的角色。然而,开发能够实时准确地转录和翻译多种语言的模型面临着诸如处理语言细微差别、确保高准确性与低延迟以及实现跨设备高效部署等挑战。为应...语音模型# Canary 180M Flash# Canary 1B Flash# 多语言语音识别11个月前04570
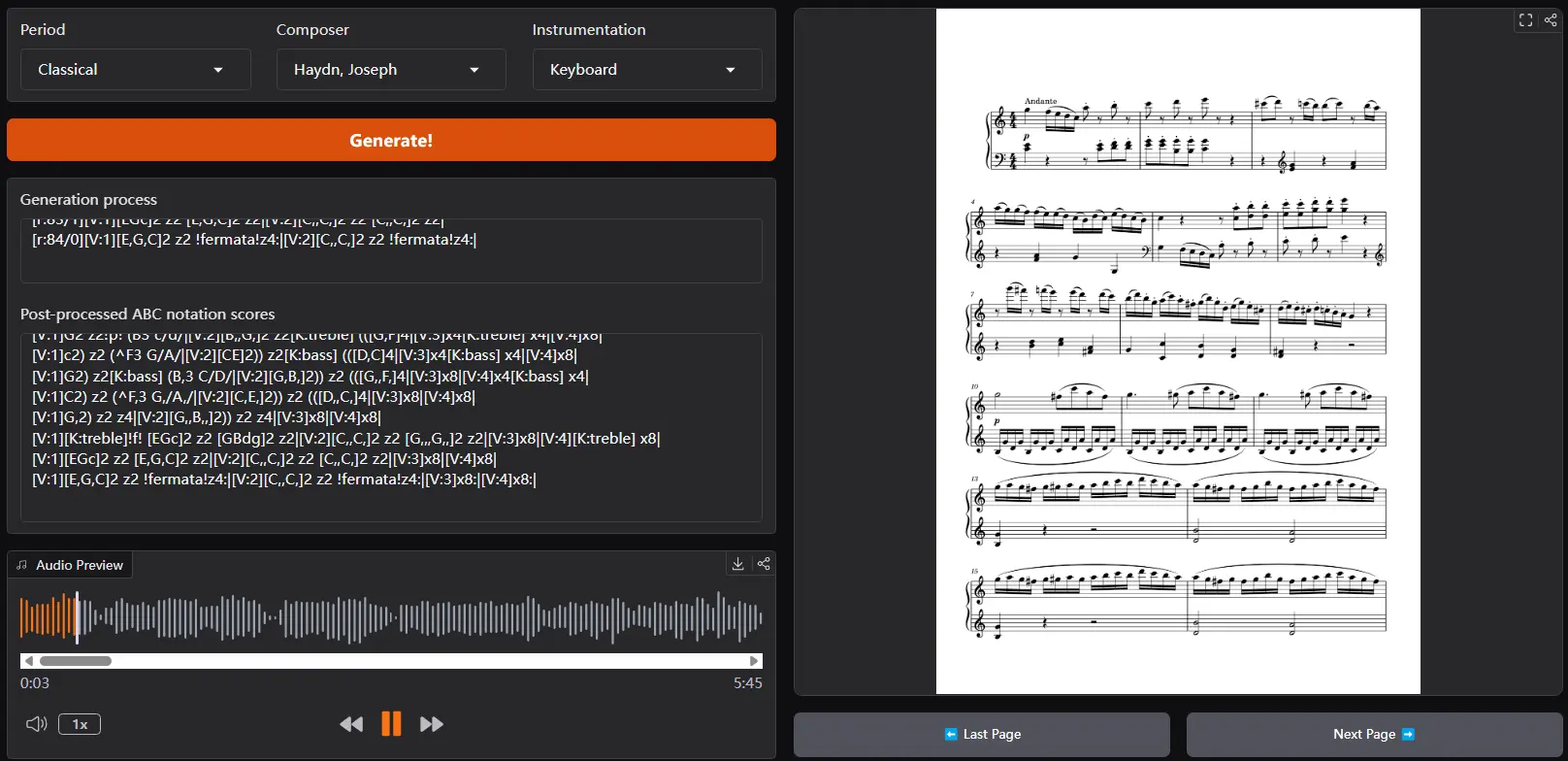
符号音乐生成模型NotaGen:通过借鉴大语言模型(LLM)的训练范式来生成高质量的古典乐谱中央音乐学院、美国罗切斯特大学、北京飞天云动科技、北京航空航天大学和清华大学的研究人员推出符号音乐生成模型NotaGen,通过借鉴大语言模型(LLM)的训练范式来生成高质量的古典乐谱。其在超过 160...语音模型# NotaGen# 古典音乐生成模型11个月前04820
Orpheus TTS:基于 Llama-3b 构建的先进文本转语音(TTS)模型Canopy Labs推出基于 Llama-3b 骨干网络构建的开源文本转语音(TTS)模型Orpheus TTS ,这款模型展示了利用大语言模型(LLM)进行高质量语音合成的能力。 模型规模与特性 ...语音模型# Llama-3b# Orpheus TTS# TTS11个月前02410
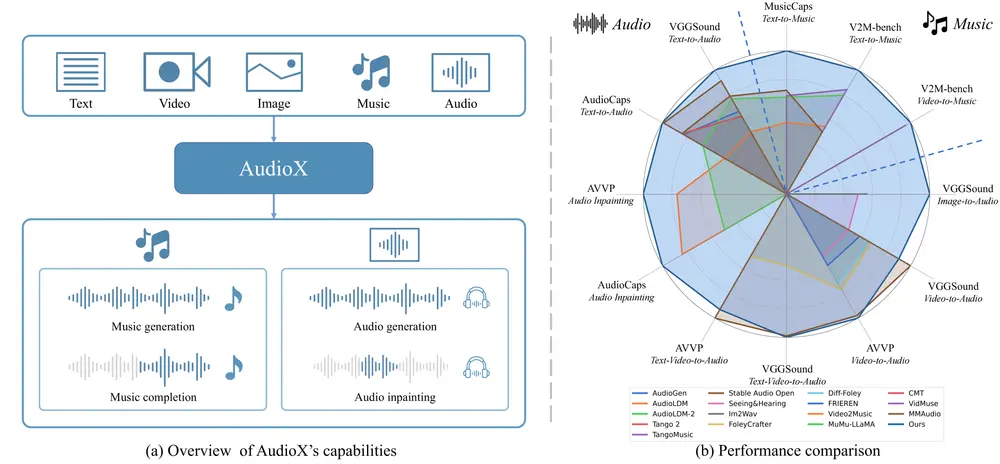
香港科技大学推出统一DiT架构模型AudioX:通过多模态输入(如文本、视频、图像、音乐和音频)生成高质量的音频和音乐香港科技大学的研究人员推出统一DiT架构模型AudioX,通过多模态输入(如文本、视频、图像、音乐和音频)生成高质量的音频和音乐。AudioX通过创新的多模态掩码训练策略,强制模型从掩码输入中学习,从...语音模型# AI音乐# AudioX# DiT模型11个月前04200
小米推出音频推理模型R1-AQA:强化学习助力机器“听懂”声音背后的逻辑在大模型时代,人们对机器的期望已经不再局限于简单的语音识别或声音分类,而是希望机器能够具备复杂的推理能力。例如,通过汽车座舱的录音判断车辆是否存在潜在故障,从交响乐中推测作曲家的情绪,或者在地铁站的嘈...语音模型# R1-AQA# 小米# 音频推理模型11个月前05030
Sesame 团队推出新一代语音技术 CSM:让语音助手更像真人Sesame 团队近期发布了一项名为 Conversational Speech Model (CSM) 的全新语音技术,旨在解决当前语音助手普遍存在的“死板”问题。这项技术的目标是让语音助手不仅能够...语音模型# CSM# 语音技术11个月前03390
SparkAudio推出Spark-TTS:基于大语言模型的高效文本到语音系统香港科技大学、SparkAudio开源社区、上海出门问问信息技术有限公司、上海交通大学、南洋理工大学、西北工业大学和网易伏羲人工智能实验室的研究人员推出Spark-TTS,这是一个基于大语言模型(LL...语音模型# Spark-TTS# SparkAudio# 文本到语音11个月前02980
Hume AI推出了首个理解其所说内容的文本转语音系统OctaveHume 推出了 Octave(全能文本和语音引擎),这是首个专为文本转语音设计的大语言模型(LLM)。与传统文本转语音(TTS)系统不同,Octave 不仅能够“朗读”文字,还能真正理解单词在上下文...语音模型# Hume AI# Octave# TTS11个月前02670
ElevenLabs 推出语音转文本模型 Scribe,多语言支持与高精度ElevenLabs 是一家专注于人工智能音频生成的初创公司,最近筹集了 1.8 亿美元的资金,估值达到 33 亿美元。以其高质量的声音合成技术而闻名,该公司现在正通过推出其首个独立的语音转文本模型 ...语音模型# ElevenLabs# Scribe# 语音识别11个月前02940
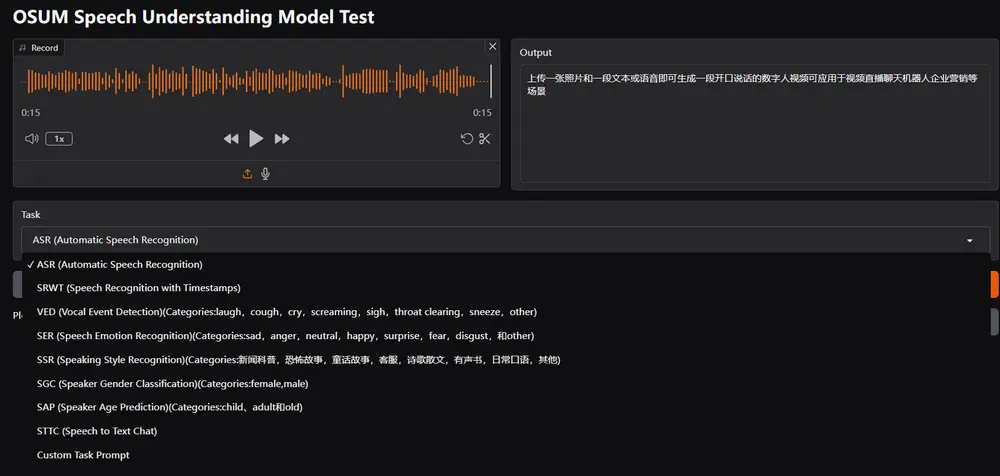
西北工业大学开源语音理解模型OSUM近年来,大语言模型(LLMs)在自然语言处理领域取得了显著进展,这启发了业界对语音理解语言模型(Speech Understanding Language Models, SULMs)的开发。SULM...语音模型# OSUM# 西北工业大学# 语音理解模型11个月前04100