字节跳动推出统一的视频生成框架Phantom :通过跨模态对齐实现主体一致性的视频生成字节跳动的研究人员推出一个统一的视频生成框架Phantom ,通过跨模态对齐实现主体一致性的视频生成(Subject-to-Video, S2V),用于单主体和多主体参考,构建在现有的文本到视频和图像...新技术# Phantom# 字节跳动# 视频生成11个月前02960
字节跳动推出新型图像编辑方法 SuperEdit :通过改进监督信号来提升基于指令的图像编辑性能字节跳动和佛罗里达中央大学计算机视觉研究中心的研究人员推出新型图像编辑方法 SuperEdit ,通过改进监督信号来提升基于指令的图像编辑性能。 项目主页:https://liming-ai.gith...图像模型# SuperEdit# 图像编辑# 字节跳动11个月前02920
字节跳动 Seed 团队发布 Seed-OSS 系列开源模型:36B 参数,512K 长上下文,可灵活调整思考长度字节跳动Seed团队正式推出Seed-OSS系列开放权重模型,该系列均为36B参数规模,聚焦长上下文处理、推理能力与代理任务优化,以Apache-2.0许可证开源,为开发者与研究社区提供高实用性工具...大语言模型# Seed-OSS# 字节跳动7个月前02840
字节跳动推出基于DiT模型的人类图像动画框架DreamActor-M1:实现整体性、表现力和鲁棒性的人类图像动画生成字节跳动推出一个基于DiT模型的人类图像动画框架DreamActor-M1,实现整体性(holistic)、表现力(expressive)和鲁棒性(robust)的人类图像动画生成。该框架通过混合引导...新技术# DiT模型# DreamActor-M1# 字节跳动1年前02840
字节跳动推出视频生成模型Seaweed-7B:以较低的计算成本实现高效的训练和生成近年来,随着视频生成技术的快速发展,如何在资源有限的情况下实现高性能的模型训练成为研究热点。字节跳动提出了一种创新的训练策略,推出了一个中等规模的视频生成模型——Seaweed-7B。这个模型拥有约7...视频模型# Seaweed-7B# 字节跳动# 视频生成模型12个月前02820
Lynx:字节跳动提出的单图驱动个性化视频生成方案,实现高保真身份保留在内容创作、虚拟社交等场景中,“基于单张图像生成个性化视频”是重要需求——比如用一张自拍生成动态表情视频,或让历史人物照片“动起来”讲述故事。但这类任务长期面临核心挑战:如何在保证视频自然流畅的同时...视频模型# Lynx# 个性化视频生成# 字节跳动6个月前02740
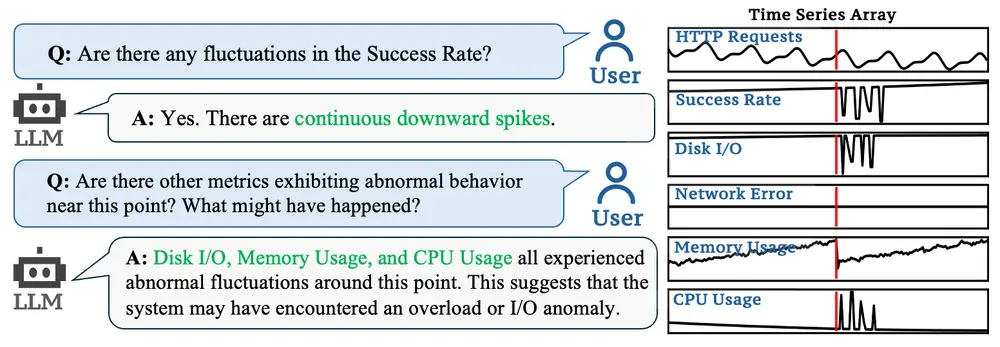
字节跳动推出多模态大语言模型ChatTS:专门用于时间序列分析清华大学和字节跳动的研究人员推出多模态大语言模型ChatTS ,专门用于时间序列分析。它通过自然语言命令帮助用户快速理解时间序列数据,执行日常任务,并处理复杂的推理问题。ChatTS 的核心优势在于其...多模态模型# ChatTS# 多模态大语言模型# 字节跳动12个月前02730
字节跳动推出新型图像分词器TA-TiTok及掩码生成模型MaskGen字节跳动和浦项科技大学的研究人员提出了一种名为TA-TiTok的新型图像分词器。这是一种基于Transformer架构的文本感知一维分词器,能够高效处理离散或连续的一维标记。基于TA-TiTok的成功...新技术# MaskGen# TA-TiTok# 字节跳动1年前02710
字节跳动发布Seaweed APT2:专为实时交互式场景设计的流式视频生成模型字节跳动研究团队推出了Seaweed APT2,一款专为实时交互式场景设计的流式视频生成模型。该模型能够在单块H100 GPU上实现每秒24帧、分辨率高达736x416(等效640x480)的不间断视...视频模型# Seaweed APT2# 字节跳动10个月前02700
开源版GPT‑4o?新型多模态生成模型 Liquid,用一个模型搞定视觉与语言任务在OpenAI旗下GPT‑4o凭借原生生成及编辑图像功能,火爆网络后,大家都在期待有相对应的开源模型推出。而将视觉和语言任务高效整合一直是研究的热点。华中科技大学、字节跳动和香港大学的研究人员推出了新...图像模型# GPT‑4o# OpenAI# 多模态生成模型12个月前02700
字节跳动推出视频生成模型训练新方法APT:通过在扩散预训练的基础上对真实数据进行对抗训练,以实现一步视频生成扩散模型在图像和视频生成领域展示了卓越的能力,但其迭代性质导致了生成过程缓慢且计算成本高昂。尽管现有的蒸馏方法尝试通过一步生成来解决这一问题,但往往伴随着显著的生成质量下降。为了解决这些挑战,字节跳动...新技术# APT# Seaweed-APT模型# 字节跳动1年前02690
字节跳动推出新型单目深度估计方法Video Depth Anything:专门用于超长视频(数分钟)的高质量、一致的深度估计字节跳动推出新型单目深度估计方法Video Depth Anything,专门用于超长视频(数分钟)的高质量、一致的深度估计。该方法基于 Depth Anything V2,通过引入高效的空间-时间头...新技术# Video Depth Anything# 字节跳动1年前02660