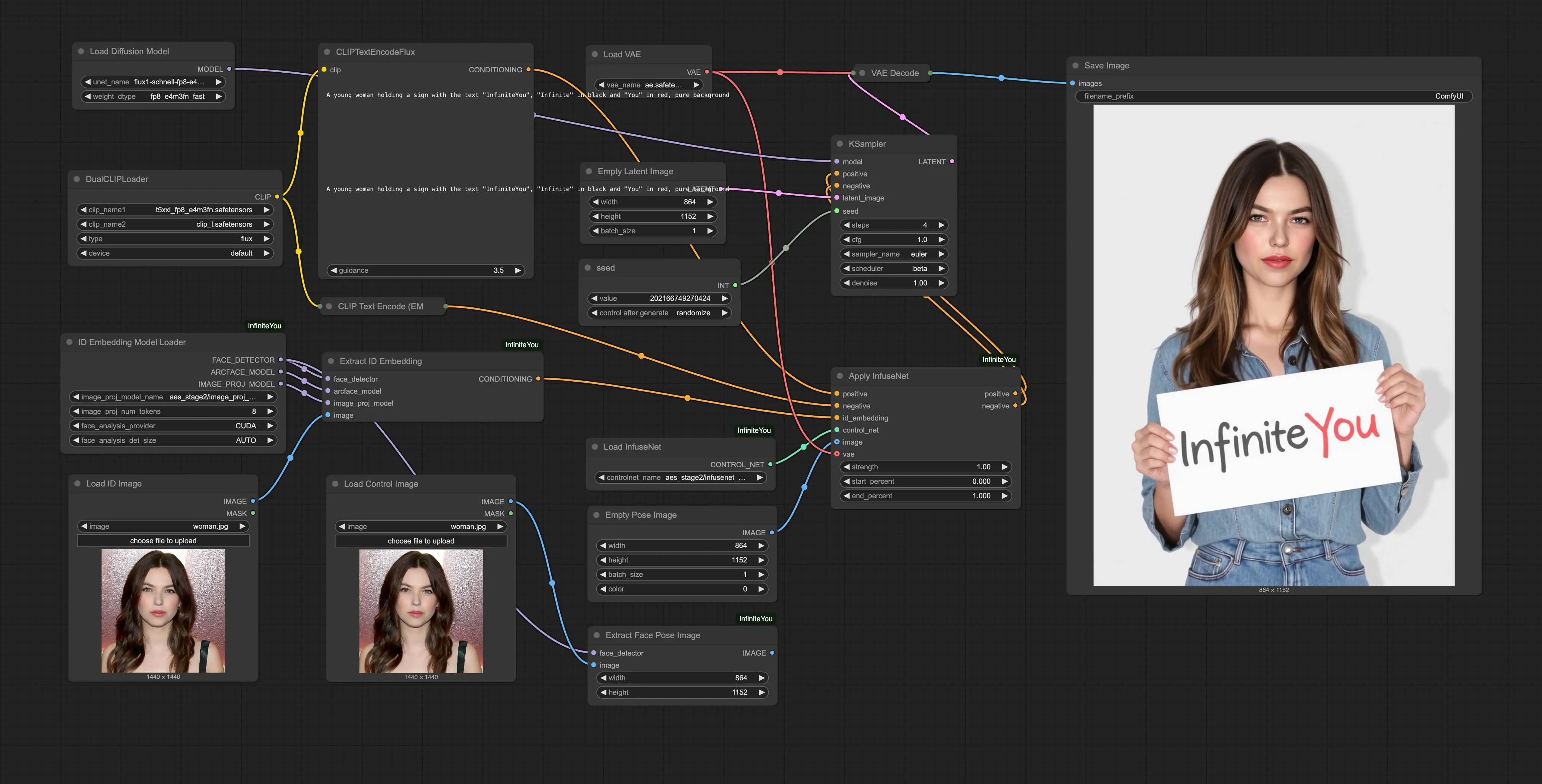
字节跳动发布 InfiniteYou官方 ComfyUI 插件ComfyUI_InfiniteYou字节跳动发布了其基于FLUX的身份保持模型InfiniteYou 的官方 ComfyUI 原生节点 —— ComfyUI_InfiniteYou,为开发者和创作者提供了更便捷的集成方式,支持在 Com...插件# ComfyUI_InfiniteYou# InfiniteYou# 字节跳动9个月前04460
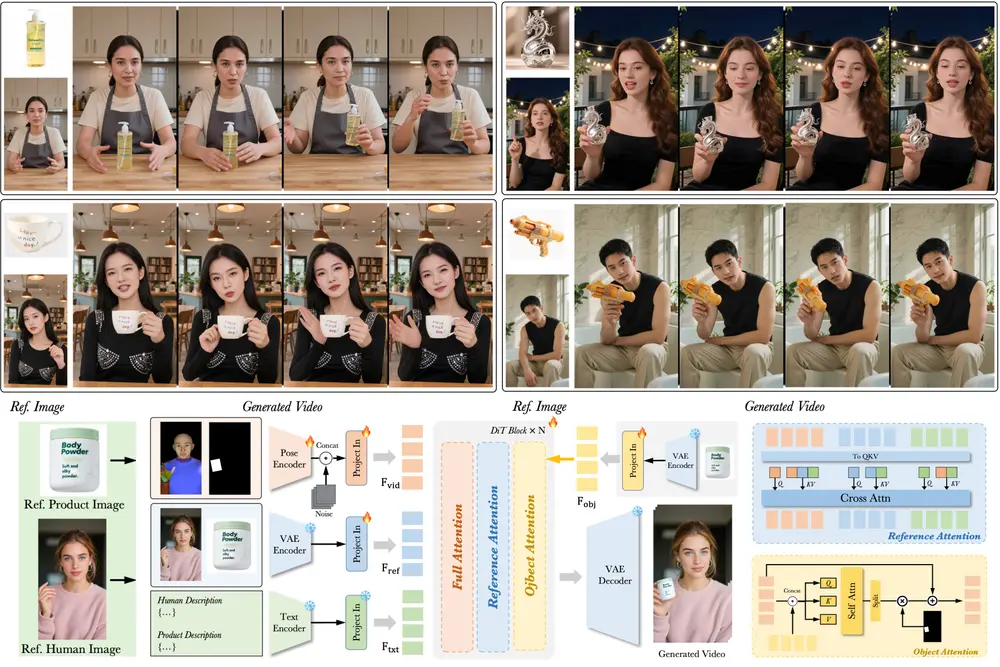
DreamActor-H1:字节跳动推出高保真人类-产品演示视频生成框架在电商广告、虚拟试穿、交互式媒体等场景中,如何高效生成高质量的人类-产品演示视频,一直是视觉生成领域的重要挑战。 近日,字节跳动 AI 实验室提出了一种全新的视频生成框架——DreamActor-H1...新技术# DreamActor-H1# 字节跳动9个月前03110
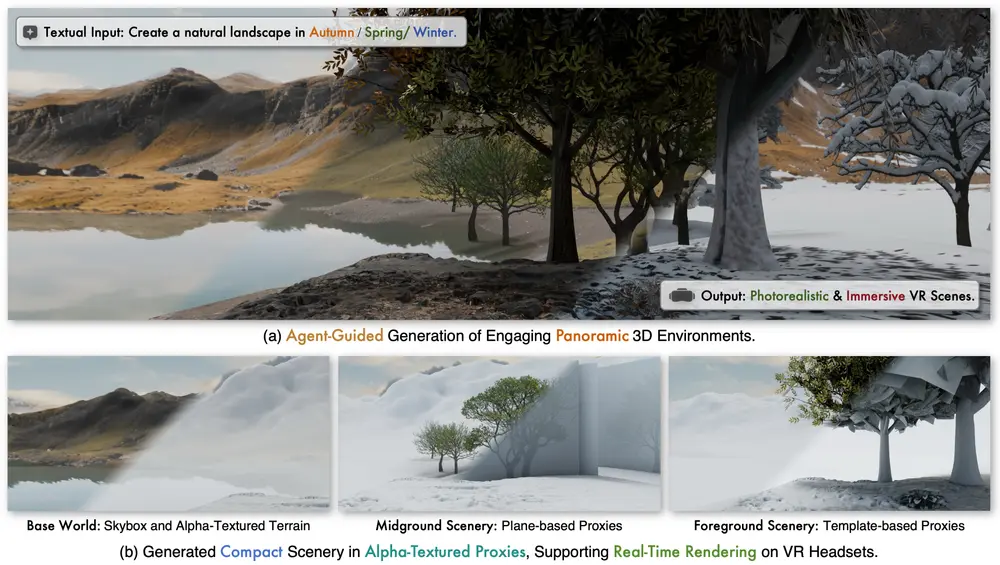
字节跳动推出新型框架ImmerseGen:用于从文本提示自动生成沉浸式 3D 场景字节跳动和浙江大学的研究人员推出新型框架ImmerseGen ,用于从文本提示自动生成沉浸式 3D 场景。ImmerseGen 通过使用轻量级的几何代理(如简化地形和带有 alpha 通道的纹理平面...3D模型# ImmerseGen# 字节跳动9个月前02100
字节跳动提出MAGREF:支持多参考图像和文本提示的高质量视频生成框架近年来,随着扩散模型等深度生成技术的发展,视频生成能力取得了显著进步。然而,在涉及多个参考主体的场景中,如何保证各主体之间的视觉一致性、身份一致性和生成稳定性,依然是一个重大挑战。 为了解决这一问题...视频模型# MAGREF# 字节跳动# 视频生成框架10个月前02530
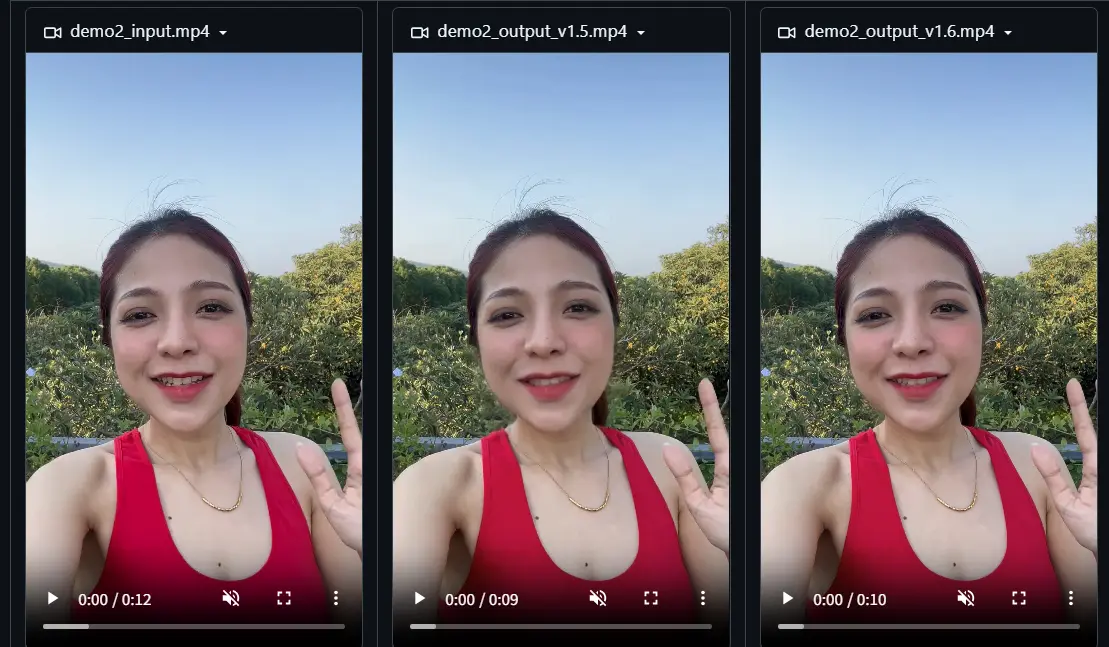
字节跳动发布 LatentSync 1.6:聚焦高分辨率视频生成,解决模糊问题字节跳动发布了其对口型视频生成模型 LatentSync 的新版本 1.6,重点解决了此前版本中生成牙齿和嘴唇区域模糊的问题。 模型:https://huggingface.co/ByteDance...视频模型# LatentSync 1.6# 字节跳动10个月前03260
字节跳动发布Seaweed APT2:专为实时交互式场景设计的流式视频生成模型字节跳动研究团队推出了Seaweed APT2,一款专为实时交互式场景设计的流式视频生成模型。该模型能够在单块H100 GPU上实现每秒24帧、分辨率高达736x416(等效640x480)的不间断视...视频模型# Seaweed APT2# 字节跳动10个月前02700
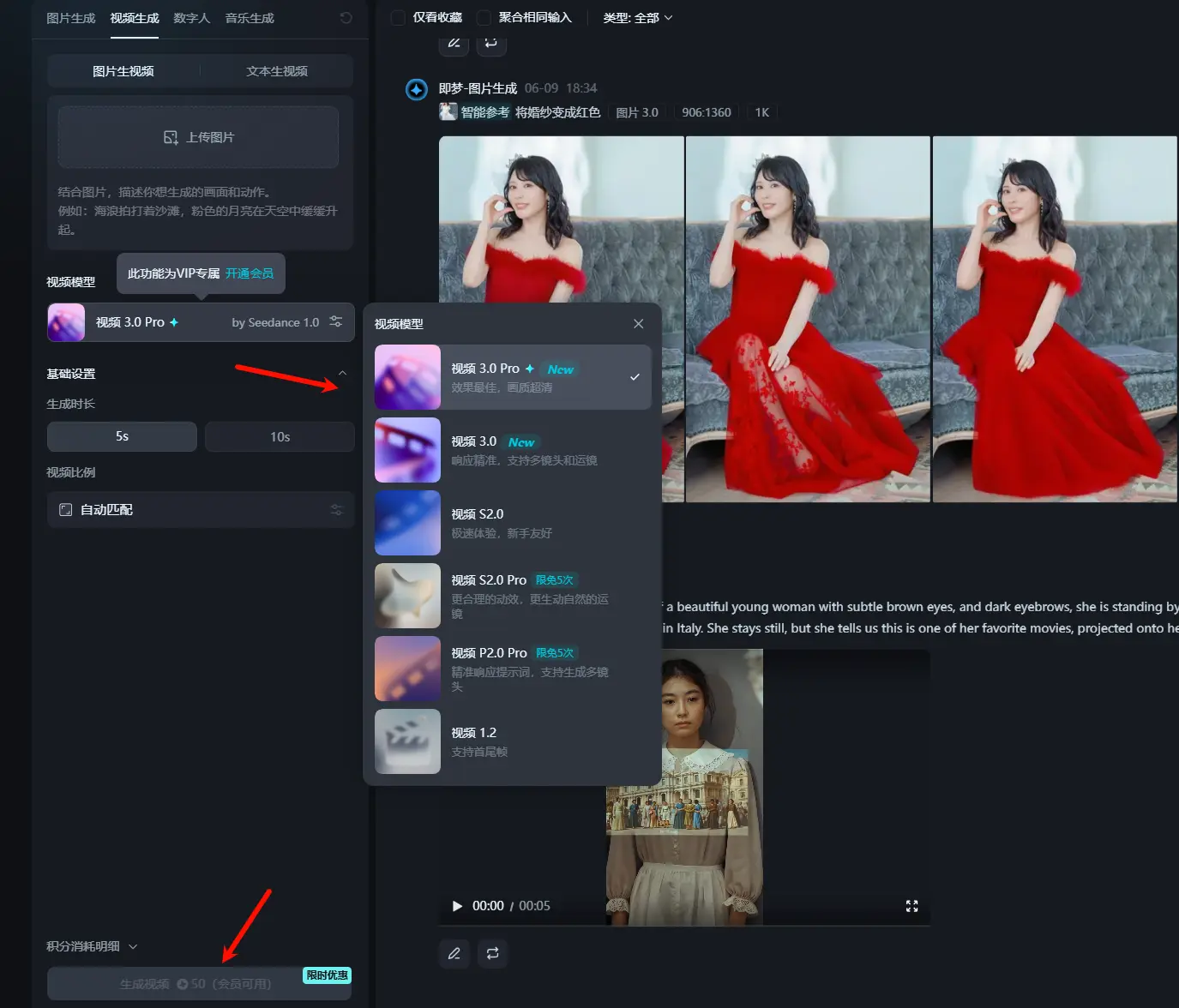
字节跳动推出视频生成模型 Seedance 1.0,视频生成迈入“电影级”体验字节跳动正式发布了其最新的视频生成模型 Seedance 1.0。该模型已集成在字节旗下 AI 创作平台“即梦”中,并以“视频生成3.0 Pro”版本面向用户开放(需会员权限使用)。目前,每生成一个5...视频模型# Seedance 1.0# 字节跳动# 视频生成模型10个月前03180
字节跳动 Seed 团队正式发布 SeedEdit 3.0:支持 4K 图像编辑,编辑可用率显著提升今日,字节跳动 Seed 团队正式发布了新一代图像编辑模型 SeedEdit 3.0。该模型基于文生图模型 Seedream 3.0,融合多样化的训练数据与奖励机制,在图像主体与背景一致性、指令理解能...图像模型# SeedEdit 3.0# 字节跳动10个月前02040
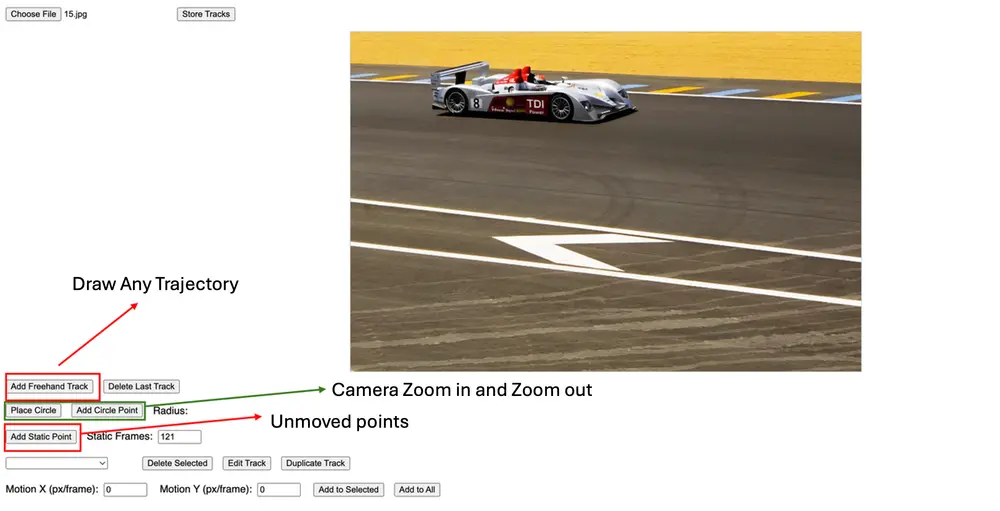
字节跳动推出全新视频生成框架 ATI:用“画轨迹”控制视频运动,对象、视角、局部变形一应俱全!字节跳动 AI 实验室发布了一项令人眼前一亮的视频生成技术 —— ATI(Any Trajectory Instruction),它让普通人也能通过“画轨迹”的方式,精准控制视频中物体的运动、镜头的移...视频模型# ATI# ATI-Wan2.1 14B# 字节跳动10个月前03850
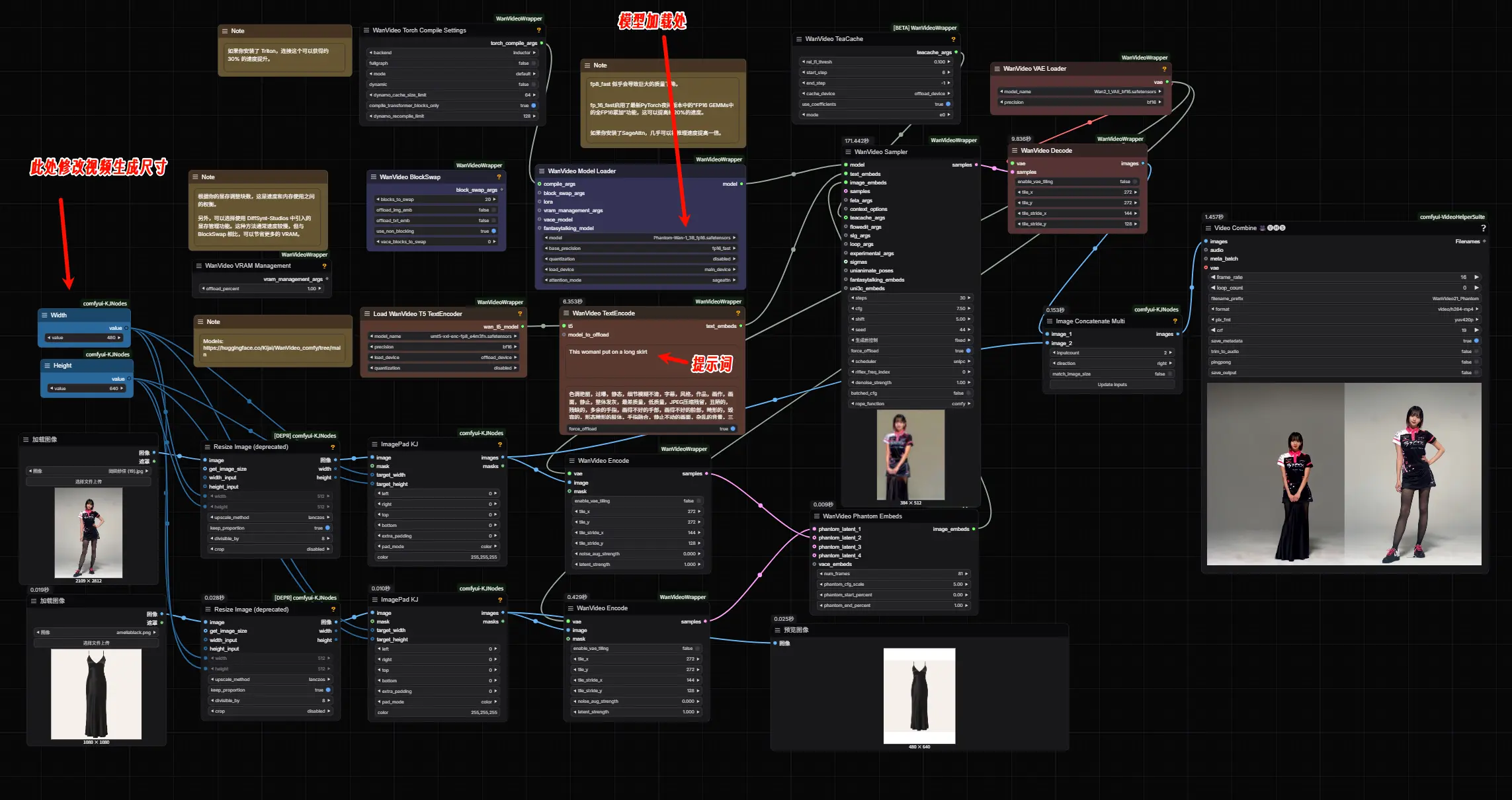
字节释出Phantom-Wan-14B!从参考图像中提取关键主体元素生成一致性视频字节跳动于4月份正式开源了其统一视频生成框架 Phantom,这是一个专注于“主体一致性(Subject-to-Video, S2V)”的视频生成框架。它能够从参考图像中提取关键主体元素,并结合文本描...工作流# Phantom-Wan-14B# 字节跳动# 视频编辑10个月前06880
开源版GPT-4o!字节跳动开源新一代多模态模型 BAGEL:多模态理解、图像生成、图像编辑,还能“思考”字节跳动发布了一款名为 BAGEL 的开源多模态基础模型,该模型拥有 70 亿活跃参数(总规模为 140 亿),在大规模交错多模态数据上进行训练。BAGEL 不仅在标准多模态理解排行榜中超越了当前主流...图像模型# BAGEL# GPT-4o# 多模态模型10个月前09170
字节跳动推出多模态文档图像解析模型Dolphin在复杂文档图像理解和结构化提取任务中,如何准确识别并组织交织的文本段落、公式、表格和图像,一直是业界的技术难点。 GitHub:https://github.com/bytedance/Dolphin...多模态模型# Dolphin# 多模态模型# 字节跳动9个月前04040