Anzhc 开源系列 YOLO 模型:专注细粒度图像分割与分类任务在图像检测与分割领域,高质量的专用模型往往能显著提升下游任务的表现。开发者 Anzhc 基于自建标注数据集,训练并开源了一系列面向特定视觉任务的 YOLO 模型,涵盖面部、眼部、头部、胸部等细粒度目标...图像模型# YOLO 模型# 图像分割7个月前05130
南洋理工大学 S-Lab 提出新型对象移除框架ObjectClear ,精准消除物体及其阴影、反射在图像编辑任务中,移除一个物体看似简单,实则极具挑战。 不仅要将目标对象从画面中“擦除”,还需同步清除其带来的视觉副产物——如阴影、倒影、高光、遮挡痕迹等。若处理不当,即便主体消失,残留的影子或反光仍...图像模型# ObjectClear# 南洋理工大学# 对象移除7个月前03950
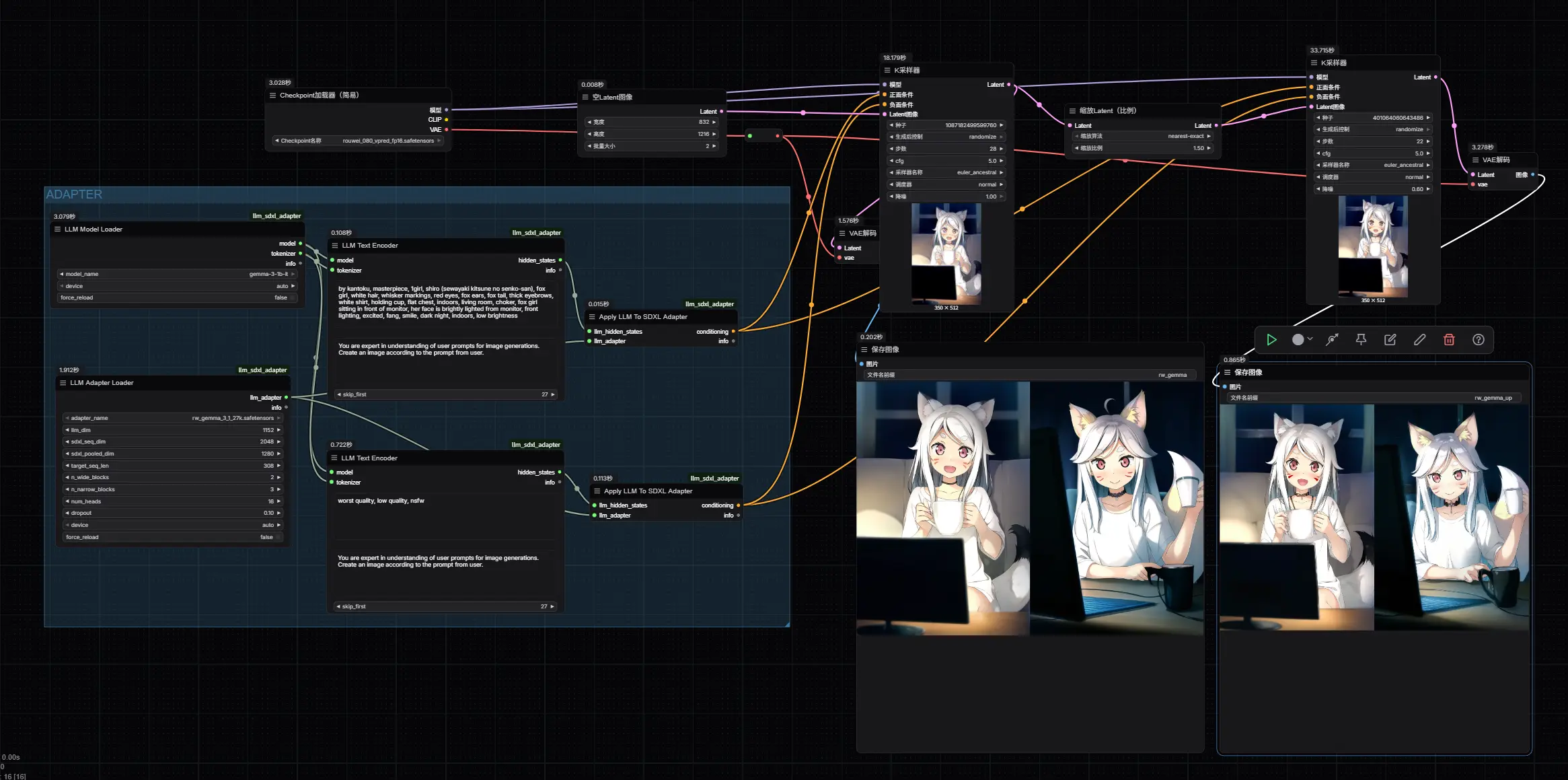
RouWei-Gemma:基于 Gemma-3-1b 的文本编码器适配器(用于 Rouwei 0.8)RouWei-Gemma是一个为 Rouwei 0.8 开发的文本编码器适配器,基于 Gemma-3-1b 构建,用于替换 SDXL 中的 CLIP 文本编码器。它利用大语言模型(LLM)的强大语义理...图像模型# Gemma-3-1b# Rouwei 0.8# RouWei-Gemma7个月前02950
字节跳动 & 复旦大学联合提出智能海报生成新框架 DreamPoster在 AI 生成图像(AIGC)领域,海报设计一直是极具挑战性的任务之一。它不仅要求模型理解文本描述,还需要兼顾视觉美感、排版逻辑和品牌一致性。近日,字节跳动与复旦大学的研究团队联合提出了一种新的文本...图像模型# DreamPoster# 字节跳动# 海报设计7个月前03940
T-LoRA:基于时间步敏感机制的扩散模型个性化定制方法在图像生成任务中,扩散模型凭借强大的表达能力成为主流方案。然而,在仅有一张图像作为训练样本的情况下,模型容易出现过拟合现象,导致生成结果过度依赖原始图像背景或姿态,而无法很好地响应文本提示。 为此,研...图像模型# T-LoRA7个月前01100
NovelAI 正式公开了其基于SD1.5的第二代图像生成模型 NovelAI Diffusion V2NovelAI 正式公开了其第二代图像生成模型 NovelAI Diffusion V2 的权重文件,供研究、个人使用及历史保存。这一举动意味着即使该模型在 NovelAI 官网停止服务后,用户仍可通...图像模型# NovelAI Diffusion V2# SD1.58个月前03400
阿里Ovis团队发布统一多模态模型Ovis-U1:理解、生成与编辑三位一体近日,阿里巴巴通义实验室Ovis团队正式发布了新一代统一多模态大模型——Ovis-U1。该模型以30亿参数为基础,实现了对多模态任务的全面覆盖,涵盖图像理解、文本到图像生成以及图像编辑三大核心能力。 ...图像模型# Ovis-U1# 统一多模态模型8个月前02380
BRIA AI 推出 Bria 3.2:专为商业设计的下一代文本到图像模型BRIA AI 正式发布其最新文本到图像模型 Bria 3.2。作为一款专为企业和商业应用打造的生成模型,Bria 3.2 凭借仅 40 亿参数 的轻量架构,在美学效果与文本渲染能力方面表现优异,经评...图像模型# Bria 3.2# BRIA AI8个月前01670
字节跳动提出的新一代多主体可控图像生成模型XVerse在文本到图像生成领域,如何实现对多个主体身份和语义属性(如姿势、风格、照明)的细粒度控制,同时保持高质量和一致性,一直是一个极具挑战性的问题。 传统方法往往存在以下问题: 在多主体场景中容易引入视觉伪...图像模型# XVerse# 图像生成模型8个月前04060
JarvisArt:由AI驱动的照片修饰智能体,释放你的艺术创造力来自厦门大学、香港科技大学(广州)、字节跳动、新加坡国立大学等机构的研究人员联合推出了一项令人瞩目的新成果 —— JarvisArt。这是一个由多模态大语言模型(MLLM)驱动的照片修饰智能体,能够理...图像模型# JarvisArt# 照片修饰智能体8个月前03870
黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]截至今日,所有高性能的生成式图像编辑模型均为专有工具。今天,这一局面发生了改变。 黑森林实验室(Black Forest Labs)发布了 FLUX.1 Kontext [dev],这是 FLUX.1...图像模型# FLUX.1 Kontext [dev]# 图像编辑模型# 黑森林实验室8个月前06060
Janus-4o:基于数据集 ShareGPT-4o-Image 的新型多模态图像生成模型香港中文大学(深圳) 的研究人员推出了一项重要的多模态研究成果 —— ShareGPT-4o-Image 数据集 及其衍生的开源多模态大语言模型 Janus-4o。该研究旨在将 GPT-4o 在图像生...图像模型# Janus-4o# ShareGPT-4o-Image# 数据集8个月前03410








![黑森林实验室正式发布图像编辑模型FLUX.1 Kontext [dev]](https://pic.sd114.wiki/wp-content/uploads/2025/06/1750964036-1750964036-FLUX.1-Kontext-2.webp~tplv-o4t1hxlaqv-image.image)






