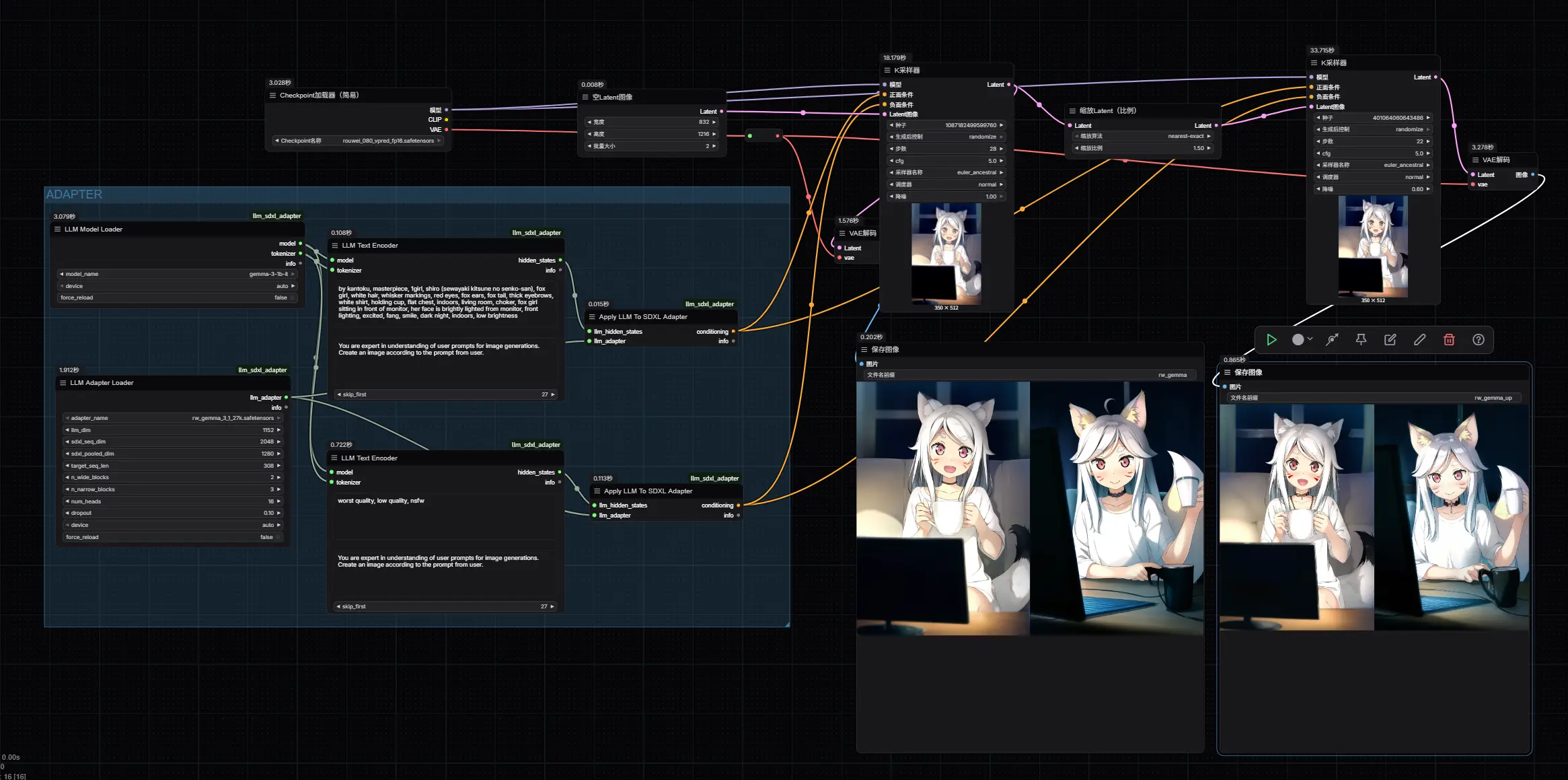
RouWei-Gemma是一个为 Rouwei 0.8 开发的文本编码器适配器,基于 Gemma-3-1b 构建,用于替换 SDXL 中的 CLIP 文本编码器。它利用大语言模型(LLM)的强大语义理解能力,显著提升提示处理与条件生成的灵活性和深度。
该文本编码器通过引入现代语言模型的能力,增强 SDXL 系列模型在理解复杂提示、处理长文本、结构化描述等方面的表现。与 ELLA、SDXL-T5 类似,但专注于:
- 动漫风格内容
- 无审查的高级语义理解
- 更灵活的提示控制
为什么重要?
SDXL 是一个高效、灵活且生成质量极佳的图像生成模型,但在提示理解方面受限于 CLIP 编码器 的能力,具体表现为:
- 最大支持 75 个 token,长提示需截断或拆分,影响语义完整性
- 对自然语言、复杂描述、结构化输入理解有限
- 缺乏对角色、姿势、对象等高级控制的支持
通过将 CLIP 替换为基于 LLM 的文本编码器,我们可以在不牺牲 SDXL 原有优势的前提下,实现:
- 更强的提示理解能力
- 支持自然语言、结构化描述、多角色控制
- 与图像、坐标、OpenPose 姿势等多模态条件协同工作
⚙️ 工作原理
- 提示处理:用户输入的文本提示由 Gemma-3-1b 处理。
- 隐藏状态提取:提取最后一层的隐藏状态(hidden states)。
- 适配器转换:适配器将这些隐藏状态转换为 SDXL UNet 可接受的条件格式。
- 生成图像:UNet 基于新的文本条件生成图像。
这一过程保留了 SDXL 的生成架构,同时增强了其对提示语义的理解能力。
🧪 为什么选择 Gemma-3?
- 轻量且性能适中:适合实验和训练
- 开放、无审查:适配器仅使用隐藏状态,不涉及输出文本
- 未来可替换:后续可能采用 Qwen-VL 或其他更强模型替代
✅ 当前功能(概念验证阶段)
尽管仍处于实验阶段,该适配器已实现以下功能:
- 支持 Booru 风格标签
- 支持自然语言提示(极短至极长,最多 512 token)
- 支持 Markdown、XML、JSON 等结构化提示格式
- 支持上述格式的任意组合
- 提示理解更深入,避免标签混淆问题
可作为标准文本编码器使用,但对长提示理解更准确,条件干扰更少。
⚠️ 当前限制
- 复杂提示可能处理不佳
- 对稀有角色识别较好,但部分流行角色可能混淆
- 风格理解不稳定
- 使用某些艺术家风格可能导致部分提示被忽略
- 不支持强调标签(如
:1.1)和拼写权重(括号无效) - 需要更多训练数据与 UNet 微调优化
这些问题将通过进一步训练逐步解决。
🛠️ 如何运行
所需组件:
- ComfyUI 自定义节点(https://github.com/NeuroSenko/ComfyUI_LLM_SDXL_Adapter)
- Transformers 支持 Gemma-3 的版本
- 适配器模型文件(放入
/models/llm_adapters) - Gemma-3-1b-it 模型文件(放入
/models/LLM/gemma-3-1b-it) - Rouwei-0.8 检查点(vpred / epsilon / base-epsilon)
推荐步骤:
- 安装自定义节点并更新 Transformers
- 下载 Gemma-3-1b-it 模型(建议使用 Hugging Face Hub 下载)
- 将适配器放入指定路径
- 加载 Rouwei 检查点
- 使用提供的工作流作为参考,自由实验
📌 提示使用技巧
- 艺术家标签建议放在提示末尾,避免干扰语义
- 复杂部分尽量放在提示开头
- 描述姿势、动作、对象时可自由添加细节
- 避免填充标签和重复描述
- 拼写错误将严重影响理解,需格外注意
当前节点不支持括号权重和标准拼写语法,无需添加 \。
🏅 质量标签建议
正面标签(可选):
masterpiecebest quality
建议保持简洁,避免“魔法组合”。
负面标签(可选):
worst qualitylow quality
同样建议只添加你明确不希望出现的内容。
🧠 知识能力
- 理解流行角色和艺术风格
- 支持基本概念理解与语义推理
- 受限于当前训练数据集(以动漫为主)和 UNet 能力
后续将通过 LLM 和 UNet 的进一步训练扩展知识覆盖范围。
🔌 兼容性
- 专为 Rouwei 0.8 设计
- 兼容其微调与合并版本
- 对 Illustrious、Noobai 等 SDXL 检查点兼容性有限
📅 后续计划
- 增加更多训练数据,提升 LLM 与 UNet 的协同能力
- 完善自定义节点功能(如标签权重、拼写支持)
- 开源训练代码与适配器微调流程
- 探索更高性能的语言模型替代 Gemma
📢 结语
这个基于 Gemma-3-1b 的文本编码器适配器,是 SDXL 模型迈向更强大提示理解能力的一次重要尝试。虽然目前仍处于实验阶段,但它已经展示了在长提示处理、结构化输入理解、多角色控制等方面的巨大潜力。
如果你正在寻找一个突破 CLIP 限制、探索更自然提示输入方式的方案,不妨尝试这个适配器。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











