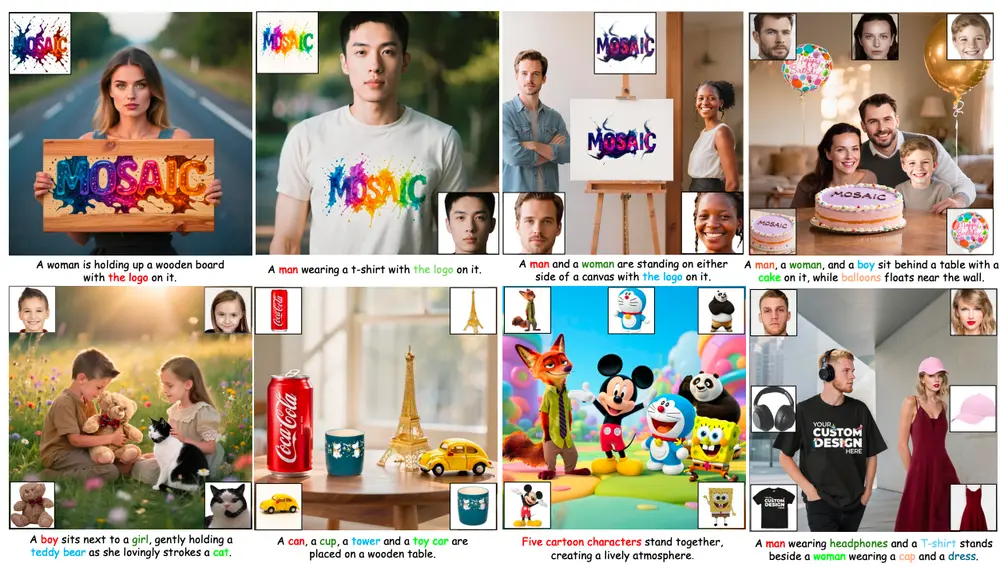
MOSAIC:通过语义对齐与特征解耦实现高保真的多主体个性化生成在个性化图像生成任务中,我们常常希望将多个参考主体(如人物、动物、物体)的特征融合到一张新图像中——例如,“让A的脸型、B的发型、C的表情和D的服饰出现在同一人身上”。这类任务被称为多主体个性化生成...图像模型# MOSAIC# 个性化生成5个月前01510
LEGION:一个能“看懂”伪造痕迹并指导图像优化的多模态分析框架随着生成模型的飞速发展,AI 合成图像已变得越来越逼真。然而,这种进步也带来了严峻挑战:虚假内容泛滥、误导信息传播、数字信任危机加剧。 作为应对,合成图像检测技术应运而生。但当前方法普遍存在三大局限...图像模型# LEGION# 多模态分析框架6个月前01510
黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型黑森林实验室(Black Forest Labs)今日正式推出 FLUX.2 [klein] 模型系列——这是目前速度最快、体积最小的高质量图像生成模型家族。它将文生图、图像编辑与多参考图生成统一于单...图像模型# FLUX.2 [klein]# 黑森林实验室2周前01300
UFC:韩国科学技术院推出的通用少样本图像控制适配器在文本到图像生成领域,如何让预训练模型快速适应新的空间控制条件(如边缘图、深度图、人体姿态等),一直是一个挑战。传统方法通常需要大量标注数据和高昂的训练成本,限制了其灵活性与实用性。 GitHub:h...图像模型# UFC# 图像控制适配器5个月前01210
FLUX-Reason-6M & PRISM-Bench:600 万级 T2I 推理数据集 + 七轨道基准,开源模型研发新助力在文本到图像(Text-to-Image, T2I)生成领域,一个长期存在的困境是:开源模型越做越像,却始终难以真正“理解”复杂指令。 问题不在架构,而在数据与评估 —— 缺乏大规模、注重语义推理的训...图像模型# FLUX-Reason-6M# PRISM-Bench5个月前01180
T-LoRA:基于时间步敏感机制的扩散模型个性化定制方法在图像生成任务中,扩散模型凭借强大的表达能力成为主流方案。然而,在仅有一张图像作为训练样本的情况下,模型容易出现过拟合现象,导致生成结果过度依赖原始图像背景或姿态,而无法很好地响应文本提示。 为此,研...图像模型# T-LoRA7个月前01080
1步顶100步!TwinFlow让Qwen-Image、Z-Image推理提速100倍,无需判别器或教师模型当前,大规模多模态生成模型(如 Qwen-Image、Z-Image)在图像与视频生成上展现出惊人能力,但其推理效率仍严重受限——标准扩散或流匹配模型通常需 40–100 次函数评估(NFE)才能生成...图像模型# TwinFlow# TwinFlow-Qwen-Image# TwinFlow-Z-Image-Turbo1个月前0940
Kandinsky 5.0 全系列开源:190亿参数视频Pro+轻量版,支持中俄双语+5-10秒HD生成来自俄罗斯的AI企业Sber AI,正式推出新一代扩散模型家族 Kandinsky 5.0,以“全场景覆盖+开源开放”为核心亮点,涵盖视频生成(T2V/I2V)、图像生成(T2I)、图像编辑三大核心能...图像模型视频模型# Kandinsky 5.02个月前0930
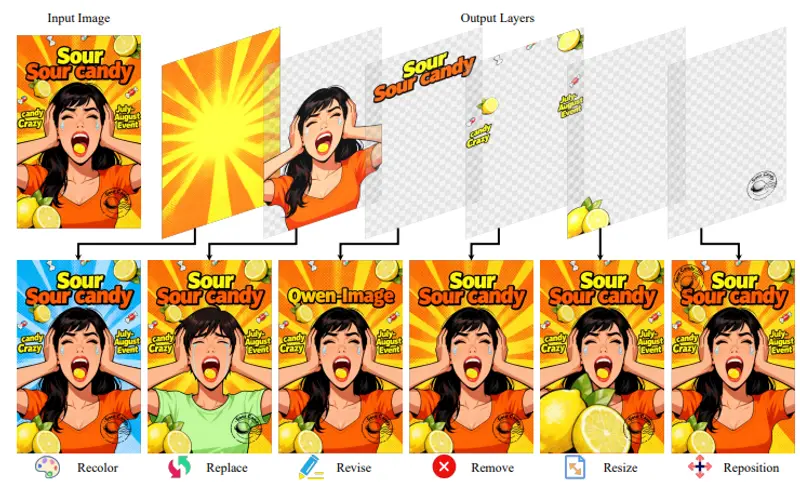
港科大与阿里推出Qwen-Image-Layered:将单图分解为可编辑RGBA图层,实现像素级精准编辑在传统图像编辑中,若想修改照片中的某个物体(如移动人物、更换背景、调整颜色),往往需要复杂的抠图、蒙版或手动重绘——操作繁琐,且容易破坏整体一致性。 由香港科技大学(广州)、阿里巴巴与香港科技大学联合...图像模型# Qwen-Image-Layered# RGBA图层# 编辑模型1个月前0820
黑森林实验室发布FLUX.2 :支持400万像素编辑+10图参考,开放权重模型刷新视觉AI上限在视觉AI领域,能够真正适配现实世界创意工作流的工具,往往比单纯的“演示级模型”更具价值。近日,黑森林实验室正式推出新一代视觉智能系统 FLUX.2,不仅在图像生成质量、细节还原度上实现突破,更以多参...图像模型# FLUX.2# 黑森林实验室2个月前0800
fal 发布FLUX.2 Turbo:开源图像模型速度提升6倍,成本降至0.008美元/图在完成 1.4 亿美元 D 轮融资后,AI 媒体基础设施平台 fal.ai(简称 fal)于年末推出其最新成果:FLUX.2 [dev] Turbo —— 一款基于 Black Forest Labs...图像模型# FLUX.2 Turbo1个月前0770
BRIA 发布 FIBO:用 JSON 精确控制光线、构图与相机参数的文生图模型BRIA 开源发布了其首个文本到图像模型 FIBO —— 一个专为专业图像生成工作流设计的 JSON 原生、结构化提示驱动 的开源模型。与主流强调“想象力”的生成模型不同,FIBO 的核心目标是 可控...图像模型# BRIA# FIBO# 文生图模型3个月前0740

![黑森林实验室发布 FLUX.2 [klein]:统一生成与编辑的最快开源模型](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500030-1768500030-FLUX.2-klein-2.webp~tplv-o4t1hxlaqv-image.image)