告别 “改不动”!ProEdit:反转编辑新方案,精准修改图像属性,即插即用超 SOTA解决源图像信息过度注入问题,实现更可控的图像与视频编辑 由中山大学、香港中文大学、香港大学与南洋理工大学联合提出,ProEdit 是一种高精度、即插即用的基于反转(inversion-based)的视...图像模型# ProEdit# 编辑图像1个月前0660
阿里DiffSynth-Studio 项目组推出Z-Image-i2L:从单张图像一键生成风格 LoRA阿里 DiffSynth-Studio 项目组 推出 Z-Image-i2L(Image to LoRA)模型——一种“以图生 LoRA”的创新方案。只需输入一张或多张风格统一的图像,模型即可自动生成...图像模型# DiffSynth-Studio# Z-Image-i2L4天前0590
Generative Refocusing:基于单张输入图像的生成式重聚焦方法Generative Refocusing 是一种基于单张输入图像的生成式重聚焦方法,能够将任意照片转化为一个“虚拟相机”,在拍摄后灵活调整焦点位置、焦外虚化强度、光圈形状等光学属性。该方法不仅支持从...图像模型# Generative Refocusing1个月前0590
扩散模型加速框架Glance:仅用 1 张图 + 1 GPU 小时,将扩散模型加速至 8 步武汉大学、新加坡国立大学、中南大学、电子科技大学和微软的研究人员推出一个用于加速扩散模型(Diffusion Models)的轻量级框架 Glance,通过“慢-快”(Slow-Fast)的阶段感知...图像模型# Glance# 加速框架2个月前0500
MotionEdit:首个专注动作编辑的图像生成基准与训练框架当前主流的图像编辑模型在处理静态属性(如颜色、纹理、物体替换)时已相当成熟,但在修改图像中主体的动作、姿势或交互行为时仍面临显著挑战。例如,让一个人从“站立”变为“坐下”,或让其“拿起桌上的杯子”,现...图像模型# MotionEdit# 图像编辑2个月前0470
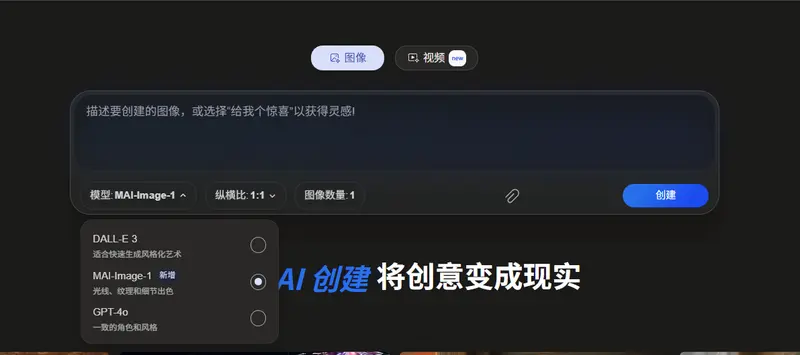
微软在Bing平台推出AI图像生成模型MAI-Image-1尽管微软已全面接入OpenAI最新前沿模型,该公司仍在自主研发AI模型,通过差异化产品与服务更好地满足用户需求。今年初,微软曾宣布首批两个自研AI模型:MAI-Voice-1与MAI-1-previe...图像模型# MAI-Image-1# 微软3个月前0420
阿里发布文生图模型Qwen-Image-2512:人像、纹理、文字渲染显著提升2025 年 12 月 31 日,阿里 Qwen 项目组发布了 Qwen-Image-2512 —— Qwen-Image 文生图基础模型的最新版本。这是继今年 8 月首次开源 Qwen-Image ...图像模型# Qwen-Image-2512# 文生图模型1个月前0340
阿里通义 MAX 项目组发布 Z-Image :支持 CFG 与微调,面向专业创作的非蒸馏基础模型在用户热切期盼下,阿里通义 MAX 项目组正式开源 Z-Image 完整版——这是 Z-Image 系列的基础大模型,专为追求最高生成质量、最大创作自由度与最强提示控制力的专业用户设计。 Huggin...图像模型# Z-Image# 通义 MAX4天前0170
新腾讯混元推出 HunyuanImage 3.0-Instruct:原生多模态图像编辑模型,支持精准编辑与多图融合腾讯混元项目组正式开源 HunyuanImage 3.0-Instruct —— 一款专注于图像编辑的原生多模态大模型。该模型不仅能理解输入图像的语义内容,还能基于复杂指令进行推理,并生成高保真、高一...图像模型# HunyuanImage 3.0-Instruct# 多模态图像编辑模型2天前0100