Fal.ai平台推出新DiT模型AuraFlow:支持文字,百分百开源Stability AI因为Stable Diffusion 3 Medium模型的许可证问题备受诟病,虽然后来更改了许可证,但此模型在人物尤其是躺倒后人物的糟糕表现还是不受开源社区待见。不少人开始转...图像模型# AuraFlow# DiT模型# Fal.ai12个月前06400
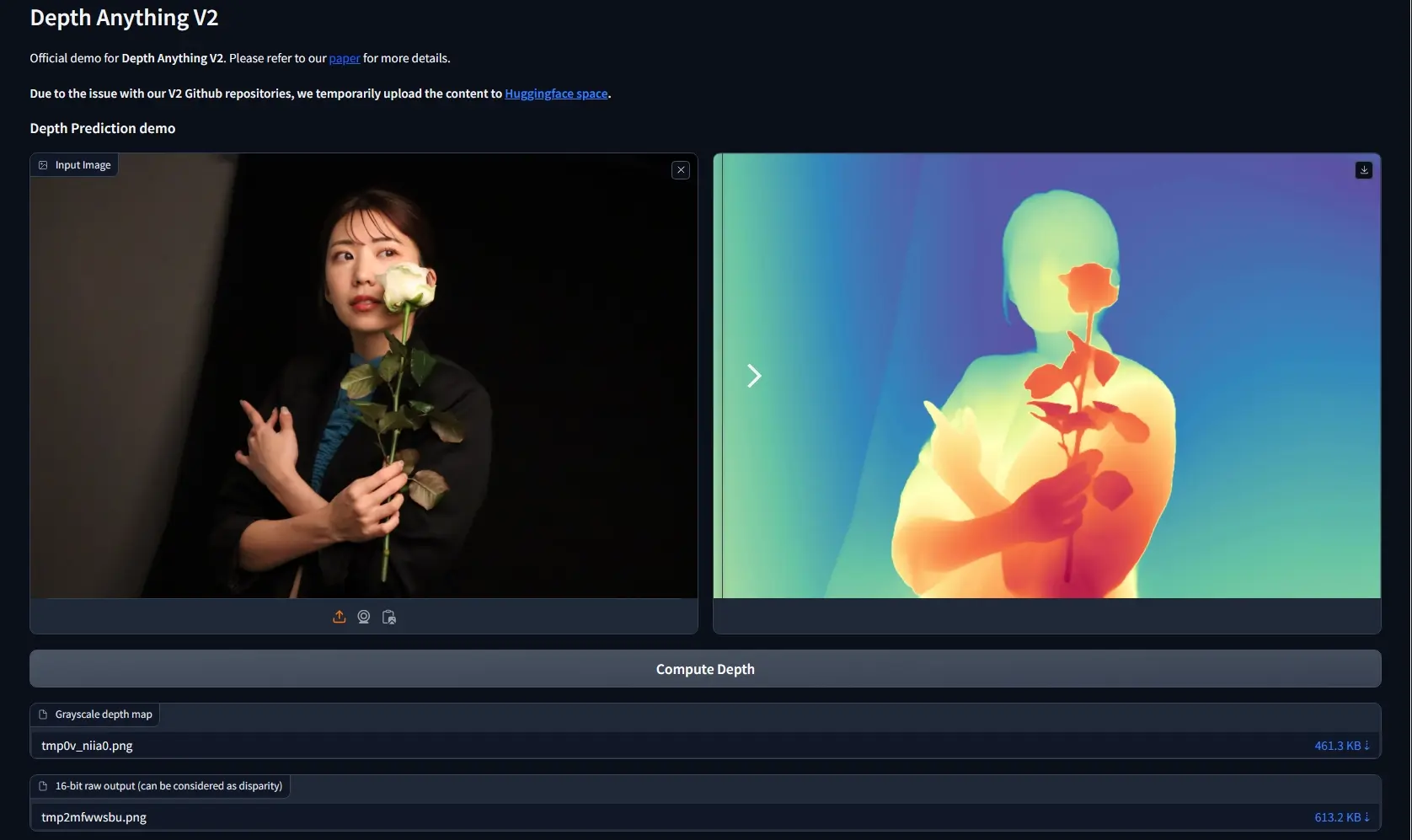
单目深度估算模型Depth Anything V2:通过分析单张图片来预测物体距离来自香港大学和TikTok的研究人员推出单目深度估算模型Depth Anything的升级版Depth Anything V2,让计算机通过分析单张图片来预测物体距离的技术,这在自动驾驶、3D建模和虚...图像模型# Depth Anything V2# 单目深度估算模型12个月前01,2100
Stability AI释出Stable Diffusion 3 Medium模型,8G显存显卡即可使用Stability AI终于在6月12日释出了万众期待的Stable Diffusion 3模型,不过此次释出的仅是 20 亿个参数的Stable Diffusion 3 Medium 模型,该型号尺...图像模型# SD3模型# Stability AI# Stable Diffusion 3 Medium12个月前05,0500
Jasper推出新型蒸馏方法Flash Diffusion:高效、快速、多用途且与LoRA兼容,旨在加速预训练扩散模型图像生成Jasper推出了一种高效、快速、多用途且与LoRA兼容,旨在加速预训练扩散模型生成的蒸馏方法Flash Diffusion,该方法在COCO 2014和COCO 2017数据集上,针对少量步骤的图像...图像模型# Flash Diffusion# Jasper# 蒸馏模型12个月前08500
SDXL系列新模型SDXL Flash:高速且保证质量的SDXL模型Stable Diffusion Community是一个非官方、非盈利性质的组织,它们主要目标是尽可能改进 SD 模型并让每个人都可以使用它们,近期它们推出了新的SDXL系列模型SDXL Flash...图像模型# SDXL Flash# sdxl-flash-mini# 高速模型12个月前01,0260
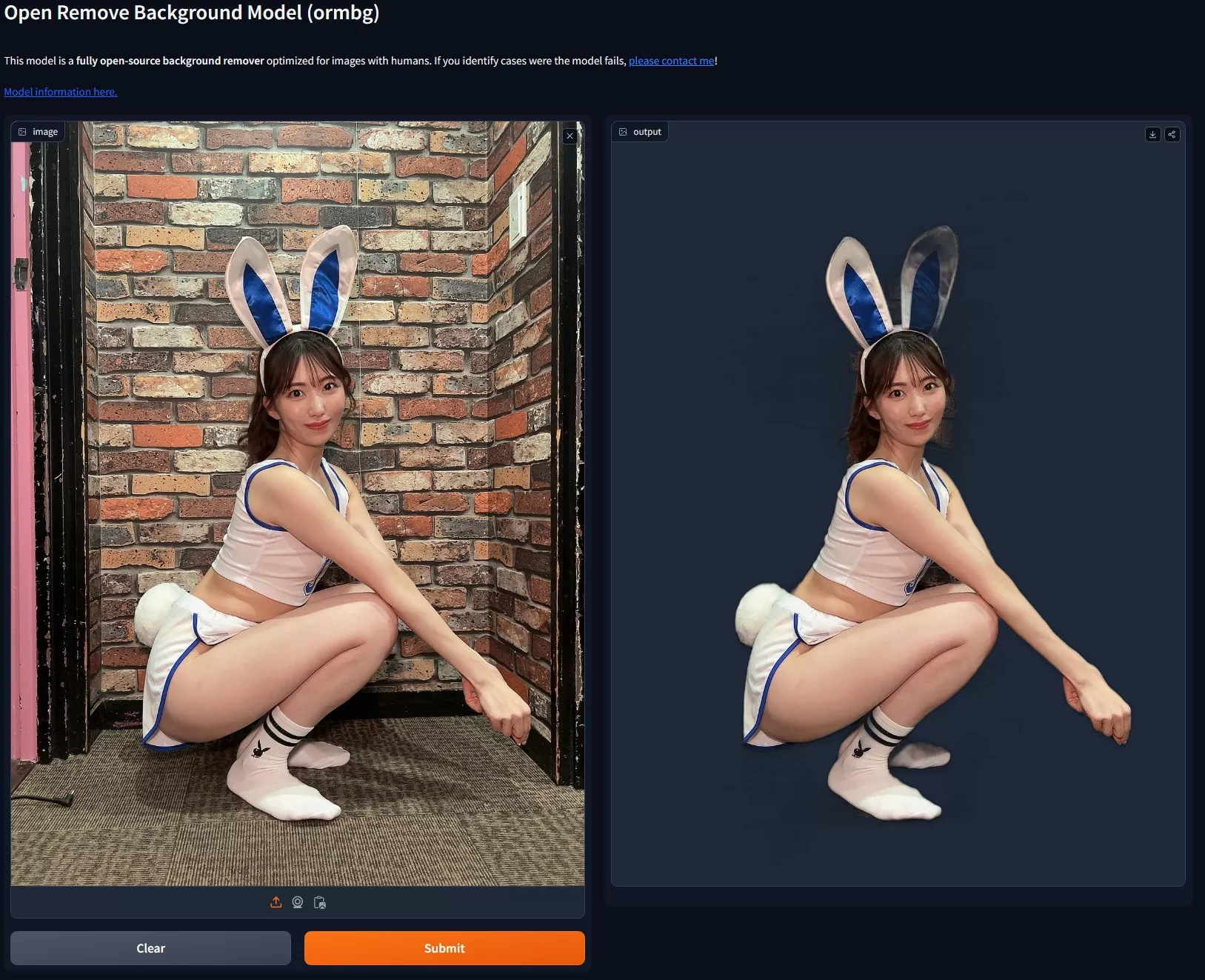
全新开源背景移除模型ormbg:专门针对含有人物的图像进行了优化ormbg是一个基于基于高度准确的二分类图像分割(DIS)的全新开源背景移除模型,它专门针对含有人物的图像进行了优化,此模型类似于 RMBG-1.4,但提供了开放的训练数据和流程,且商业使用免费。它提...图像模型# DIS# ormbg# 背景移除模型12个月前01,1750
字节跳动推出新型蒸馏模型Hyper-SD:基于SD1.5和SDXL1.0基础模型提炼字节跳动在推出文生图模型SDXL-Lightning后,又推出了新的蒸馏模型Hyper-SD,它有效地结合了ODE轨迹保留和重构的优点,同时在步骤压缩过程中保持了接近无损的性能。与SDXL-Light...图像模型# Hyper-SD# 字节跳动# 蒸馏模型12个月前01,1830
文生图模型新架构MoA:根据用户的个性化需求生成包含特定人物的图像,同时保持原有模型的风格和多样性Snap推出新架构注意力混合(Mixture-of-Attention,简称MoA),即在个性化图像生成中实现主体与上下文解耦的注意力混合模型(MoA),用于个性化文本到图像的扩散模型。简单来说,Mo...图像模型# MoA# 文生图模型12个月前09890
虚拟服装试穿Magic Clothing:根据特定的服装和文本提示来生成穿着这些服装的定制化角色图像小i研究院发布了OOTDiffusion的分支版本Magic Clothing,它能够根据特定的服装和文本提示来生成穿着这些服装的定制化角色图像。这项技术的核心在于高度的图像可控性,即在生成的图像中保...图像模型# Magic Clothing# 虚拟服装试穿12个月前01,1170
高效且多功能的框架Ctrl-Adapter:在各种图像和视频生成模型中加入丰富的控制功能北卡罗来纳大学教堂山分校的研究人员推出高效且多功能的框架CTRL-Adapter,它能够为任何图像或视频扩散模型添加多样的空间控制功能。它支持多种实用的应用,如视频控制、多条件视频控制、稀疏帧条件下的...图像模型# Ctrl-Adapter# 空间控制# 视频生成模型12个月前08380
新型超分辨率技术APISR:专门针对动漫图像和视频的高质量增强来自密歇根大学、耶鲁大学和浙江大学推出新型超分辨率技术APISR,专门针对动漫图像和视频的高质量增强。超分辨率技术(Super-Resolution, SR)是一种图像处理技术,旨在从低分辨率的图像中...图像模型# APISR# 动漫图像# 超分辨率技术12个月前08430
统一框架UniFL:通过统一的反馈学习来提升稳定扩散模型(Stable Diffusion)的性能来自字节跳动和中山大学的研究人员推出利用反馈学习机制来全面增强扩散模型的统一框架UniFL,它通过统一的反馈学习来提升稳定扩散模型(Stable Diffusion)的性能。UniFL作为一种通用、高...图像模型# Stable Diffusion# UniFL12个月前07500