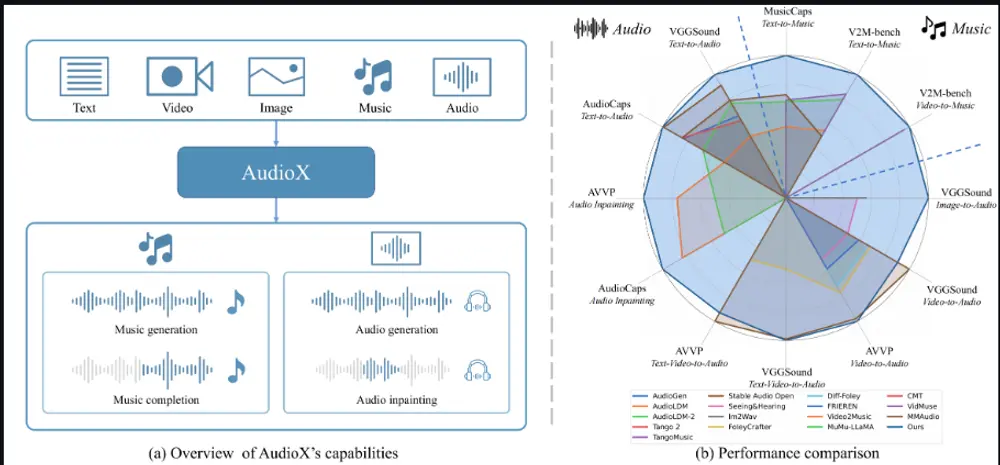
新型多模态音频生成框架AudioX:通过统一的模型架构实现从各种输入模态(如文本、视频、图像、音频等)生成高质量的音频和音乐香港科技大学的研究人员推出新型多模态音频生成框架“AudioX”,通过统一的模型架构实现从各种输入模态(如文本、视频、图像、音频等)生成高质量的音频和音乐。该框架通过创新的多模态掩码训练策略,强制模型...语音模型# AudioX# 多模态音频生成11个月前01870
高效语音分离模型TIGER:解决低延迟语音处理系统中的高效率问题清华大学的研究人员推出高效语音分离模型TIGER,解决低延迟语音处理系统中的高效率问题。语音分离是指从混合音频信号中准确分离出不同声音源的任务,类似于人类在嘈杂环境中专注于特定语音信号的“鸡尾酒会效应...语音模型# TIGeR# 语音分离模型11个月前04390
Stability AI发布可在智能手机运行的音频生成模型Stable Audio Open SmallAI 初创公司 Stability AI 发布了 Stable Audio Open Small,这是一款专为移动设备设计的音频生成模型。据公司宣称,这是目前市场上最快的音频生成模型,并且效率高到可以...语音模型# Stability AI# Stable Audio Open Small11个月前02230
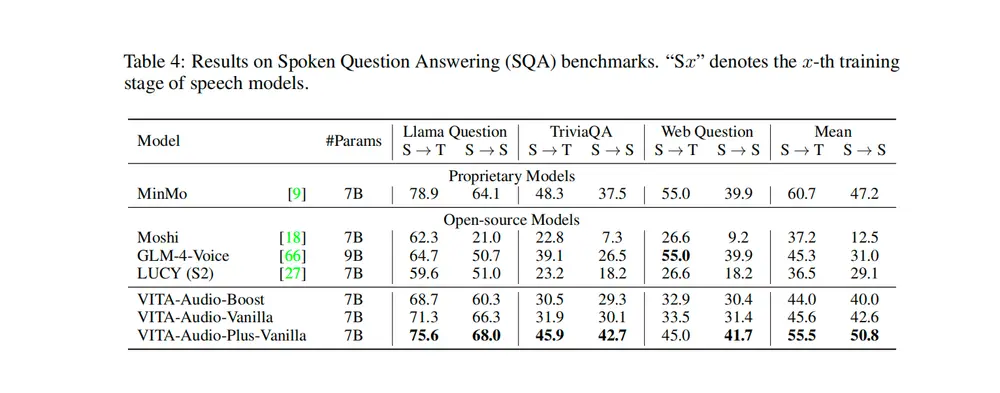
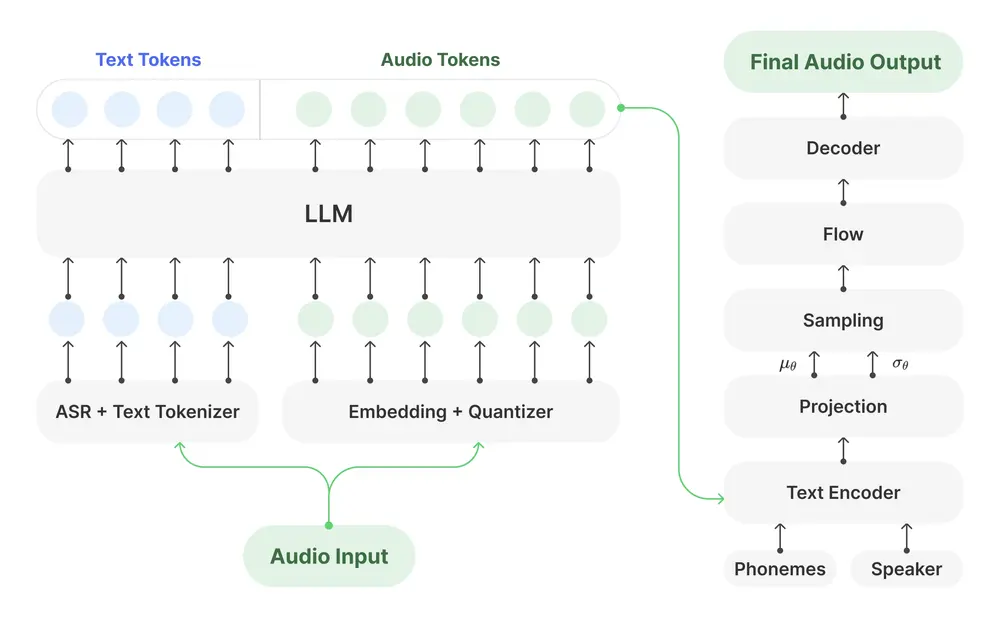
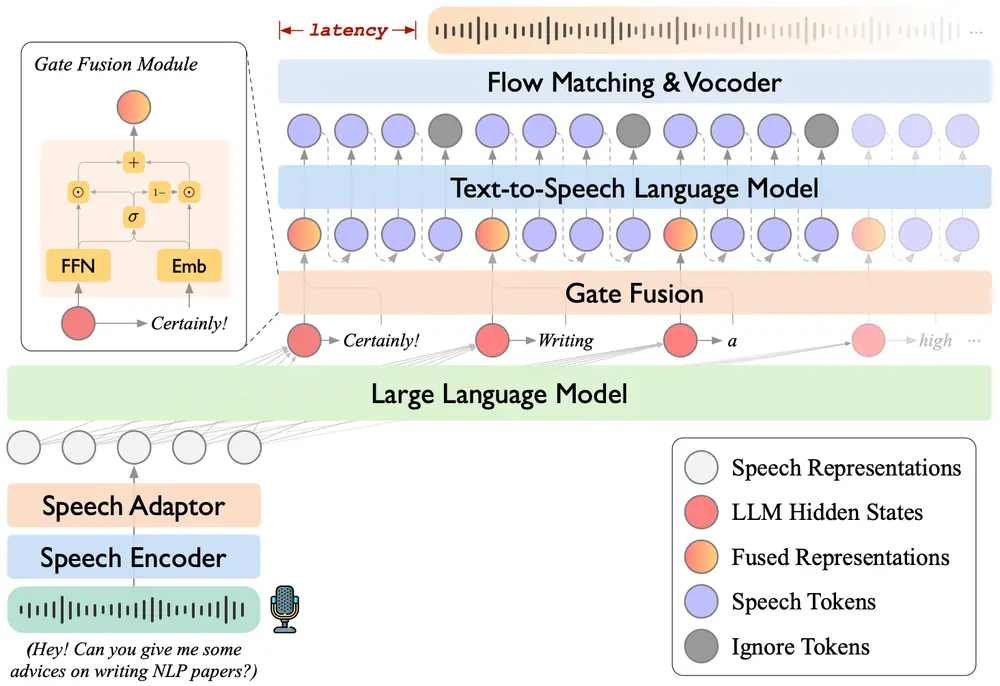
多模态语音交互的端到端大型语音模型 VITA-Audio腾讯优图实验室、南京大学和厦门大学的研究人员推出用于高效多模态语音交互的端到端大型语音模型 VITA-Audio,VITA-Audio 的目标是通过快速生成音频和文本令牌,显著降低流式语音交互中的延迟...语音模型# VITA-Audio# 语音模型11个月前02410
北京沐言智语科技开源专为播客场景优化的可训练TTS模型 Muyan-TTS 北京沐言智语科技开源可训练文本到语音(TTS)模型 Muyan-TTS ,专为播客场景优化,并在5万美元的预算内开发。该模型通过在超过10万小时的播客音频数据上进行预训练,能够实现高质量的零样本文本到...语音模型# Muyan-TTS# TTS模型11个月前03970
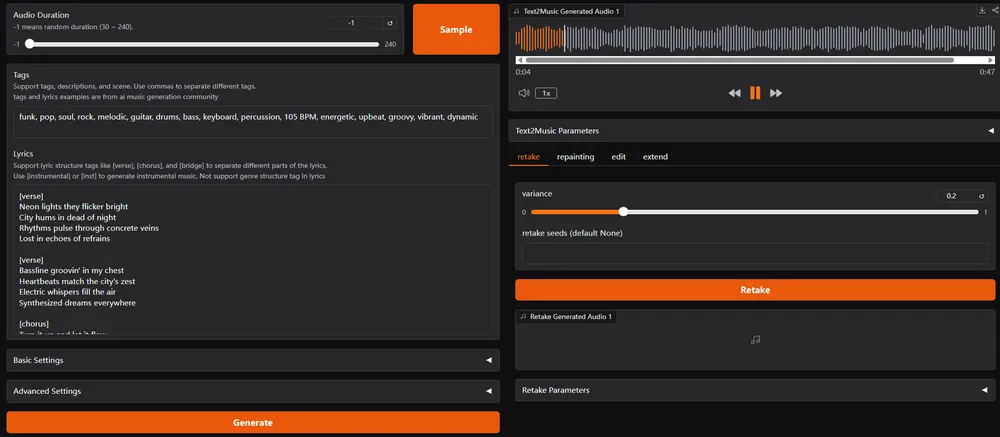
音乐生成基础模型ACE-Step:通过创新的整体架构设计,快速生成高质量音乐ACE Studio和阶跃星辰(StepFun)联合推出了一款全新的开源音乐生成基础模型ACE-Step,该模型通过创新的整体架构设计,突破了现有方法的局限性,实现了卓越的性能表现。 GitHub:h...语音模型# ACE-Step# 音乐模型11个月前05090
新型语音语言模型 LLaMA-Omni 2:实现高质量的实时语音交互中国科学院计算技术研究所、中国科学院人工智能安全重点实验室和中国科学院大学的研究人员推出新型语音语言模型 LLaMA-Omni 2 ,旨在实现高质量的实时语音交互。LLaMA-Omni 2 基于 Qw...语音模型# LLaMA-Omni 2# 语音语言模型11个月前02780
新型语音语言基础模型Voila :实现自然、实时、自主的语音交互Maitrix.org、加州大学圣地亚哥分校和MBZUAI的研究人员推出新型语音语言基础模型Voila ,旨在实现自然、实时、自主的语音交互。Voila 通过端到端的架构设计,突破了传统语音交互系统...语音模型# Voila# 语音语言基础模型11个月前04920
英伟达推出自动语音识别模型Parakeet-TDT-0.6B-v2:专为高质量英语语音转录设计英伟达推出的 Parakeet-TDT-0.6B-v2 是一款拥有 6 亿参数的自动语音识别(ASR)模型,专为高质量英语语音转录设计。该模型支持标点符号、大写和精准的时间戳预测,能够处理长达 24 ...语音模型# Parakeet-TDT-0.6B-v2# 自动语音识别模型自动语音识别模型# 英伟达11个月前05090
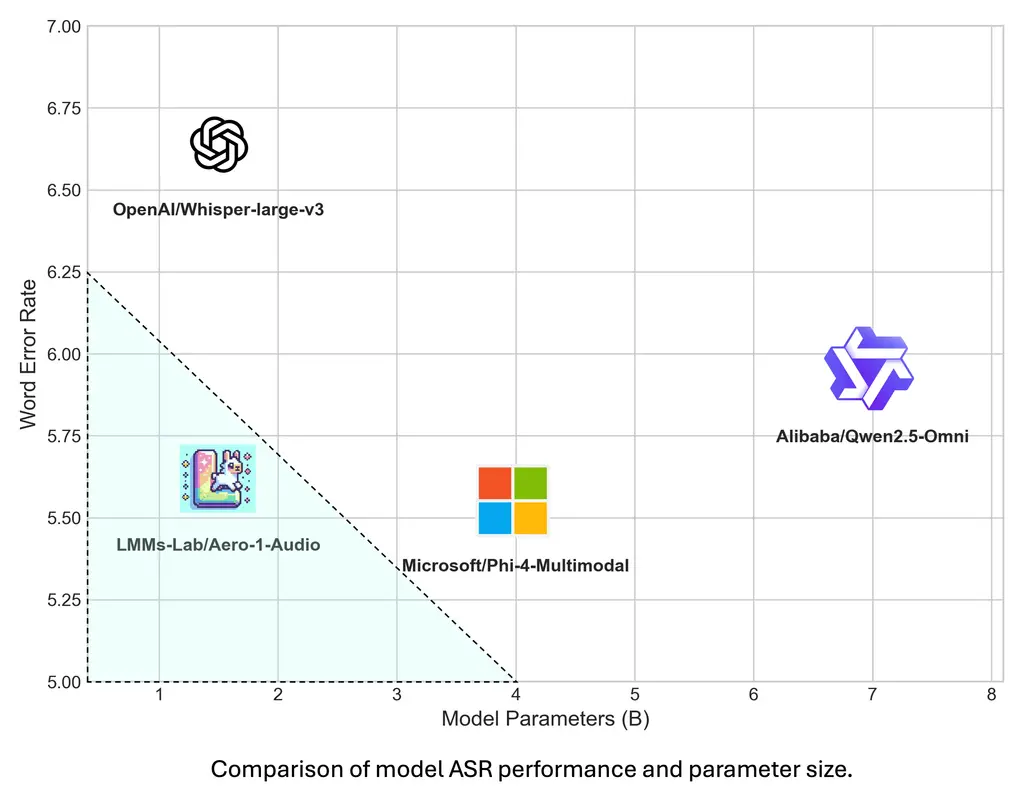
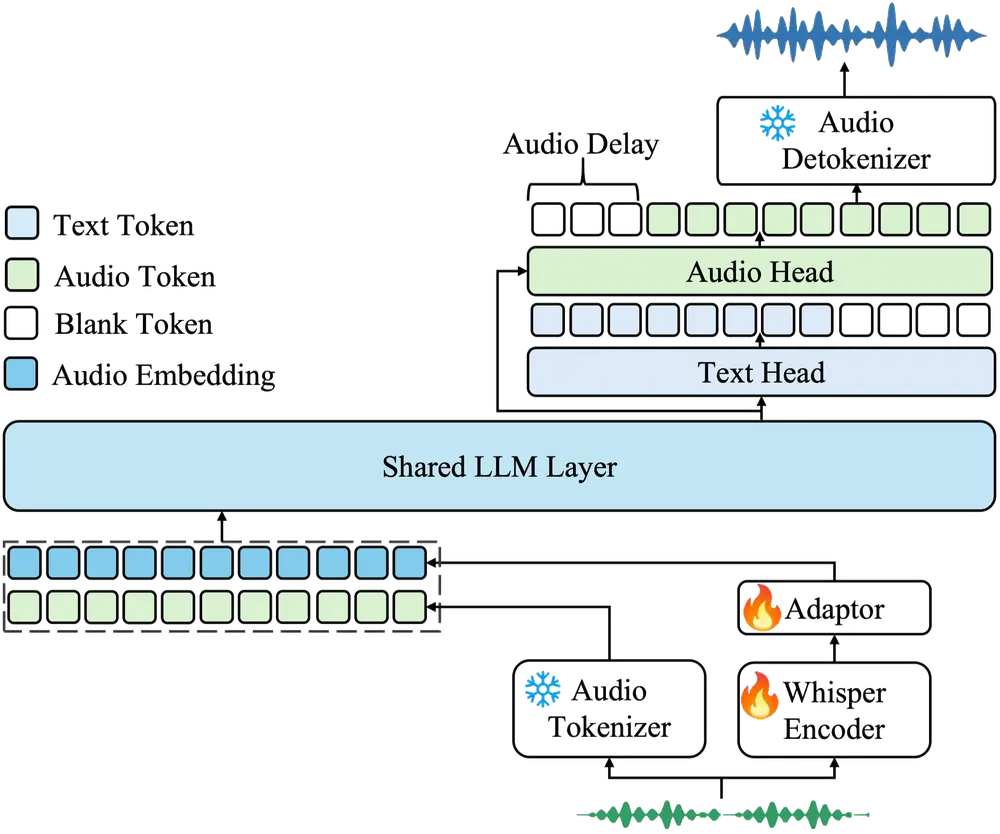
LMMs-Lab发布轻量高效音频模型Aero-1-Audio:擅长长语音ASR与多模态任务LMMs-Lab 推出了一款紧凑型音频模型 Aero-1-Audio,专为多种音频任务设计,包括语音识别(ASR)、音频理解和音频指令跟随。作为 Aero-1 系列的第一代产品,Aero-1-Audi...语音模型# Aero-1-Audio# LMMs-Lab# 语音识别11个月前06720
月之暗面开源端到端语音对话的通用音频模型Kimi-Audio月之暗面开源了一款名为 Kimi-Audio 的通用音频模型。这款模型以其统一的框架和强大的多功能性,在音频处理领域引起了广泛关注。Kimi-Audio 不仅能够处理语音识别、音频问答、字幕生成等任务...语音模型# Kimi-Audio# 月之暗面12个月前03410
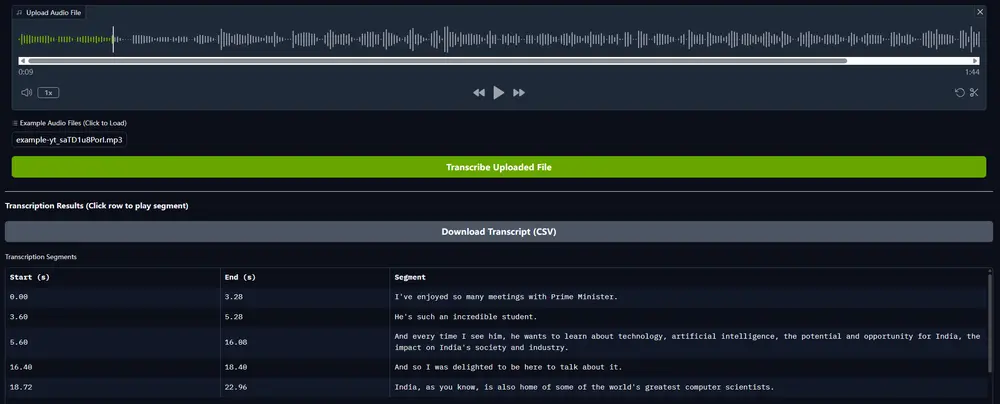
IBM 首个开源的语音转文本(STT)和自动语音翻译(AST)模型Granite Speech 3.3 8B随着AI在企业系统中的深度集成,对灵活性、效率和透明度兼具的模型需求日益增加。然而,当前市场上的解决方案往往难以满足这些要求:开源模型可能缺乏特定领域的能力,而专有系统则可能限制访问或适应性。尤其在语...语音模型# AST# Granite Speech 3.3 8B# IBM12个月前05040