上海交通大学发布SmallThinker 系列模型:专为设备端部署设计的原生混合专家(MoE)语言模型由上海交通大学 IPADS 实验室、人工智能学院与 Zenergize AI 联合研发的 SmallThinker 系列模型,是一组专为设备端部署设计的原生混合专家(MoE)语言模型。其核心目标是在资...大语言模型# SmallThinker# 上海交通大学9个月前03710
中国科学院发布“磐石”操作系统与 S1-Base 科学大模型:开启“AI for Science”新范式在AI加速推动科学研究变革的背景下,中国科学院正式推出 “磐石”(ScienceOne) —— 一个面向前沿科学发现与技术创新的“AI+科学”操作系统。作为其核心引擎,磐石科学基础大模型(S1-Bas...大语言模型# 中国科学院# 磐石科学基础大模型9个月前03800
上海AI实验室发布书生 Intern-S1:专为科研打造的多模态AI助手上海AI实验室正式推出 Intern-S1 —— 一款具备强大科学理解能力的开源多模态推理模型。它不仅在通用任务上表现卓越,更在化学、生物、数学、物理等多个科学领域达到最先进的性能水平,部分指标甚至超...多模态模型# Intern-S1# 上海AI实验室# 书生8个月前03590
Anzhc 开源系列 YOLO 模型:专注细粒度图像分割与分类任务在图像检测与分割领域,高质量的专用模型往往能显著提升下游任务的表现。开发者 Anzhc 基于自建标注数据集,训练并开源了一系列面向特定视觉任务的 YOLO 模型,涵盖面部、眼部、头部、胸部等细粒度目标...图像模型# YOLO 模型# 图像分割9个月前06380
腾讯开源3D世界生成模型HunyuanWorld 1.0:从文本或图像生成可漫游、可交互的三维世界如何让一段文字或一张图片,自动生成一个可以自由探索、具备空间一致性且支持后续编辑的三维场景?这是计算机视觉与图形学长期追求的目标。 当前主流方法面临两难: 基于视频或多视角图像生成的方法,虽然能产出视...3D模型# 3D世界生成模型# HunyuanWorld 1.0# 腾讯9个月前01910
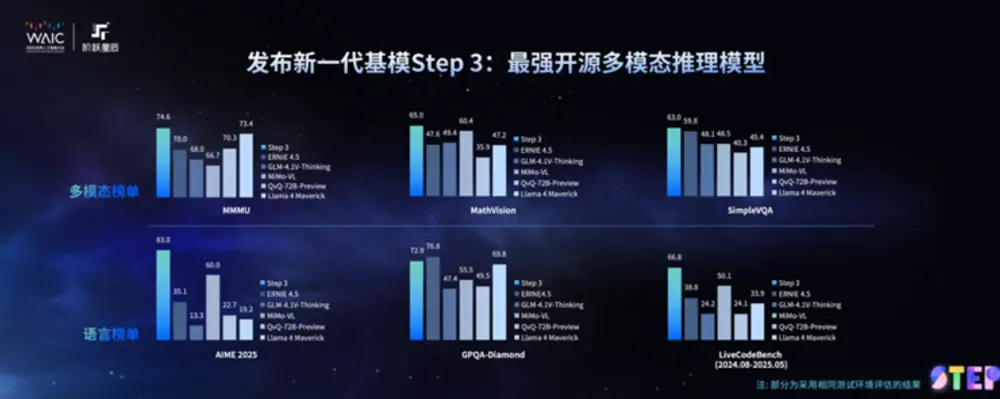
阶跃星辰发布 Step 3:开源最强多模态推理模型,推动“模芯”生态共建在2025世界人工智能大会(WAIC)开幕前夕,中国大模型企业阶跃星辰于今日在上海正式发布其新一代基础大模型——Step 3。该模型定位为“推理时代最适合应用的基座模型”,将于7月31日面向全球开源...大语言模型# Step 3# 多模态推理模型# 阶跃星辰8个月前01490
阿里Qwen团队发布 Qwen3-235B-A22B-Thinking-2507:深度推理能力再升级在持续三个月的优化后,阿里Qwen团队正式推出 Qwen3-235B-A22B-Thinking-2507 版本。该模型在逻辑推理、数学、科学、编程及学术任务上的表现显著提升,进一步巩固了其在开源思维...大语言模型# Qwen3-235B-A22B-Thinking-2507# 推理模型9个月前03500
蚂蚁集团发布Ming-lite-omni v1.5:全模态能力的全面升级由 蚂蚁集团旗下的 百灵大模型(Ling)团队研发的全模态大模型 Ming-lite-omni v1.5 正式发布。作为对初代模型的全面升级,v1.5 版本在图像、文本、视频、语音等多种模态的理解与生...多模态模型# Ming-lite-omni v1.5# 蚂蚁集团9个月前03270
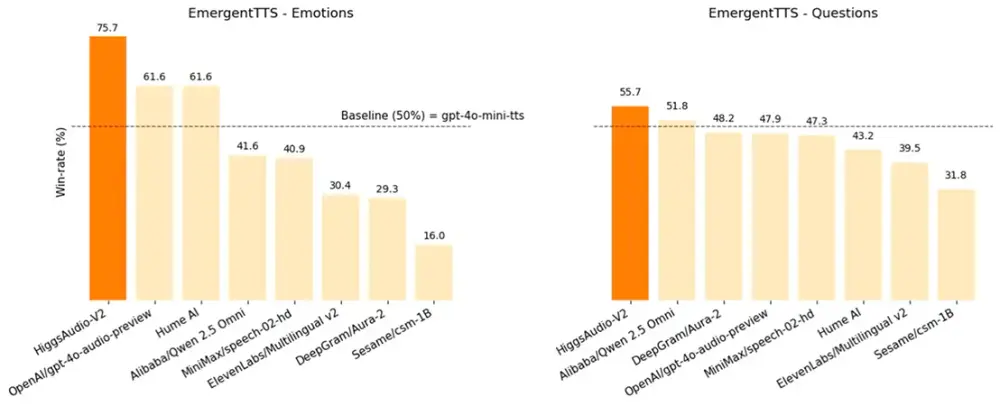
Boson AI 发布 Higgs Audio V2:首个开源的多说话者情感语音生成模型Boson AI 正式推出 Higgs Audio Generation 版本2(Higgs Audio V2),这是Boson AI在音频生成领域的一次重要突破。该模型具备强大的多说话者对话生成能力...语音模型# Boson AI# Higgs Audio V29个月前03250
阿里通义千问推出机器翻译模型Qwen-MT:92种语言互译,打造高效智能翻译新体验阿里通义千问团队近日通过Qwen API平台正式发布机器翻译模型Qwen-MT的最新升级版本——qwen-mt-turbo。该模型基于强大的Qwen3架构,结合超大规模多语言翻译数据与强化学习技术,在...大语言模型# Qwen-MT# 翻译模型9个月前05850
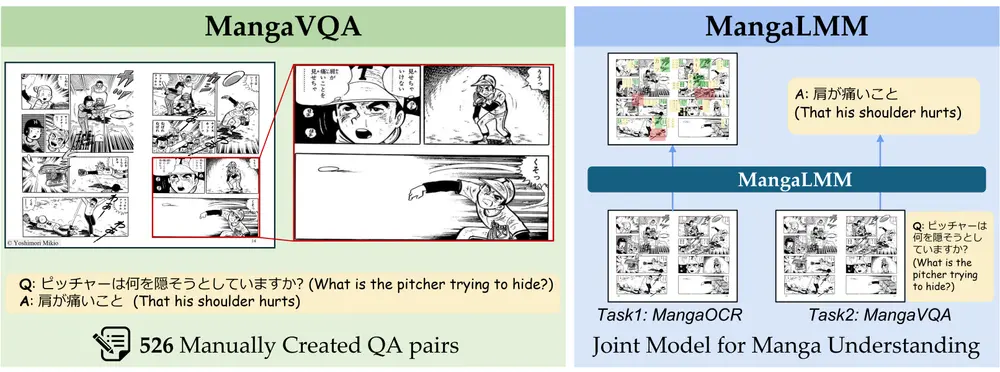
东京大学推出基准测试MangaVQA和多模态漫画理解模型MangaLMM东京大学的研究人员推出一个名为 MangaVQA 的基准测试和一个名为 MangaLMM 的专门模型,用于多模态漫画理解。漫画(Manga)是一种将图像和文本以复杂方式结合的叙事形式,理解漫画需要同时...多模态模型# MangaLMM# MangaVQA# 东京大学9个月前01690
Ultra3D:一种高效且高保真的稀疏体素3D生成框架在生成式 AI 向三维空间延伸的进程中,高质量、高分辨率的3D内容生成已成为核心挑战。尽管基于稀疏体素的方法在几何细节建模方面表现出色,但其普遍采用的双阶段扩散架构常因注意力机制的二次计算复杂度而面临...3D模型# 3D生成框架# Ultra3D9个月前06590