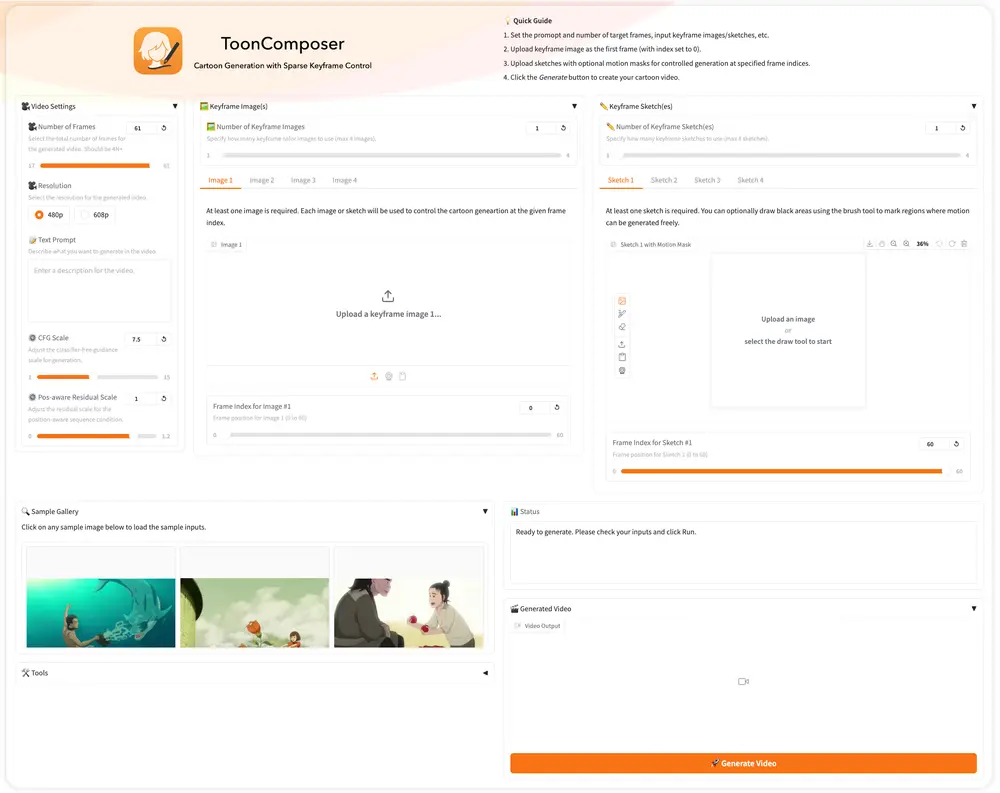
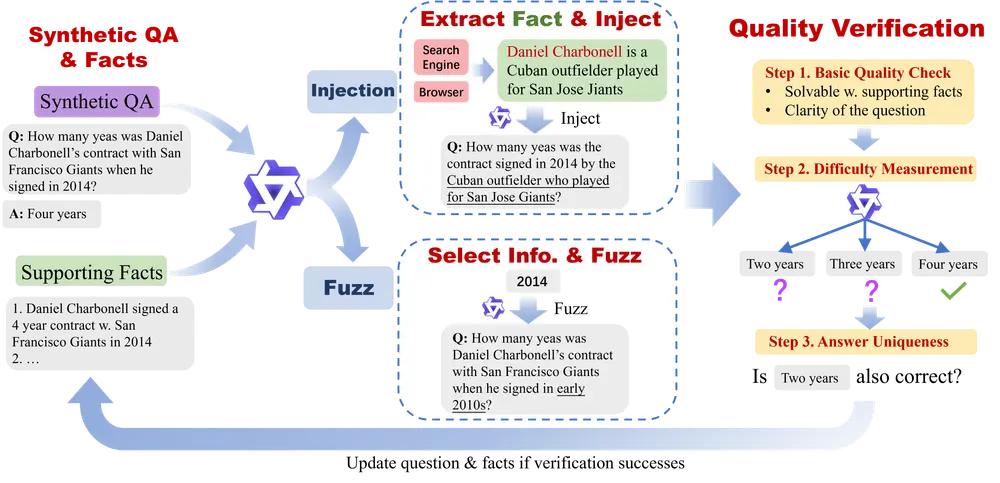
ToonComposer:通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程香港中文大学、腾讯PCG ARC Lab和北京大学的研究人员推出 ToonComposer ,通过生成式后关键帧(post-keyframing)阶段简化卡通制作流程。传统的卡通和动画制作涉及关键帧绘...视频模型# ToonComposer# 卡通制作4个月前09660
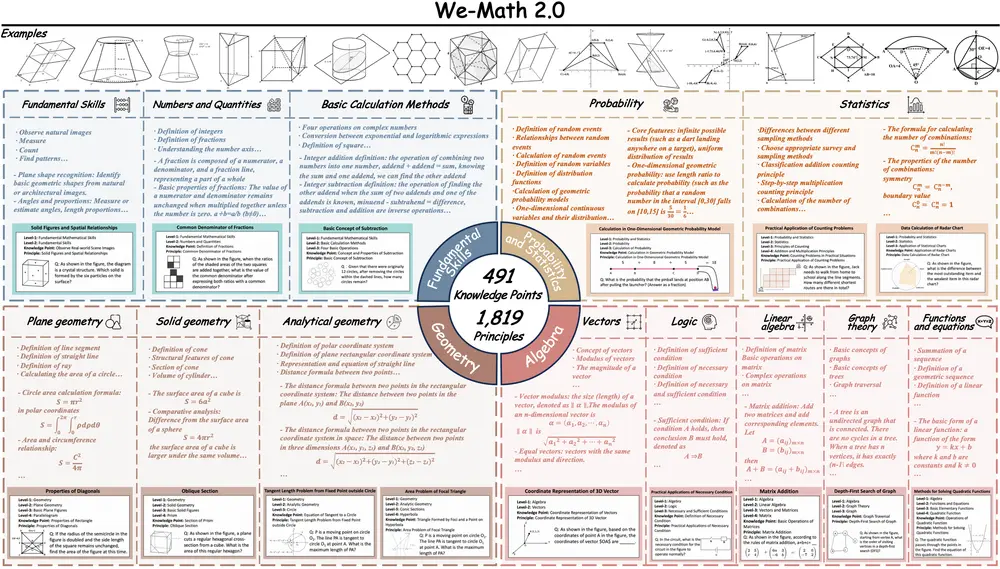
北邮、清华、腾讯联合推出 We-Math 2.0:构建有“知识体系”的数学推理智能体在当前多模态大模型(MLLM)普遍依赖数据驱动“试错式”解题的背景下,北京邮电大学、清华大学与腾讯的研究团队提出了一条不同的技术路径:让模型真正理解数学。 他们联合发布了 We-Math 2.0 ...多模态模型# We-Math 2.0# 数学推理智能体4个月前04700
字节跳动推出具备长期记忆的多模态智能体 M3-Agent字节跳动 Seed 团队推出新型多模态智能体框架M3-Agent ,首次实现了以实体为中心、支持长期记忆积累的自主推理能力。 项目主页:https://m3-agent.github.io GitHu...多模态模型# M3-Agent# 多模态智能体# 字节跳动4个月前02270
阶跃星辰发布 NextStep-1:140 亿参数自回归模型,用“连续令牌”重塑图像生成在图像生成领域,自回归模型长期被视作“文本专家,视觉弱项”——它们擅长逐词生成语言,却难以像扩散模型那样精细构建图像。而如今,阶跃星辰(StepFun)正试图打破这一边界。 GitHub:https...图像模型# NextStep-1# 图像生成# 图像编辑4个月前04900
谷歌发布 Gemma 3 270M:专为微调而生的超高效小模型在开源大模型领域持续发力的谷歌,近日为其 Gemma 模型家族再添新成员——Gemma 3 270M。这是一款拥有 2.7 亿参数的紧凑型模型,专为特定任务微调设计,旨在为开发者提供一个高效、节能、生...大语言模型# Gemma 3 270M# 小模型# 谷歌4个月前03560
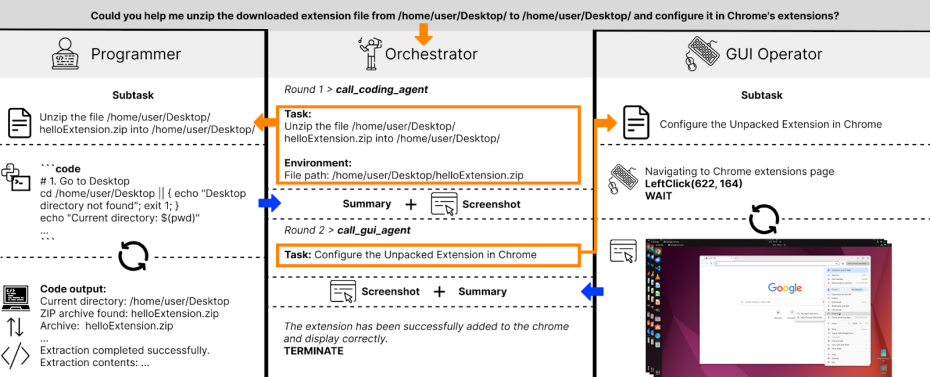
Salesforce 推出 CoAct-1:能写代码的智能体,让自动化迈入新阶段在AI智能体普遍还在“点击屏幕”完成任务的今天,Salesforce 与南加州大学联合研发的 CoAct-1 正在打破这一局限。这款新型计算机操作智能体不仅能识别界面、模拟鼠标点击,更能在任务执行过程...大语言模型# CoAct-1# 智能体4个月前01480
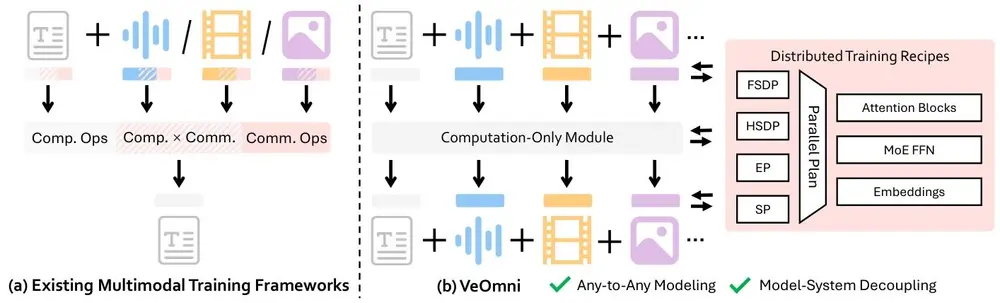
字节跳动开源 VeOmni:一个面向全模态大模型的 PyTorch 原生训练框架在大模型从“能说”向“能看、能听、能理解”演进的当下,多模态统一模型(Omni-Modal LLMs)正成为技术前沿。然而,训练一个同时处理文本、图像、语音和视频的全能模型,仍面临工程复杂、扩展困难...多模态模型# VeOmni# 多模态统一模型# 字节跳动4个月前01820
Pattern Diffusion:专为无缝图案生成而生的扩散模型由开发者 Alex Reid 推出的 Pattern Diffusion,是一个专为生成可平铺(tiling)表面图案而从零训练的扩散模型。它基于 Stable Diffusion 2-Base 架构...图像模型# Pattern Diffusion# 无缝图案4个月前02400
天工AI发布 UniPic-2.0:轻量高效、统一多模态图像生成与编辑新范式天工AI正式推出 UniPic-2.0 系列模型,基于 SD3.5-Medium 架构与创新训练策略,在文本到图像生成、细粒度图像编辑和多模态理解任务中实现全面性能突破。 GitHub:https...图像模型# UniPic-2.0# 天工AI4个月前02790
清华、蚂蚁等联合发布ASearcher:开源大规模强化学习搜索代理由清华大学交叉信息研究院、蚂蚁研究院、强化学习实验室与华盛顿大学的研究团队联合推出 ASearcher —— 一个面向大规模在线强化学习(Reinforcement Learning, RL)的开源搜...大语言模型# ASearcher# inclusionAI4个月前02380
视频处理引擎ViPE:用于从普通视频中估计相机运动、相机内参以及密集的度量深度图英伟达、多伦多大学、矢量研究所和德克萨斯大学奥斯汀分校的研究人员推出视频处理引擎ViPE(Video Pose Engine) ,用于从普通视频中估计相机运动、相机内参以及密集的度量深度图,能够从普通...视频模型# ViPE# 视频处理引擎4个月前02390
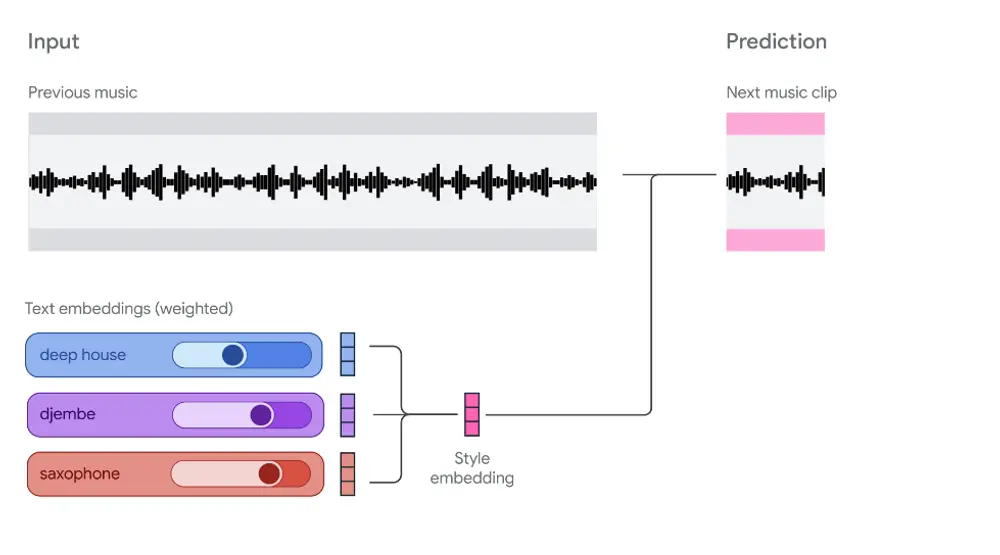
Magenta RealTime:一个可交互、可定制的开源实时音乐生成模型当 AI 生成音乐从“预设播放”走向“实时演奏”,我们正在见证创作方式的一次深刻转变。 传统的音乐生成模型通常以“批处理”模式运行:输入一段提示,等待几秒后输出完整音频。这种模式虽能产出完整作品,却缺...语音模型# Magenta RealTime# 实时音乐生成模型4个月前01810