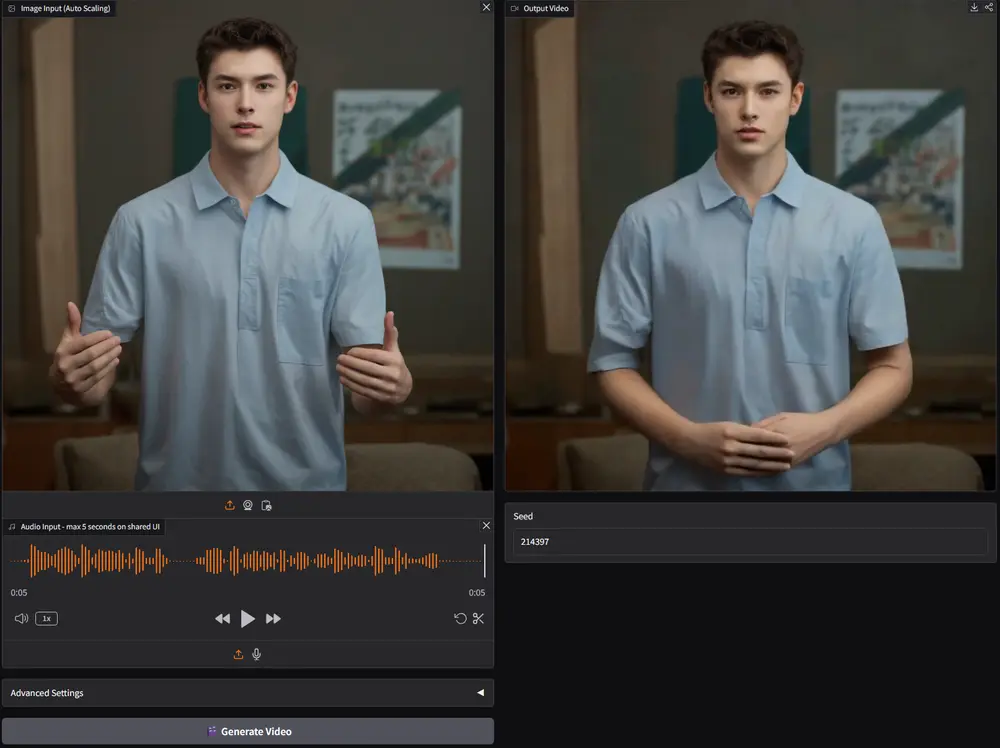
半身人体动画生成框架 EchoMimicV2:利用参考图像、音频剪辑和一系列手部姿势来生成高质量的动画视频随着计算机图形学和人工智能的发展,生成高质量的人类动画变得越来越重要。特别是,当涉及到创建生动、自然的动画时,音频、姿势或运动图等条件的引入大大提升了动画的真实性和表现力。然而,这些增强的方法也带来了...视频模型# EchoMimicV2# 动画生成12个月前04740
Anzhc 开源系列 YOLO 模型:专注细粒度图像分割与分类任务在图像检测与分割领域,高质量的专用模型往往能显著提升下游任务的表现。开发者 Anzhc 基于自建标注数据集,训练并开源了一系列面向特定视觉任务的 YOLO 模型,涵盖面部、眼部、头部、胸部等细粒度目标...图像模型# YOLO 模型# 图像分割6个月前04690
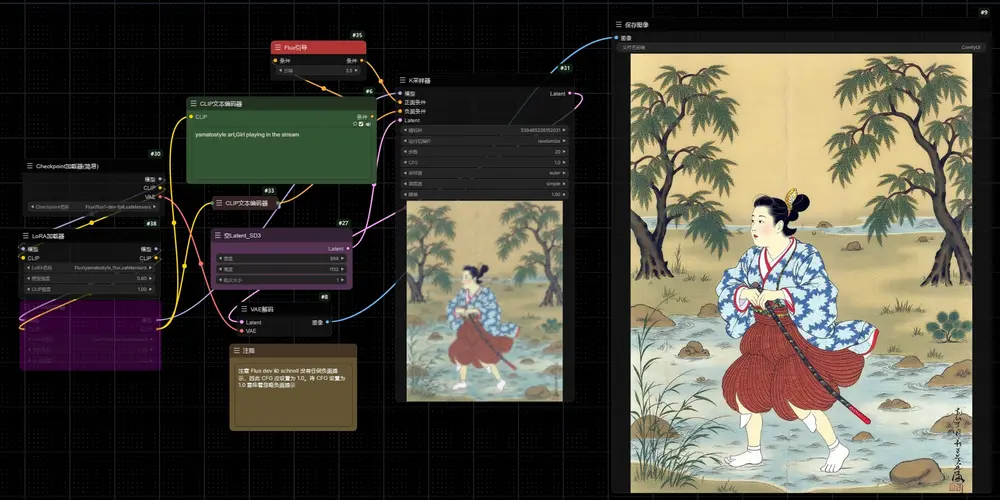
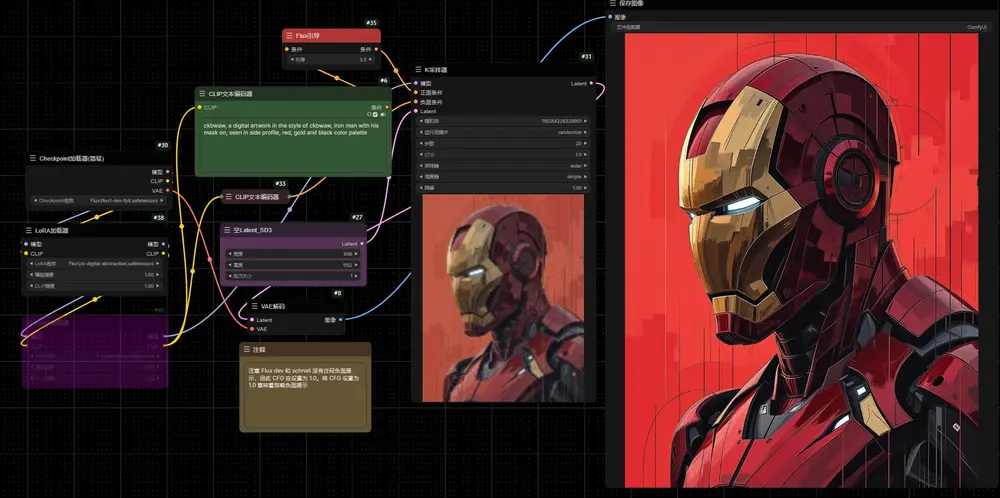
Yamato-e style:基于FLUX.1-dev的日本浮世绘风格LoRAYamato-e style是一款基于FLUX.1-dev的日本浮世绘风格LoRA,适合生成风景图,当你描述角色和背景场景时,它效果最好。 模型:https://civitai.com/models...Flux衍生# FLUX.1-dev# Lora# Yamato-e style12个月前04690
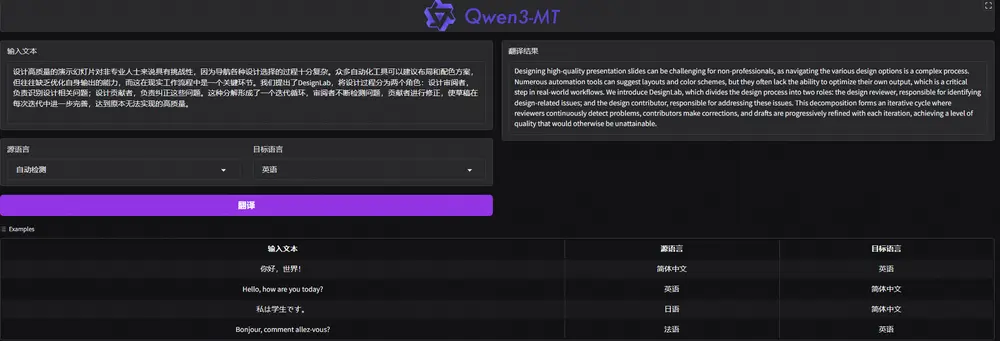
阿里通义千问推出机器翻译模型Qwen-MT:92种语言互译,打造高效智能翻译新体验阿里通义千问团队近日通过Qwen API平台正式发布机器翻译模型Qwen-MT的最新升级版本——qwen-mt-turbo。该模型基于强大的Qwen3架构,结合超大规模多语言翻译数据与强化学习技术,在...大语言模型# Qwen-MT# 翻译模型6个月前04670
字节跳动与浙大联合发布轻量高效TTS模型MegaTTS3字节跳动和浙江大学的研究人员推出的一款轻量级TTS模型:MegaTTS3,0.45B,高质量语音克隆,支持中英文以及中英文混合,支持口音强度控制,后面会支持更细粒度的发音和时长调整。 GitHub:h...语音模型# MegaTTS3# TTS模型# 字节跳动10个月前04670
字节跳动推出基于修正流Transformer 架构的新型图像和视频生成模型家族Goku香港大学和字节跳动的研究人员推出新型图像和视频生成模型家族Goku,它基于修正流Transformer 架构,实现了行业领先的图像和视频联合生成性能。Goku 的目标是通过高质量的视觉内容生成,推动媒...视频模型# Goku# 字节跳动# 视频生成12个月前04670
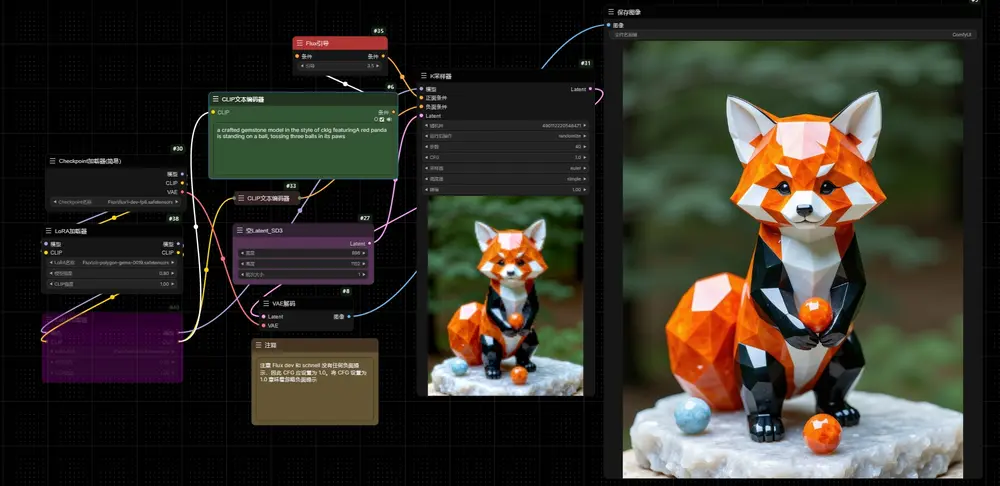
Gemstone Crafter:宝石风格的FLUX.1-dev LoRAGemstone Crafter是一个宝石风格的FLUX.1-dev LoRA,与之前介绍的Digital Abstraction是一个作者。 地址:https://civitai.com/model...Flux衍生# FLUX.1-dev# Gemstone Crafter# Lora12个月前04640
StableAvatar:首个端到端生成无限长度虚拟人视频的扩散模型你是否曾想过,仅凭一张静态照片和一段语音,就能让照片中的人物“开口说话”,并持续数分钟自然表达?这正是音频驱动虚拟人视频生成(Audio-Driven Talking Head Generation...视频模型# StableAvatar# 虚拟人6个月前04630
Stability AI推出其最新的图像生成模型系列Stable Diffusion 3.5(SD3.5):更具可定制性和多功能性,同时在性能上也有所提升在经历了一系列由技术故障和许可变更引发的争议后,Stability AI宣布了其最新的图像生成模型系列—Stable Diffusion 3.5(SD3.5),新的Stable Diffusion 3...图像模型# SD3.5# Stability AI# Stable Diffusion 3.512个月前04630
Digital Abstraction:FLUX.1-dev的数字风格LoRADigital Abstraction是一款受到SD3.5生成图像启发而制作的FLUX.1-dev的数字风格LoRA。 地址:https://civitai.com/models/891762/dig...Flux衍生# FLUX.1-dev# 数字风格12个月前04620
腾讯微信视觉团队发布 Stand-In:轻量级身份保持视频生成新框架在文本到视频(T2V)生成领域,一个长期存在的难题是:如何让生成的视频中的人物始终“长成你想要的样子”? 尽管现有模型能生成流畅、高质量的视频,但在身份一致性(identity-preserving...视频模型# Stand-In# 视频生成框架5个月前04600
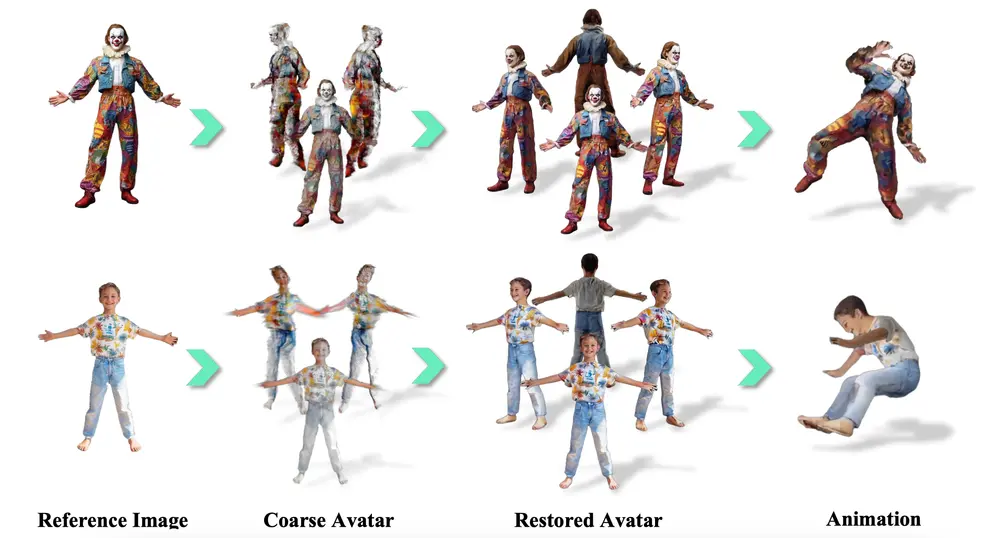
新型框架HumanDreamer-X:用于从单张图像重建逼真的可动画化三维人类虚拟形象(avatar)GigaAI、中国科学院自动化研究所和北京大学的研究人员推出新型框架HumanDreamer-X,用于从单张图像重建逼真的可动画化三维人类虚拟形象(avatar)。该框架通过结合三维重建和视频修复技术...3D模型# HumanDreamer-X# 虚拟形象10个月前04590