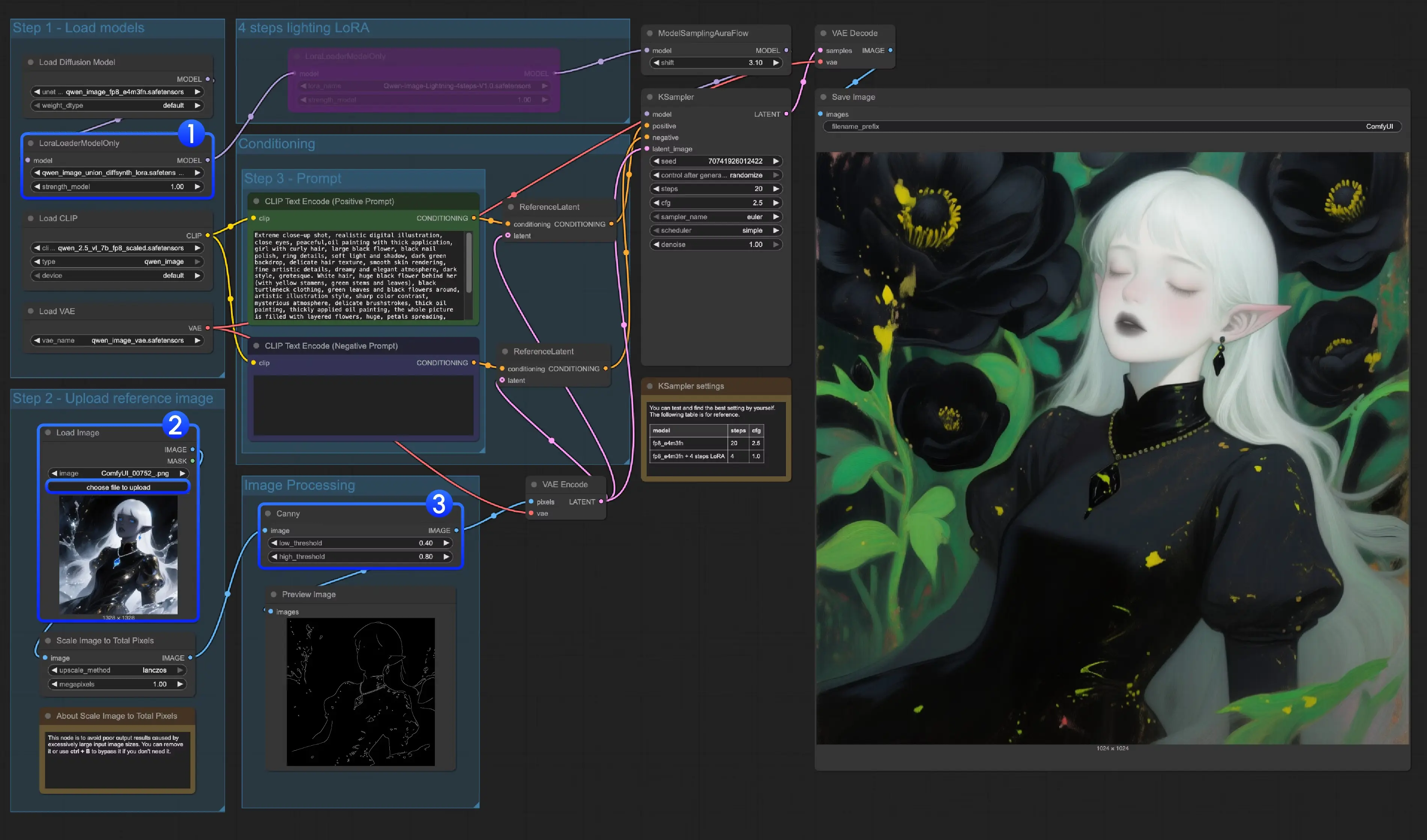
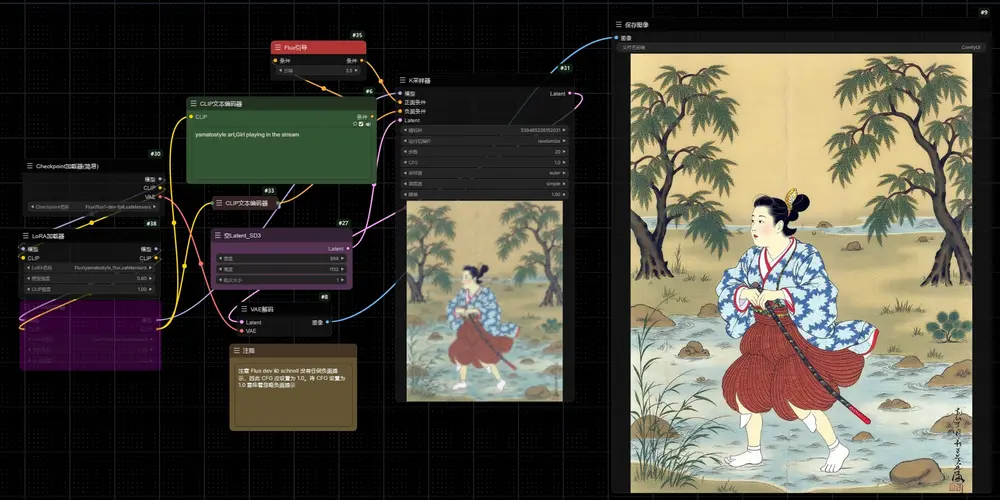
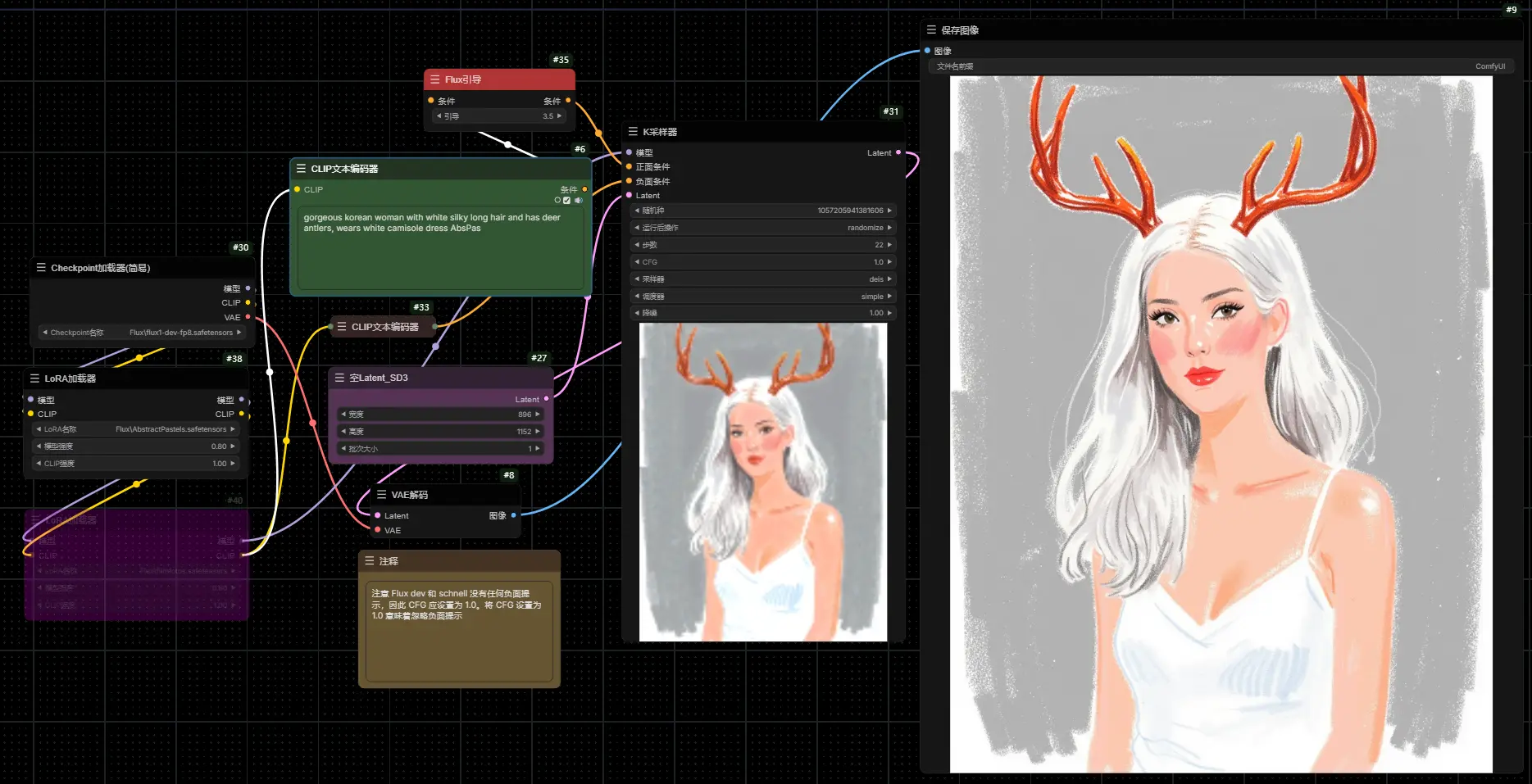
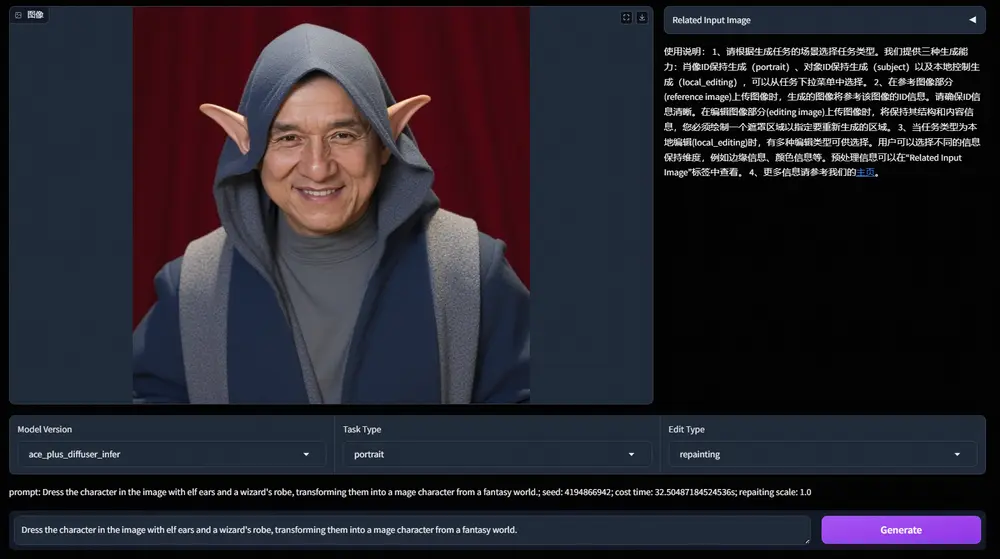
Stable Diffusion 原班人马新公司Black Forest Labs推出全新文生图模型Flux.1系列Flux衍生# Flux.1# Flux.1系列# Stable Diffusion1年前06540