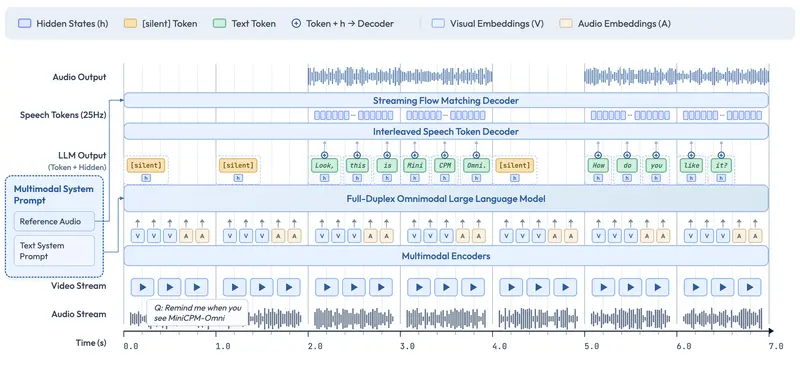
面壁智能发布MiniCPM-o 4.5:9B参数端侧全双工多模态大模型,对标Gemini 2.5 Flash面壁智能正式推出MiniCPM-o系列最新旗舰模型——MiniCPM-o 4.5。这款总参数量仅9B的端侧多模态大模型(MLLM),基于SigLip2、Whisper-medium、CosyVoice...多模态模型# MiniCPM-o 4.5# 面壁智能2个月前0740
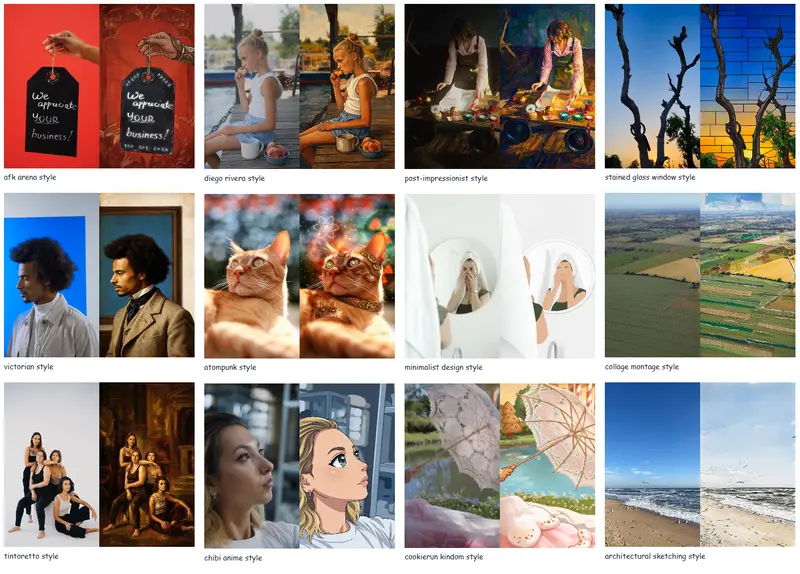
电信AI研究院提出TeleStyle:DiT架构下实现图像/视频内容保持式风格迁移SOTA中国电信人工智能研究院(TeleAI)提出TeleStyle——一款轻量级且高效的图像与视频内容保持式风格迁移模型,核心基于Qwen-Image-Edit构建,针对性解决了扩散变换器(DiT)架构中内...图像模型# TeleStyle# 风格迁移2个月前0600
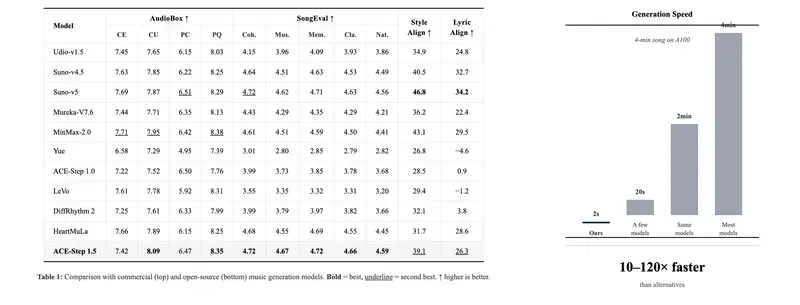
ACE Studio×阶跃星辰推出ACE-Step v1.5:混合架构开源音乐模型,商用就绪且50+语言适配ACE Studio联合阶跃星辰(StepFun)重磅发布ACE-Step v1.5,这是一款专为消费级硬件打造的高效开源音乐基础模型,首次将商业级音乐生成能力下沉到普通硬件环境。该模型不仅在核心评估...语音模型# ACE Studio# ACE-Step v1.5# 阶跃星辰2个月前01010
InteractAvatar:文本驱动的可控说话化身框架,实现高保真场景化人-物交互清华大学联合腾讯混元项目组研发的InteractAvatar,是一款创新的双流DiT(扩散变换器)框架,首次让说话虚拟化身突破简单手势局限,实现基于静态场景的文本驱动可控人-物交互。该模型能从参考图像...视频模型# InteractAvatar# 数字人2个月前0590
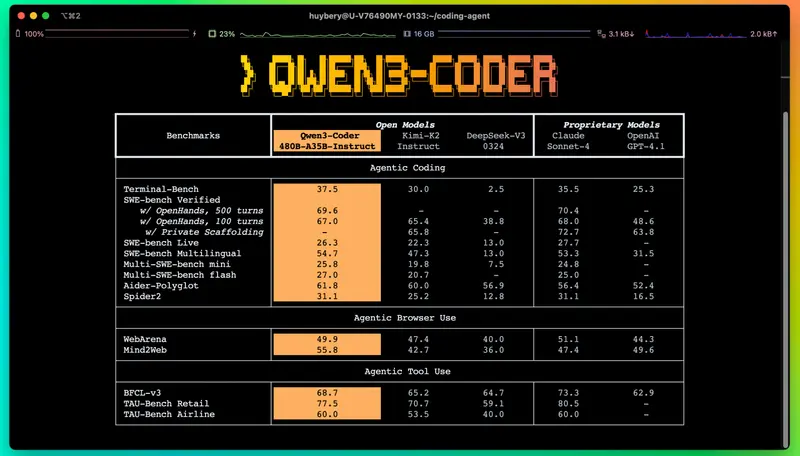
阿里Qwen3-Coder重磅发布:480B MoE模型拿下开源Agent编程SOTA,媲美Claude Sonnet4阿里Qwen项目组正式推出Qwen3-Coder系列代码模型,这是其迄今代理能力最强的代码模型版本,其中旗舰款Qwen3-Coder-480B-A35B-Instruct更是拉满配置——总参数量480...大语言模型# Claude Sonnet4# Qwen3-Coder# 阿里2个月前04200
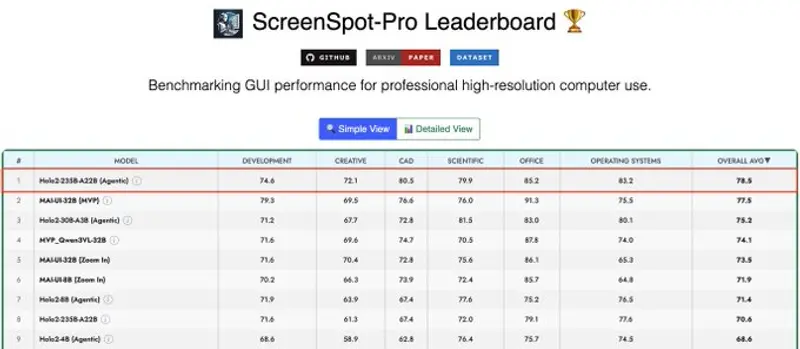
两个月再升级!HCompany推出2350亿参数Holo2-235B-A22B,刷新UI定位模型基准距离首款Holo2模型发布仅两个月,HCompany便推出迄今最大规模的UI定位模型Holo2-235B-A22B Preview,一举在ScreenSpot-Pro基准测试中创下78.5%的新纪录...多模态模型# HCompany# Holo2# Holo2-235B-A22B2个月前0420
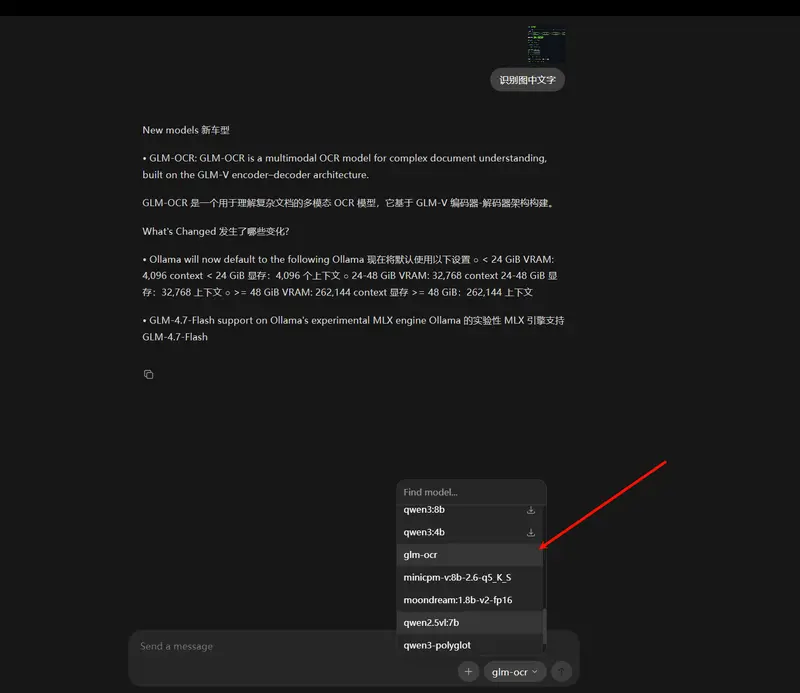
智谱AI开源GLM-OCR:0.9B参数拿下榜单第一,支持vLLM部署,一行命令就能用智谱AI又放出一款实用开源模型——GLM-OCR,这是一款专为复杂文档理解打造的多模态OCR模型,不仅在权威基准测试中拿下综合第一,还做到了轻量高效、易部署,关键是完全开源,个人和企业都能免费使用。 ...多模态模型# GLM-OCR# 智谱AI2个月前02780
Apache 2.0 许可!Photoroom 推出轻量级 13 亿参数开源文生图模型 PRXPhotoroom 团队正式发布了其首个开源文生图模型 PRX (Photoroom Experimental)。这是一个拥有 13 亿参数、完全从头开始训练 的扩散变换器模型,并以宽松的 Apach...图像模型# Photoroom# PRX2个月前0380
阶跃星辰推出Step 3.5 Flash:196B MoE 开源旗舰,推理与智能体性能对标闭源顶级模型Step 3.5 Flash 是阶跃星辰推出的开源旗舰语言推理模型,定位为当前最强大的开源基座之一,专为极致效率、深度推理、智能体(Agent)执行而生。 GitHub:https://github...大语言模型# Step 3.5 Flash# 阶跃星辰2个月前0700
优必选开源具身智能大模型Thinker:小参数、高性能,专为工业人形机器人打造过去一年,人形机器人在实验室环境中的“场景理解”与“任务规划”能力突飞猛进。然而,一旦进入真实的工业产线,它们便常常陷入“想得到但抓不准、算得出但跟不上”的困境。这背后,是长期存在的鸿沟:空间层面的度...多模态模型# Thinker# 优必选# 具身智能大模型2个月前0560
商汤开源 SenseNova-MARS:多模态自主推理模型登顶 MMSearch 榜单商汤科技正式开源 SenseNova-MARS —— 一款支持动态视觉推理与图文搜索深度融合的多模态大模型(VLM)。该模型提供 8B 与 32B 双版本,在多模态搜索与推理核心基准 MMSearch...多模态模型# SenseNova-MARS# 商汤2个月前0810
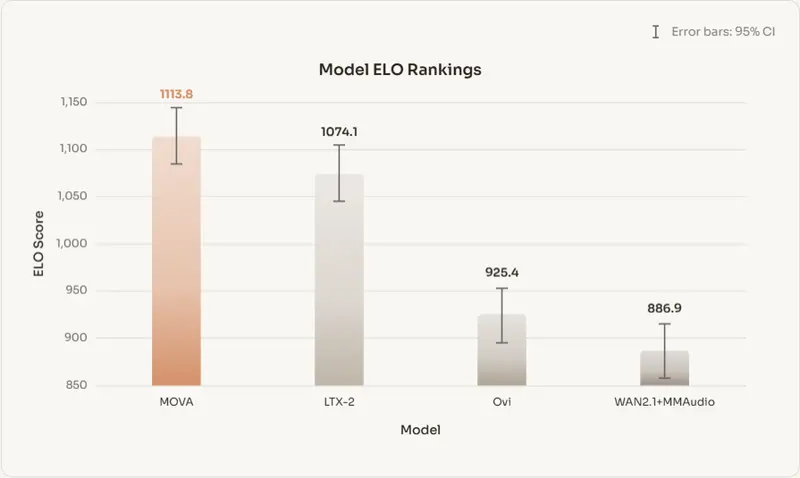
模思智能推出 MOVA:开源同步音视频生成基座模型,打破“无声视频”困局模思智能正式开源 MOVA(MOSS Video and Audio)——一款专注于原生同步生成视频与音频的基座模型。针对当前主流系统(如 Sora 2、Veo 3)普遍采用的“先画后音”级联流程,M...视频模型# MOVA# 模思智能2个月前0200