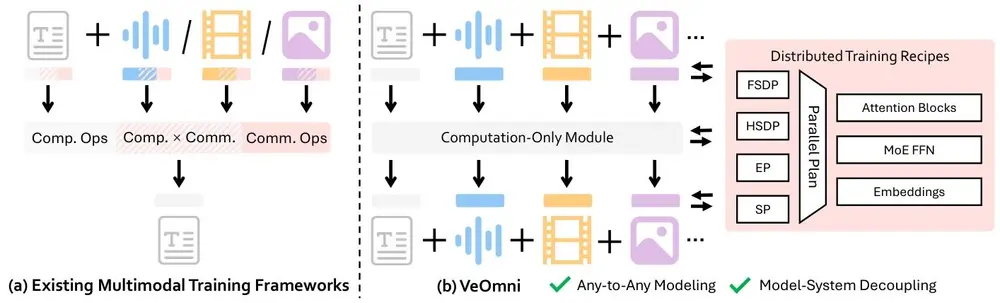
字节跳动开源 VeOmni:一个面向全模态大模型的 PyTorch 原生训练框架在大模型从“能说”向“能看、能听、能理解”演进的当下,多模态统一模型(Omni-Modal LLMs)正成为技术前沿。然而,训练一个同时处理文本、图像、语音和视频的全能模型,仍面临工程复杂、扩展困难...多模态模型# VeOmni# 多模态统一模型# 字节跳动7个月前01980
阿里通义实验室推出多模态深度研究智能体WebWatcher:通过结合视觉和语言推理能力,解决复杂的多模态信息检索问题阿里通义实验室推出多模态深度研究智能体WebWatcher,通过结合视觉和语言推理能力,解决复杂的多模态信息检索问题。 GitHub:https://github.com/Alibaba-NLP/We...多模态模型# WebWatcher# 多模态深度研究智能体7个月前03460
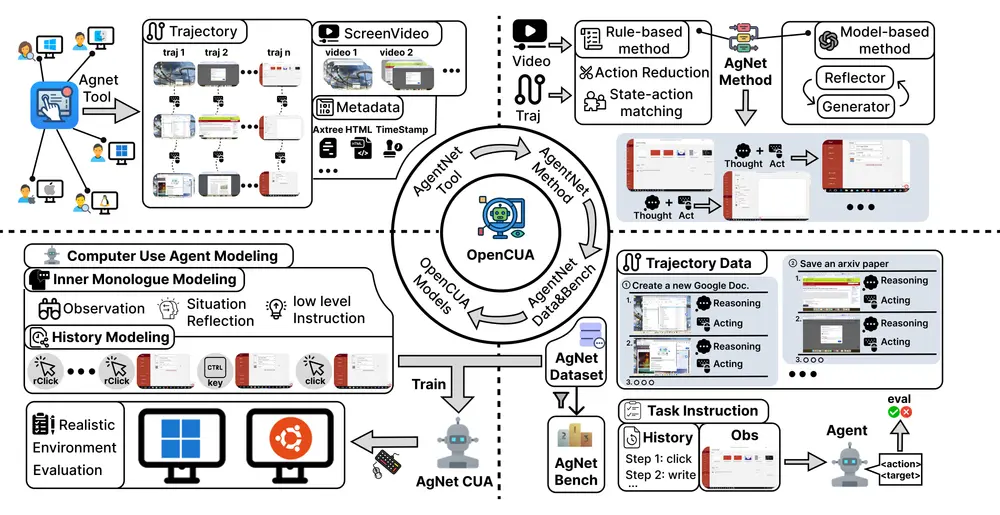
OpenCUA:首个开源的计算机使用智能体框架发布你是否曾希望有一个 AI 助手,能像你一样操作电脑——打开浏览器查资料、在 Excel 中整理数据、切换应用完成多步骤任务?如今,这类被称为“计算机使用智能体”(Computer Use Agents...多模态模型# OpenCUA# 智能体框架7个月前09450
LFM2-VL:轻量高效、面向设备端的视觉-语言模型在多模态大模型不断追求更高参数量和更强性能的当下,效率与部署可行性正成为实际应用的关键瓶颈。许多视觉-语言模型(VLM)虽在基准测试中表现优异,但其高计算成本和长推理延迟,使其难以在手机、可穿戴设备或...多模态模型# LFM2-VL# 视觉-语言模型7个月前03570
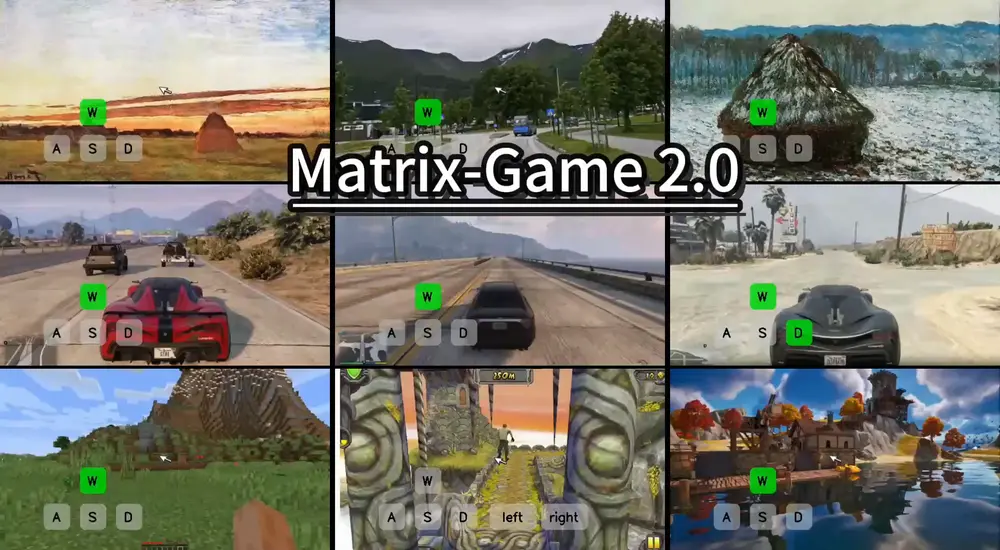
昆仑万维发布 Matrix-Game 2.0:首个开源通用交互式世界模型,把“虚拟世界”推向生产线DeepMind 最近发布的 Genie 3 让世界再次看到了“交互式世界模型”的潜力:一个模型,即可生成可玩、可控、长序列的虚拟环境。用户只需按下方向键,就能在一个由 AI 实时渲染的世界中自由探索...多模态模型# Matrix-Game 2.0# 交互式世界模型# 昆仑万维7个月前03040
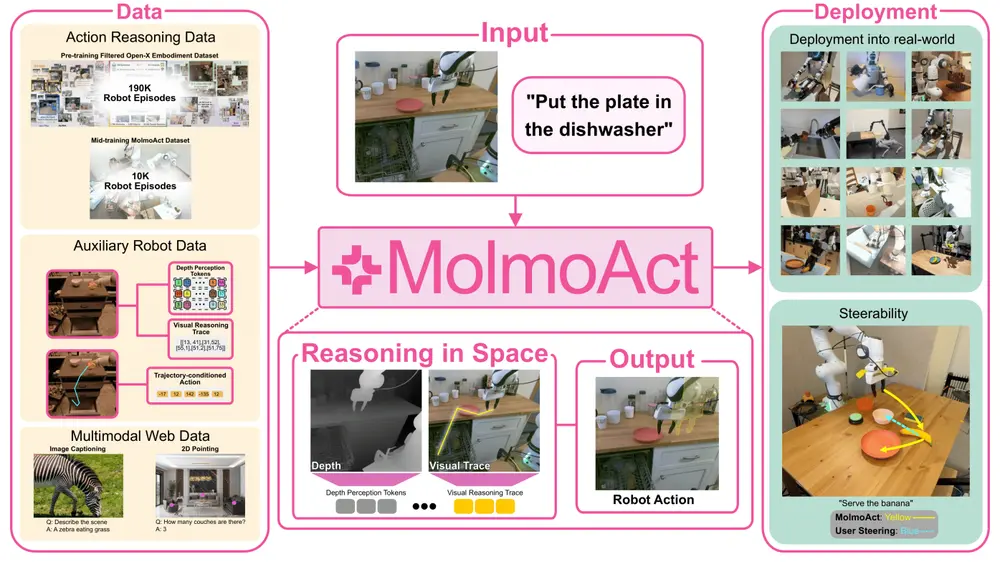
机器人行动推理模型MolmoAct:通过结构化的三阶段推理流程(感知、规划和控制)将视觉、语言和行动相结合,使机器人能够更智能地执行任务艾伦AI研究所和华盛顿大学的研究人员推出机器人行动推理模型MolmoAct ,它通过结构化的三阶段推理流程(感知、规划和控制)将视觉、语言和行动相结合,使机器人能够更智能地执行任务。MolmoAct ...多模态模型# MolmoAct# 机器人行动推理模型7个月前01810
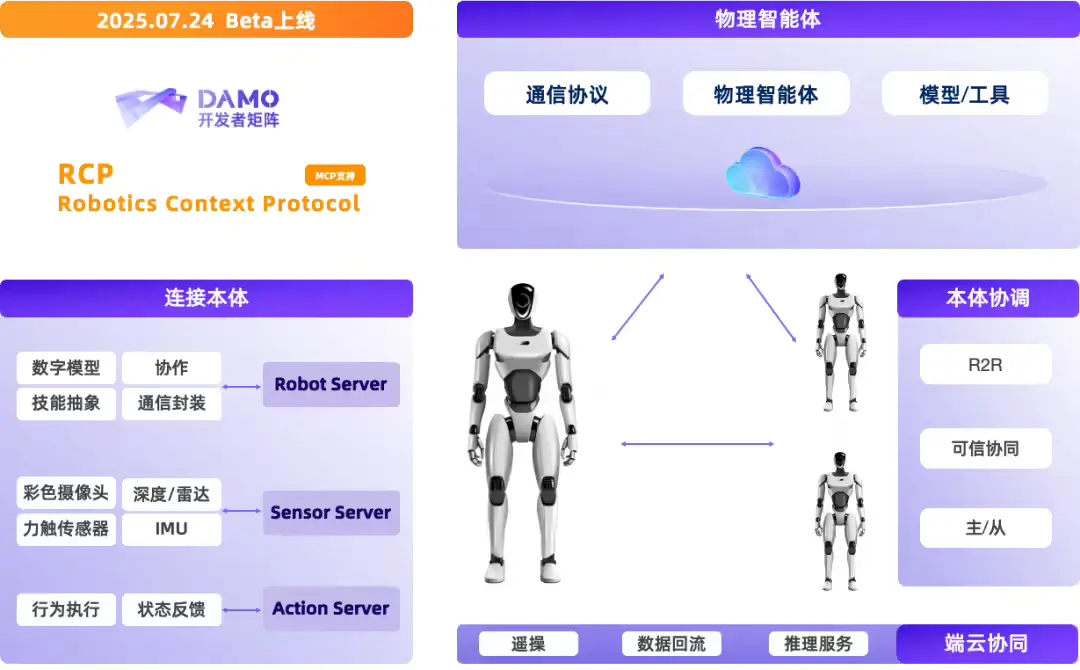
阿里达摩院开源 Rynn 系列:从协议到模型,打通具身智能“最后一公里”在上周开幕的 2025 世界机器人大会上,阿里达摩院宣布开源一套完整的具身智能技术体系,包括: 视觉-语言-动作模型 RynnVLA-001-7B 世界理解模型 RynnEC 机器人上下文协议 Ryn...多模态模型# RynnEC# RynnRCP# RynnVLA-001-7B7个月前03700
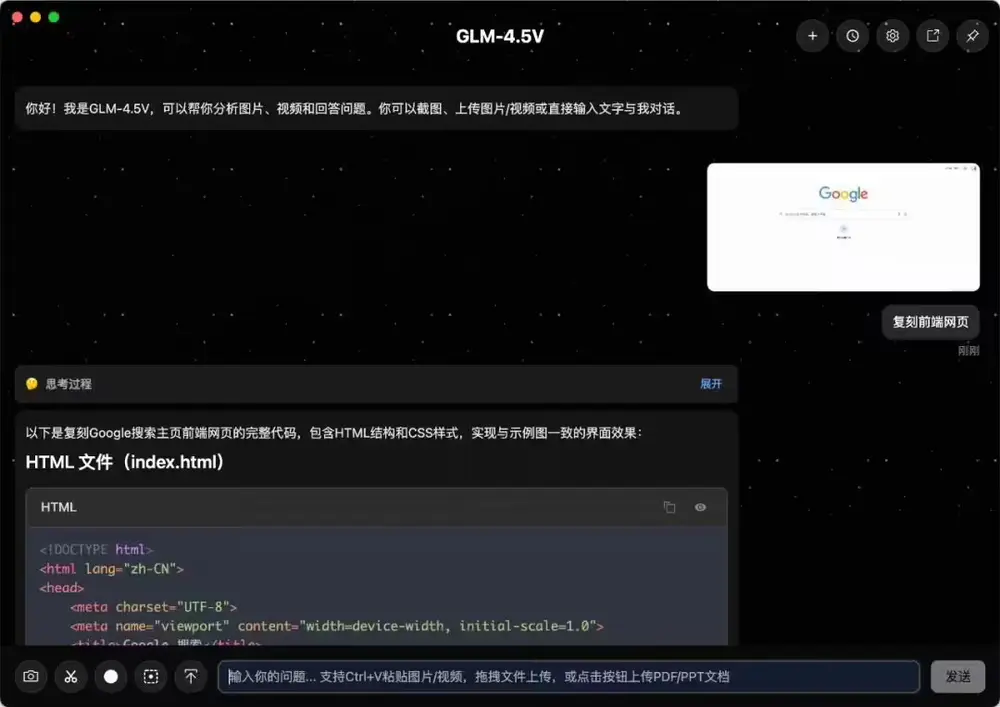
智谱AI发布GLM-4.5V:106B参数的开源视觉推理模型,支持“思考模式”切换今日,智谱 AI 正式推出其新一代开源视觉语言模型 GLM-4.5V,并在魔搭社区与 Hugging Face 同步开源。该模型总参数达 106B,采用 MOE(Mixture of Experts...多模态模型# GLM-4.5V# 智谱AI7个月前01690
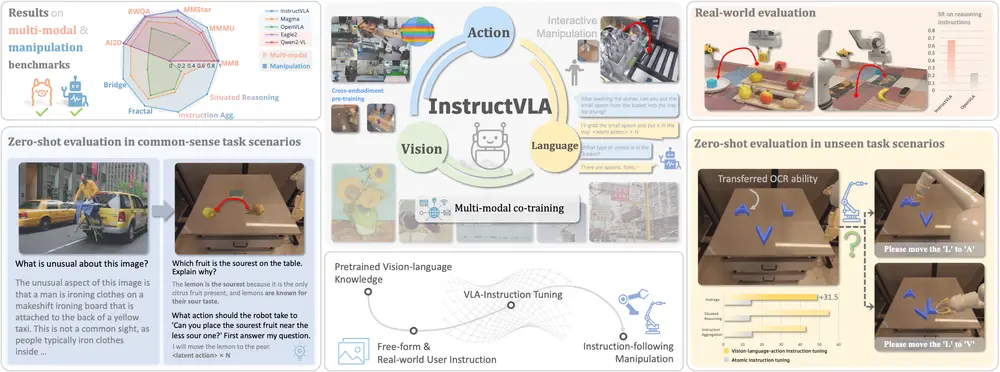
端到端的 VLA 模型InstructVLA:让机器人真正“听懂”指令并准确执行要让机器人走进真实世界,完成诸如“把苹果放进桌上的红碗”这样的任务,仅靠预设程序远远不够。它必须具备两项关键能力: 理解复杂语义——分辨“红碗”是颜色还是材质?“桌上”是否包含边缘? 生成精确动作...多模态模型# InstructVLA# VLA 模型7个月前02120
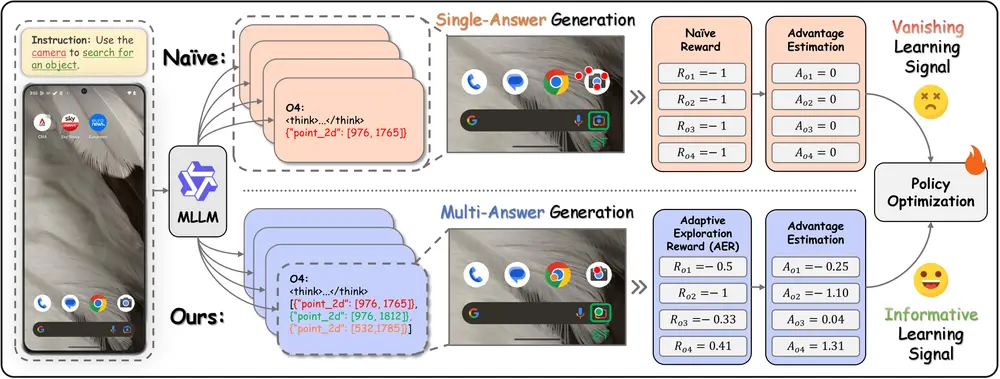
让大模型真正“看懂”界面:InfiGUI-G1提升 GUI 操作中的语义理解能力在图形用户界面(GUI)自动化任务中,让多模态大语言模型(MLLM)准确执行自然语言指令,远不只是“点击坐标”那么简单。真正的挑战在于:既要精准定位界面上的元素(空间对齐),又要正确理解指令背后的意图...多模态模型# InfiGUI-G17个月前02190
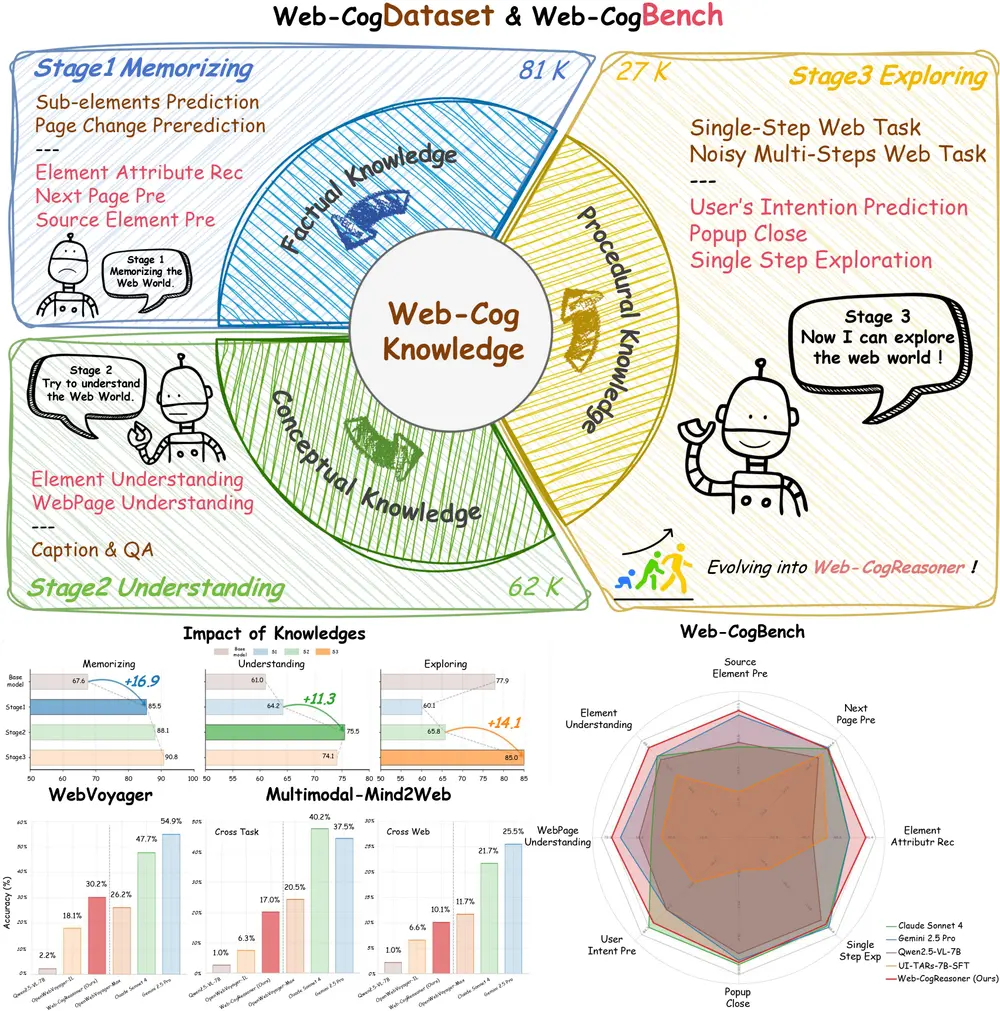
多模态智能体的“认知升级”:Web-CogReasoner 如何让网络代理真正“会思考”联合研究团队:西南财经大学、上海交通大学、中南大学、Hithink研究院、西湖大学、哈尔滨工业大学、曼彻斯特大学、加州大学洛杉矶分校、阿德莱德大学、复旦大学、中国科学院深圳先进技术研究院 当AI开始替...多模态模型# Web-CogReasoner# 多模态智能体7个月前01300
腾讯发布混元Large-Vision:支持原生分辨率输入的旗舰级多模态理解模型腾讯正式推出 混元Large-Vision —— 一款面向复杂任务的旗舰级多模态大模型。该模型在文档理解、数学推理、视频分析和三维空间感知等高难度场景中表现突出,同时具备卓越的多语言支持能力,在LMA...多模态模型# Hunyuan-Large-Vision# 混元Large-Vision# 腾讯7个月前05680