英伟达发布开源大语言模型Llama-3.1 Nemotron Ultra-253B-v1:以半数参数超越DeepSeek R1英伟达今天发布了一款全新的开源大语言模型—Llama-3.1 Nemotron Ultra-253B-v1,这款拥有2530亿参数的模型在多个基准测试中表现出色,甚至超越了竞争对手DeepSeek R...大语言模型# Llama-3.1 Nemotron Ultra# Llama-3.1 Nemotron Ultra-253B-v1# 英伟达10个月前02680
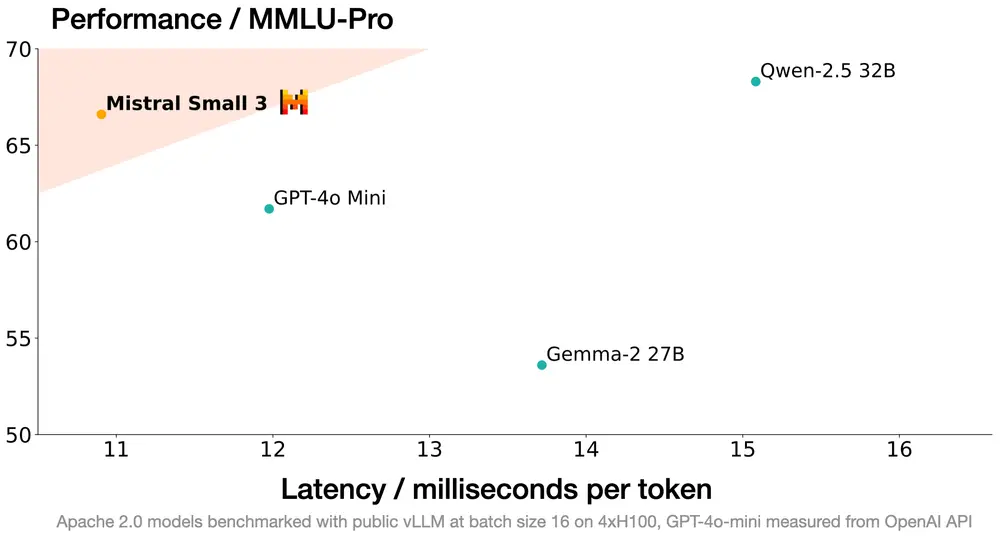
法国AI初创企业Mistral发布高效模型 Mistral Small 3:24亿参数的模型特别针对延迟进行了优化法国AI初创公司Mistral最近发布了其最新的人工智能模型——Mistral Small 3。这款拥有24亿参数的模型特别针对延迟进行了优化,并根据Apache 2.0许可证开放源代码。Mistra...大语言模型# Mistral# Mistral Small 312个月前02640
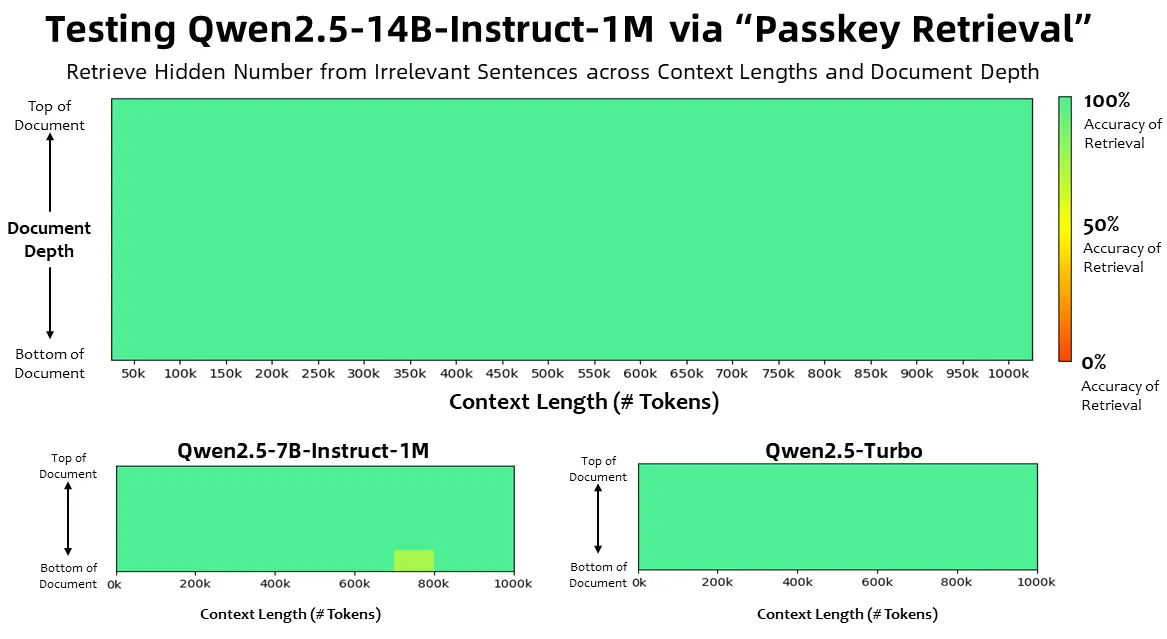
阿里通义团队推出Qwen2.5-1M:支持100万Token上下文的开源大语言模型阿里通义团队于两个月前升级了 Qwen2.5-Turbo,使其支持最多一百万个Tokens的上下文长度。1月27日,通义团队正式推出开源的 Qwen2.5-1M 模型及其对应的推理框架支持。以下是本次...大语言模型# Qwen2.5-1M12个月前02630
蚂蚁集团开源 Ring-flash-2.0:高效 MoE 架构下的高性能思考模型蚂蚁集团正式宣布开源 Ring-flash-2.0 ——一款基于 MoE(混合专家)架构的高性能“思考型”大语言模型。该模型总参数量达 100B,但在每次推理时仅激活 6.1B 参数(其中非嵌入部分约...大语言模型# Ring-flash-2.0# 蚂蚁集团4个月前02620
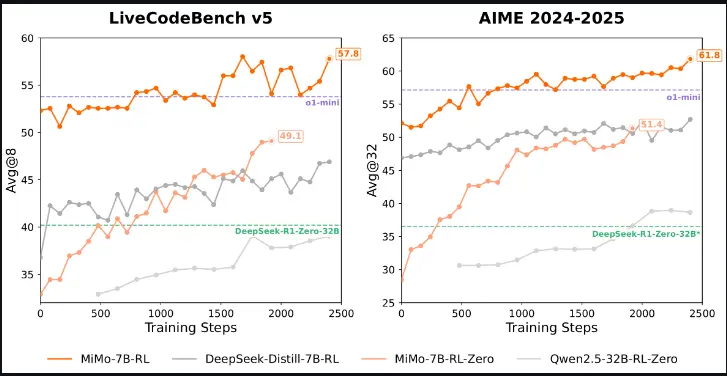
小米团队发布 MiMo-7B系列模型:专为推理任务从头开始训练的模型在强化学习(RL)领域,大型基础模型一直是研究的主流方向。目前,许多成功的强化学习项目,尤其是那些专注于代码推理能力的项目,都依赖于庞大的模型,例如拥有 320 亿参数的模型。然而,要在小型模型中同时...大语言模型# MiMo-7B# 小米9个月前02600
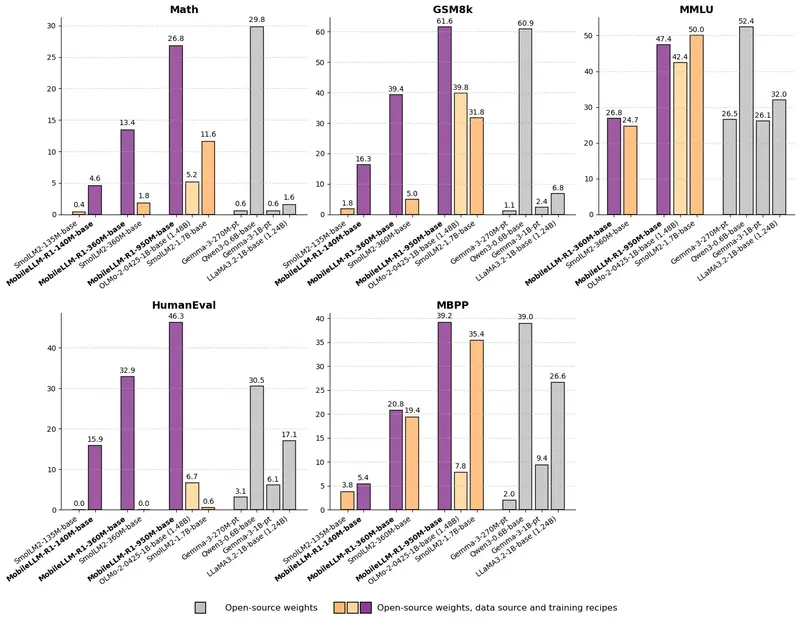
Meta 发布MobileLLM-R1 系列模型:专为数学、编程(Python/C++)和科学推理任务设计Meta 正式发布 MobileLLM-R1 系列模型,包含 140M、360M 和 950M 三款尺寸,专为数学、编程(Python/C++)和科学推理任务设计。它不是通用聊天模型,而是一个经过精细...大语言模型# Meta# MobileLLM-R15个月前02590
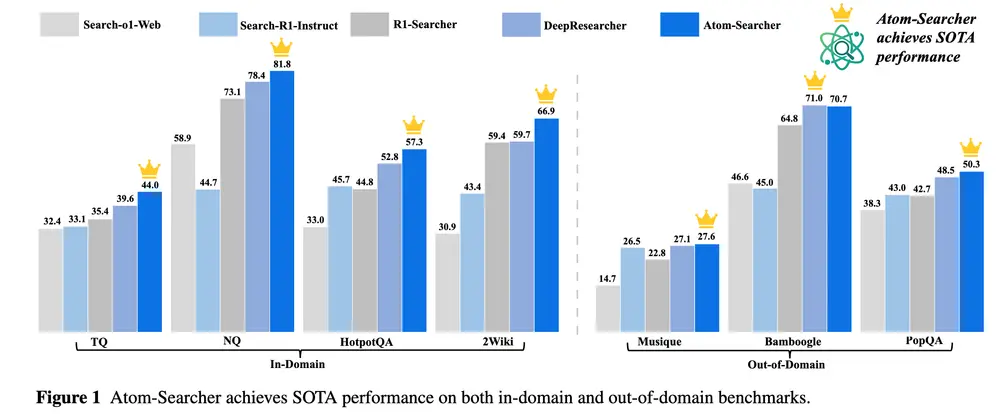
蚂蚁集团新框架Atom-Searcher:用“原子化思想”破解LLMs深度研究难题大语言模型(LLM)在开放域问答、信息检索等任务中展现出强大潜力。然而,面对需要多步骤推理、工具调用和外部验证的复杂任务,仅靠模型的静态知识和简单提示工程往往力不从心。 现有方法如检索增强生成(RAG...大语言模型# Atom-Searcher# 蚂蚁集团5个月前02550
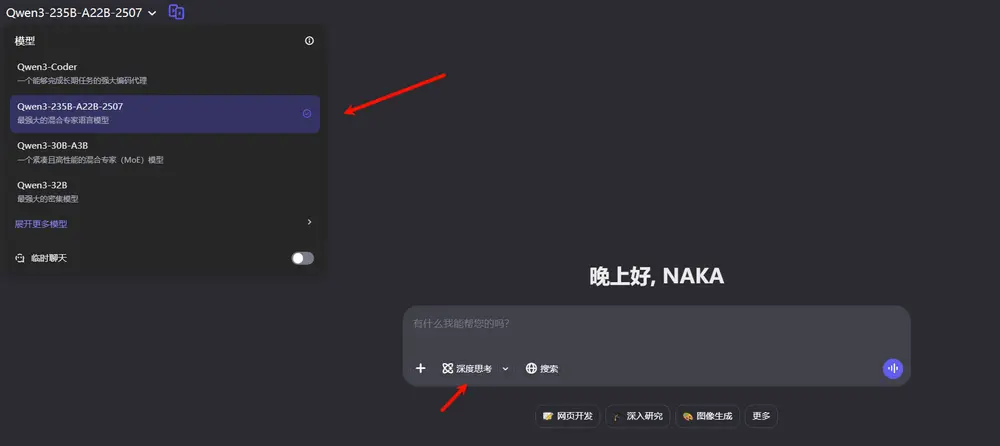
阿里Qwen团队发布 Qwen3-235B-A22B-Thinking-2507:深度推理能力再升级在持续三个月的优化后,阿里Qwen团队正式推出 Qwen3-235B-A22B-Thinking-2507 版本。该模型在逻辑推理、数学、科学、编程及学术任务上的表现显著提升,进一步巩固了其在开源思维...大语言模型# Qwen3-235B-A22B-Thinking-2507# 推理模型6个月前02550
谷歌推出Gemma系列最新模型Gemma 3,号称是全球最佳单加速器模型自首次推出以来,Gemma 模型已被下载超过 1 亿次,社区创造了超过 60,000 个适用于各种用例的变体。今天,谷歌正式发布 Gemma 3,这是 Gemma 开源模型家族中最强大、最先进的版本...大语言模型# Gemma 3# 多语言大语言模型# 大语言模型11个月前02540
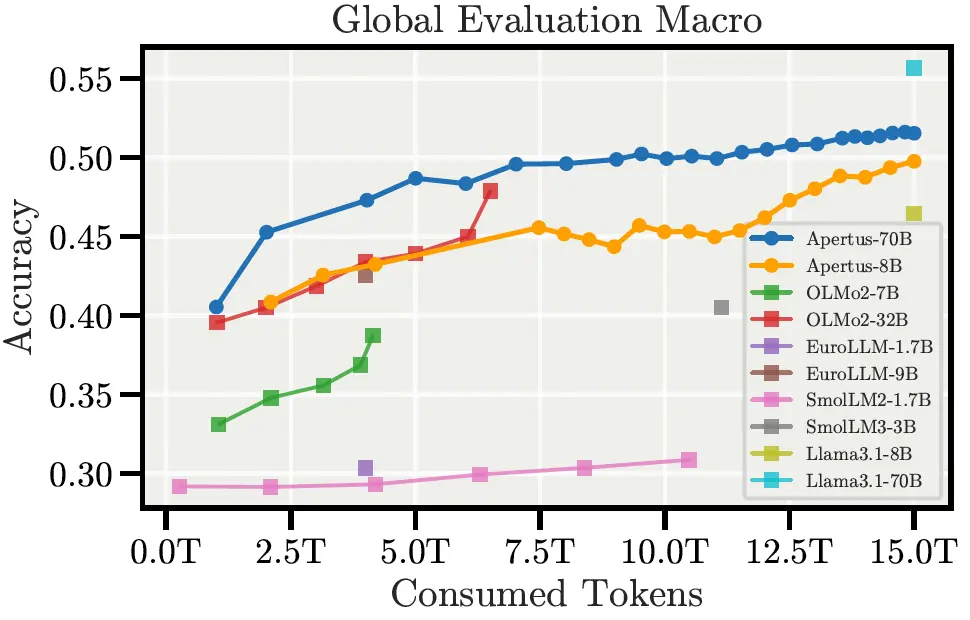
瑞士发布国家级开源大模型 Apertus,构建自主可控、合规透明的AI基础设施瑞士近日正式推出其国家级开源大语言模型 Apertus,标志着该国在构建自主可控、合规透明的人工智能基础设施方面迈出关键一步。 这一模型由 洛桑联邦理工学院(EPFL)、苏黎世联邦理工学院(ETH Z...大语言模型# Apertus# 开源大模型# 瑞士5个月前02510
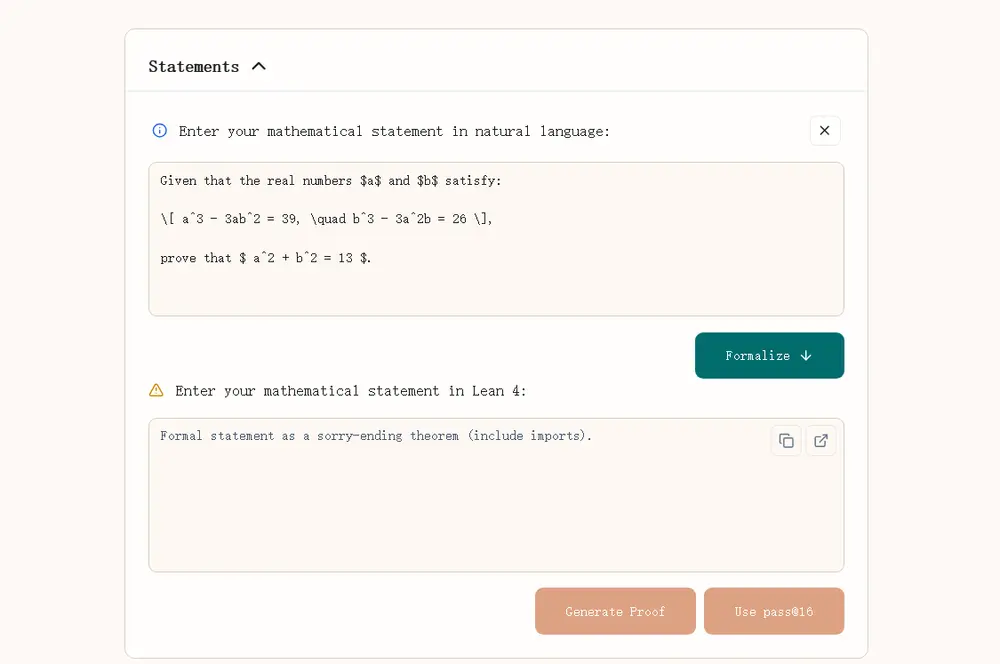
Kimina-Prover:首个实现人类级形式推理的大型定理证明模型由 Numina 与 Kimi 团队联合开发的 Kimina-Prover-72B 正式发布。这是目前在 Lean 4 形式化语言中,首个能够以接近人类方式推理并自动构建数学定理证明的大型神经定理证明...大语言模型# Kimina-Prover# 大型定理证明模型7个月前02500
英伟达推出小型语言模型 Nemotron-Nano-9B-V2:更小、更快、可控制“思考”的AI当AI模型不再一味追求“更大”,而是转向“更高效”时,小型语言模型(SLM)的时代正悄然到来。 继麻省理工学院衍生公司 Liquid AI 推出可在智能手表上运行的视觉模型、谷歌发布手机端运行的轻量级...大语言模型# Nemotron-Nano-9B-V2# 英伟达5个月前02450