由 Numina 与 Kimi 团队联合开发的 Kimina-Prover-72B 正式发布。这是目前在 Lean 4 形式化语言中,首个能够以接近人类方式推理并自动构建数学定理证明的大型神经定理证明系统。
- GitHub:https://github.com/MoonshotAI/Kimina-Prover-Preview
- 模型:https://huggingface.co/collections/AI-MO/kimina-prover-preview-67fb536b883d60e7ca25d7f9
- Demo:https://demo.projectnumina.ai
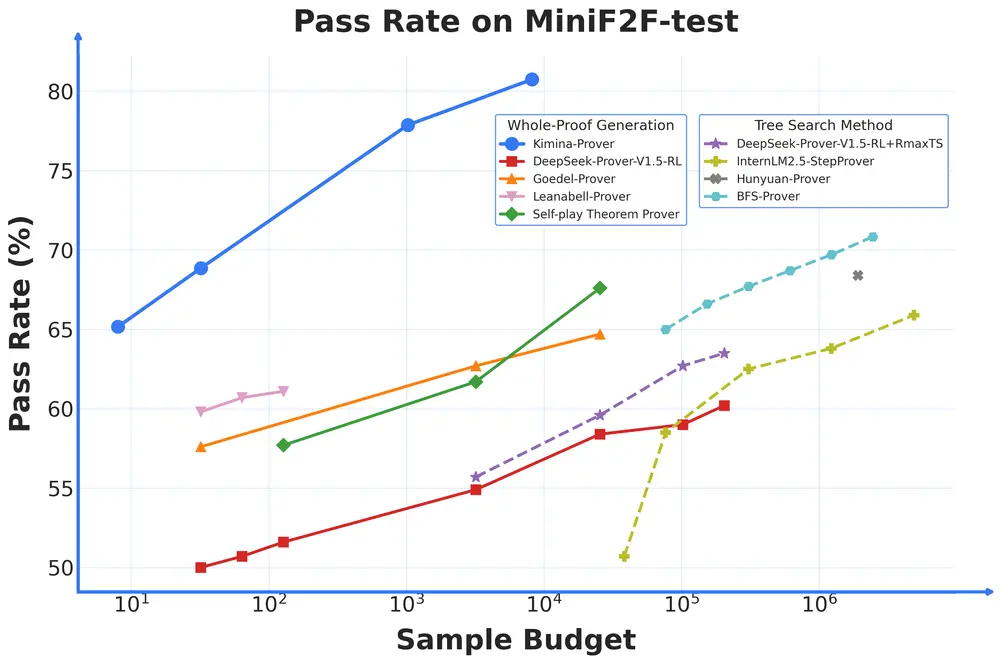
该模型在国际公认基准 miniF2F 上取得了突破性成绩,pass@32 达到 84.0% 的通过率,pass@1024 达 87.7%,并在引入完整的测试时强化学习(TTRL)搜索后,最终达到 92.2% 的最先进表现,远超此前所有公开模型。
核心功能一览
- ✅ 高样本效率:即使仅使用少量采样尝试(如 pass@8),也能保持高性能。
- ✅ 强大的错误修复能力:可读取 Lean 错误信息并提出针对性修正,显著提升生成成功率。
- ✅ 引理启用机制:支持模型识别和利用中间定理,模仿人类分步推理过程。
- ✅ 递归式 TTRL 搜索框架:通过自主发现、组合多个引理,实现复杂问题的深层推理。
- ✅ 开源共享:发布多个精炼模型(72B、8B、1.7B)、训练数据集、Lean Server 及修正版 miniF2F 测试集。
技术亮点解析
1. 测试时强化学习搜索(TTRL)
传统定理证明模型往往依赖单步推理,难以处理需要多阶段、长链条逻辑的问题。而 Kimina-Prover 引入了 TTRL(Test-Time Reinforcement Learning)搜索框架,使模型具备:
- 自主发现并重用中间引理;
- 构建结构化的证明路径;
- 动态选择最有潜力的引理组合进行推理。
这一机制大幅提升了模型对复杂问题的解决能力,使其推理深度和策略更接近人类数学家。
TTRL 的关键设计:
- 每个问题维护一个“搜索范围”,包含原始定理和候选引理;
- 使用引理得分筛选最具价值的中间定理;
- 采用探索与利用相结合的输入构造策略;
- 支持递归式子问题分解,扩展推理深度;
- 引入否定验证机制,防止因错误引理导致不健全的证明。
2. 强大的错误修复能力
过去大多数定理证明模型无法根据 Lean 的反馈信息调整输出,限制了其实用性。Kimina-Prover 则引入了一个专门的错误修复模块,包括:
- 基于 SFT 的错误修正数据集训练;
- 批量失败重放策略提升训练稳定性;
- 结合 Claude 3.7 sonnet 生成高质量错误解释链。
实验表明,在相同计算预算下,错误修复策略比暴力重试更具样本效率,显著提高了模型从失败中恢复的能力。
3. 高效的引理启用模式
为帮助模型有效利用中间定理,Kimina-Prover 在训练中引入了一种“引理启用模式”:
- 在问题上下文中前置一至三个形式引理;
- 使用偏好奖励引导模型优先使用有效引理;
- 最终模型学会有选择地调用引理,而非盲目堆叠。
训练后,引理使用率稳定在 30%-40%,展现了类人推理的高效性和战略性。
实验评估结果
| 模型名称 | pass@1 | pass@32 | pass@1024 |
|---|---|---|---|
| Kimina-Prover-1.7B | 46.7 | 73.4 | — |
| DSP+ | 52.5 | 71.3 | 80.7 |
| DeepSeek-Prover-V2-7B | 58.6 | 75.6 | 79.9 |
| Kimina-Prover-8B | 61.1 | 78.3 | — |
| DeepSeek-Prover-V2-671B | 61.9 | 82.4 | 86.6 |
| Kimina-Prover-72B | 63.9 | 84.0 | 87.7 |
在 miniF2F-test 上,Kimina-Prover-72B 不仅在 pass@32 和 pass@1024 上领先,还通过 TTRL 搜索将最终通过率提升至 92.2%,展现出当前最强的形式推理能力。
其他关键技术改进
📚 提示集整理与迭代
- 精选约 9 万个高质量提示问题,聚焦竞赛类数学任务;
- 动态过滤简单题项,保留挑战性内容;
- 开源提示集增强模型泛化能力。
🔁 Lean 数据持续预训练(CPT)
- 构建 60 亿 token 的 Lean 训练语料;
- 包含 GitHub 公共代码、编译器回滚日志等;
- 显著提升基础模型对 Lean 语法的理解能力。
🧩 随机证明裁剪增强
- 对已有证明进行截断或填充,模拟缺失步骤;
- 激发模型填补逻辑空缺的能力;
- 将人工注释证明更有效地融入训练流程。
🧮 非证明问题统一求解
- 支持答案生成与形式证明一体化推理;
- 在 CombiBench 类任务中表现优异;
- 实现数学直觉与形式验证的无缝衔接。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...